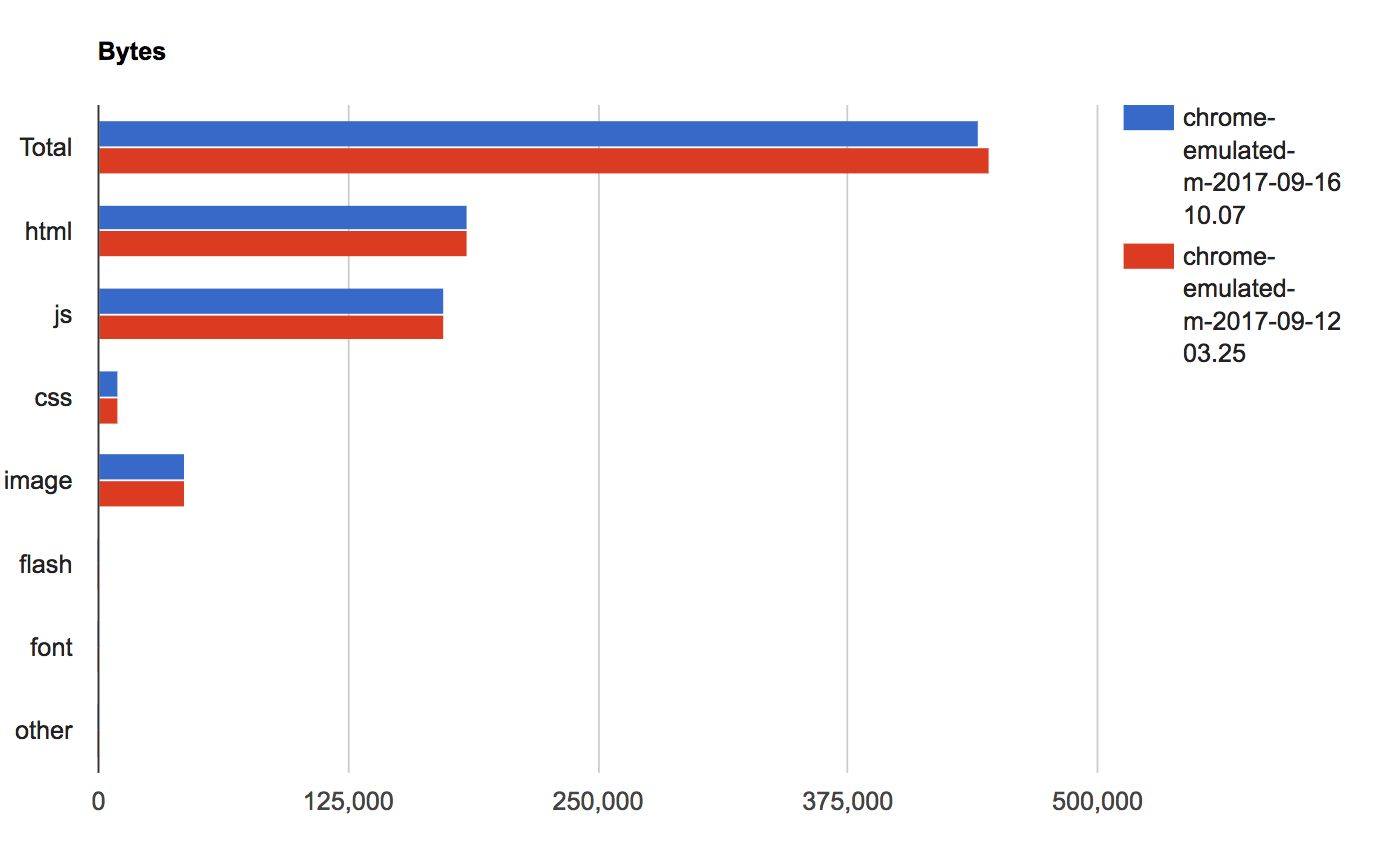
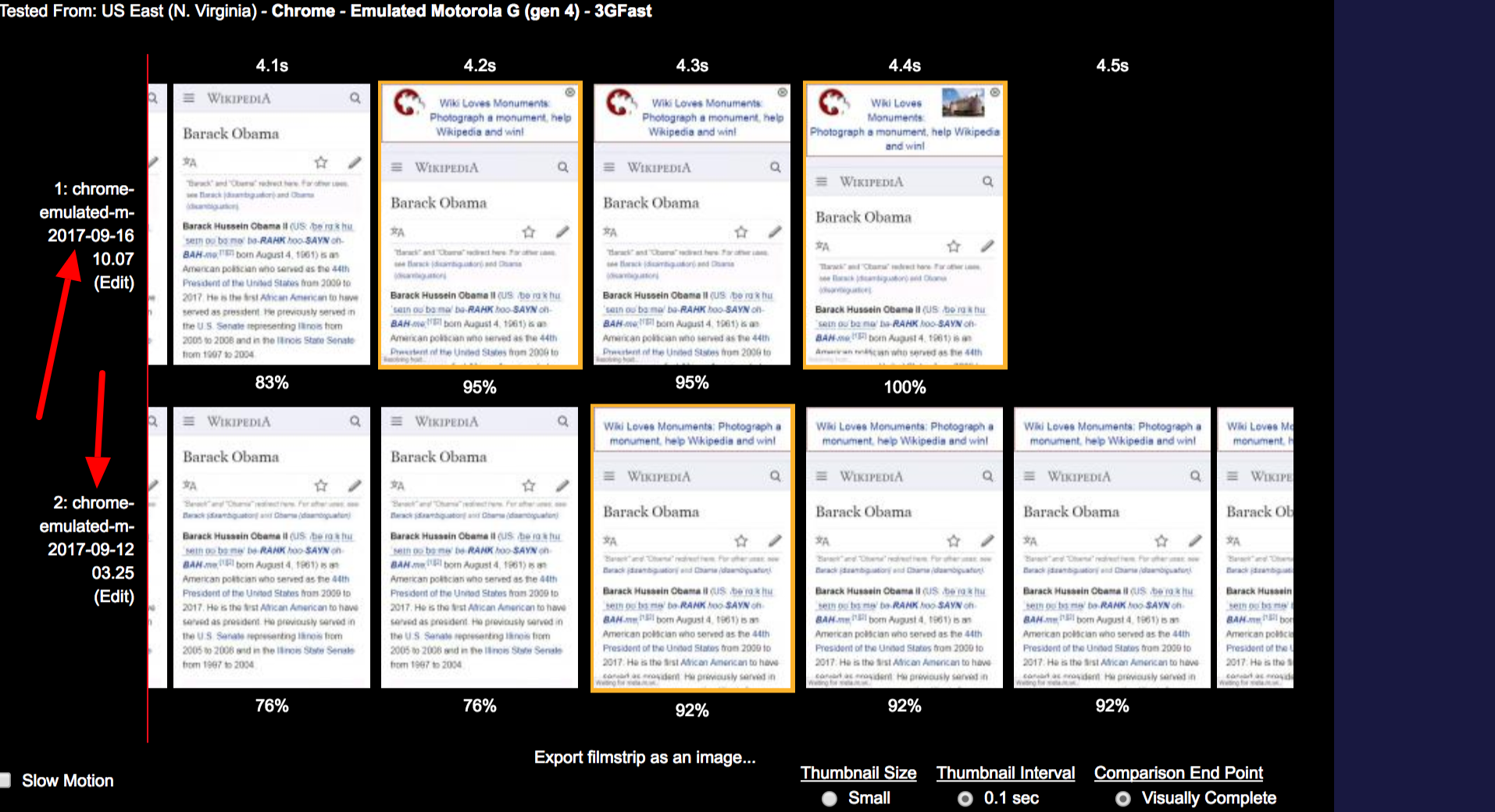
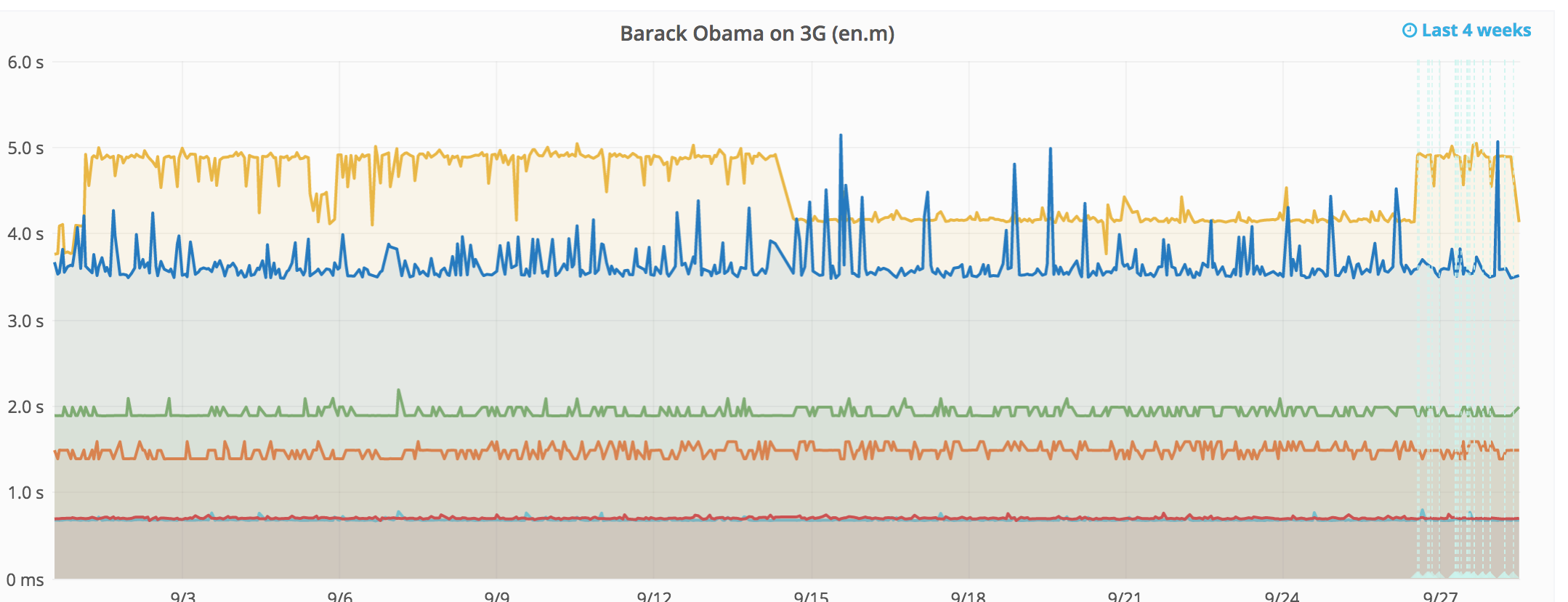
As of approximately 3am UTC, 1st of September, the fully loaded time for Barack Obama on enwiki using 3G slowed down 25% (from 4s to 5s)
- Dashboard graph
- Beta cluster doesn't exhibit the same behavior
- The content doesn't seem to have change substantially: diff
Is the slowdown caused by deployed software, or something else?