Last night we got paged for probe failures for Kubernetes apiserver in codfw:
01:35:41 <jinxer-wm> (ProbeDown) firing: (2) Service kubemaster2001:6443 has failed probes (http_codfw_kube_apiserver_ip4) #page - https://wikitech.wikimedia.org/wiki/Runbook#kubemaster2001:6443 - https://grafana.wikimedia.org/d/O0nHhdhnz/network-probes-overview?var-job=probes/custom&var-module=All - https://alerts.wikimedia.org/?q=alertname%3DProbeDown
It turns out the apiserver on kubemaster2001 restarted at 00:53, and again at 01:33:
Mar 01 00:53:35 kubemaster2001 systemd[1]: kube-apiserver.service: Succeeded. Mar 01 00:53:35 kubemaster2001 systemd[1]: Stopped Kubernetes API Server. Mar 01 00:53:35 kubemaster2001 systemd[1]: kube-apiserver.service: Consumed 1w 4d 11h 55min 22.441s CPU time. Mar 01 00:53:35 kubemaster2001 systemd[1]: Starting Kubernetes API Server...
The same happened on kubemaster2002 at 00:52, and again at 01:34.
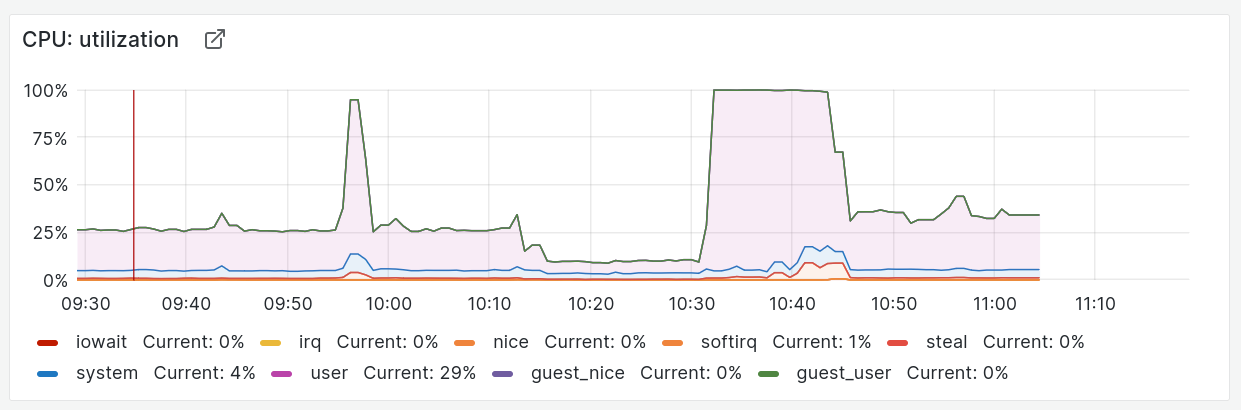
We lost probes on both hosts both times, but it only paged the second time: https://grafana.wikimedia.org/goto/_YP4RkASz?orgId=1
It shows up in the resource graphs: https://grafana.wikimedia.org/goto/by8I-qTSz?orgId=1
@Clement_Goubert identified this as a Puppet cert renewal, which makes sense: https://puppetboard.wikimedia.org/report/kubemaster2001.codfw.wmnet/5a536b70ffe6b5d7b7d0c62ddde739b101a4bc25 But Puppet ran on kubemaster2001 at 00:51, and on kubemaster2002 at 01:31, so it looks like we restarted both servers both times -- that might be an effect of coordinating a rolling restart to minimize leader elections, but doing the rolling restart twice might be a bug; I haven't dug into it yet.
So, questions:
- Is the 2x2 restart expected?
- Of course starting up the apiserver is expensive. Is it expected to lock up for so long that probes fail?
- If not, should we do something about that?
- If so, should we bump the alert thresholds so it doesn't page?
- Did the rolling restart succeed in avoiding any actual API unavailability (because the elected leader was always serving)?
- If so, nothing was actually wrong -- should we only alert on the API service, and not on individual machines?