This is to discuss/debate all the related things, otherwise it's only being touched on in IRC. To visually be clear about what we're talking about, in this diagram...
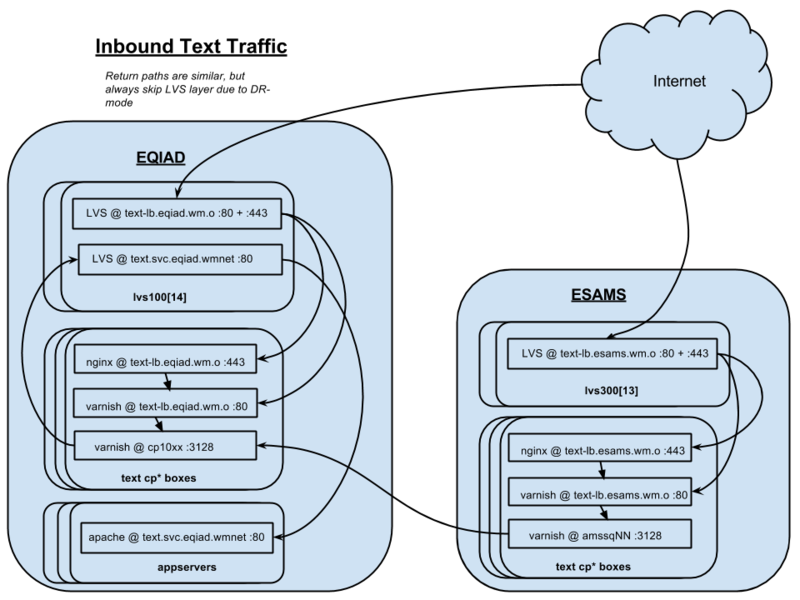
... We're talking about the part where varnish @ cp10xx :3128 connects back up through LVS @ text.svc.eqiad.wmnet:80 in order to reach the cluster of underlying apaches.
Varnish does have the capability to have raw backend server lists itself (which we use for varnish<->varnish connectivity now), so skipping the internal LVS layer *is* an option we can discuss. Assuming everything else in today's functional picture stays the same, I see the pros and cons of using LVS here like this:
- Pros:
- Pybal might be a little better at healthcheck response time for dead-server depooling
- It makes failure of the internal LVS service (at the ipvs/pybal level) considerably less subtle, since it's servicing all the external uncached requests, too
- One less place to define and monitor lists of servers (just in pybal, instead of pybal for the internal service endpoint and separately in varnish for the externally-generated traffic)
- Cons:
- Inbound side of traffic has an extra pair of local jumps through our network infrastructure and a server, which add some tiny latency.
- It's confusing in engineering discussions that our external traffic, if not answered directly from cache, loops through the LVS clusters a second time, so there's some question of which LVS layer we're even talking about at various points.
Basically, the Pros in that list win right now, IMHO. There are two new complications in this mix now, though:
- Interdatacenter Traffic Security for codfw<->eqiad traffic - Varnish can't directly talk HTTPS to a backend. The only way we have to secure that traffic currently is with IPSec. We've fixed this for the t2-cache<->t1-cache case, but when we start bringing tier1 caching online in codfw, we want codfw varnishes talking to eqiad app services directly. If that traffic routes through LVS, we can't IPSec it. If it went direct, we could do IPSec in theory (although it adds a ton more hosts to the IPSec peer lists. ~500 in eqiad?).
- In a similar vein, I'd really like to start having "pass" traffic avoid jumping through extra hoops. There's no need for restbase or uncacheable auth requests, etc to jump from e.g. esams-frontend to esams-backend to eqiad-backend to appservers. Once esams-frontend has classified the traffic as uncacheable, it could send it directly to the eqiad appservers. We could even do similar dynamic schemes with hit-for-pass traffic as well (as in, request initially flows through all backend layers, but hit-for-pass object based on response headers causes selection of the direct-path backend for followup requests until hit-for-pass expires). Right now we could at best skip one excess layer and have esams-fe contact eqiad-be directly for pass traffic, but we can't skip eqiad-be because the next layer is LVS-routing, and thus no IPSec, so the traffic would be back in the clear...
Honestly, I'm not even sure yet that we want to go down the road of putting all of mw* under ipsec roles with various cluster breakouts and associations to caches, etc. I have a bad feeling that may grow the association list sizes too huge for IPSec to handle it well. But right now I don't have a solid better option to pursue yet for not sending eqiad<->codfw cache traffic or direct-pass traffic in the clear, either.
We could also look at something crazy like putting a local outbound-HTTPS proxy on each cache machine that varnish uses to contact backends over HTTPS, as hack for the varnish codebase's lack of outbound HTTPS support. Then LVS wouldn't be part of the problem here anymore. Of course we don't have HTTPS on the apaches yet anyways, but that's something we could sort out using our local CA...