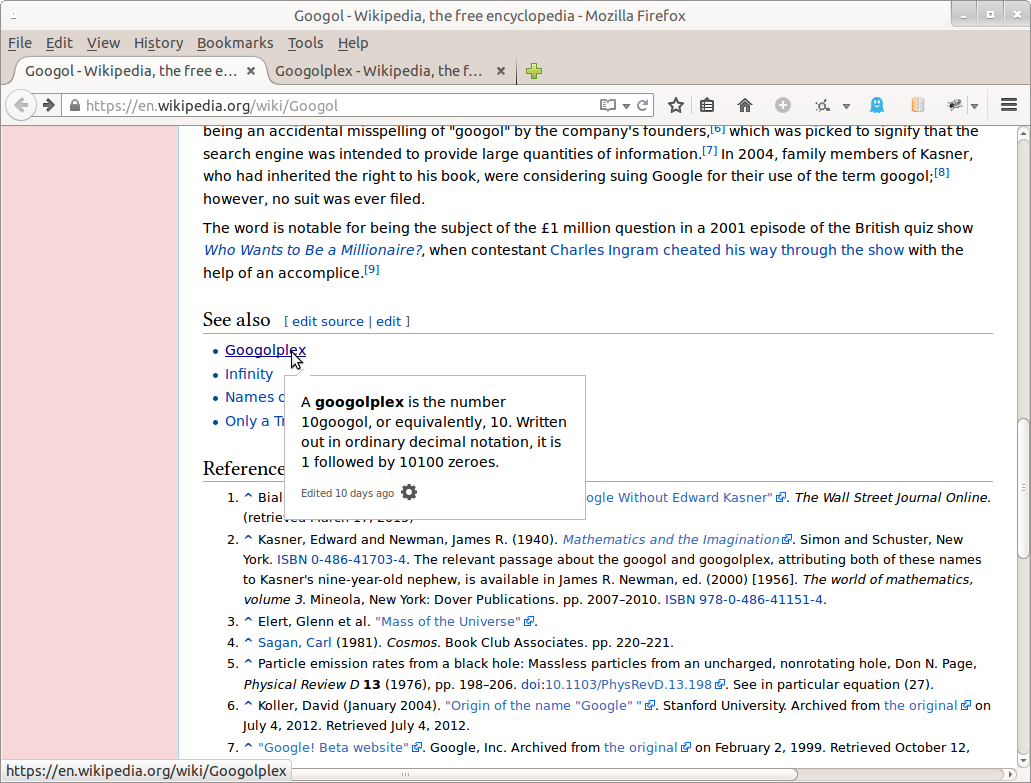
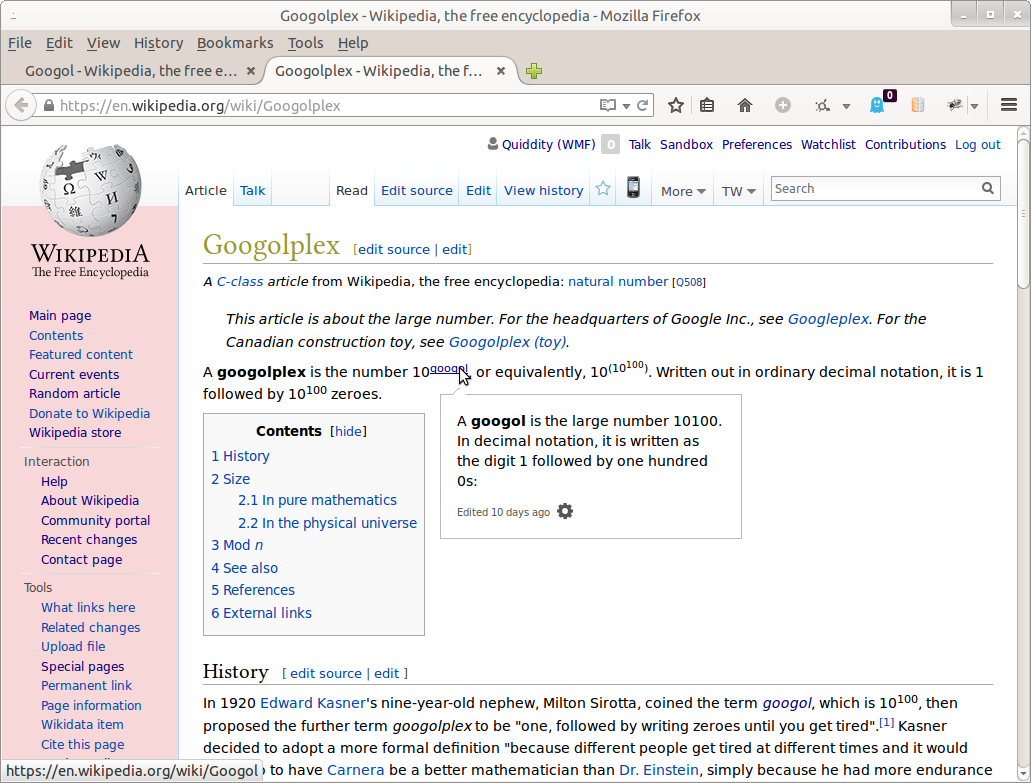
The articles w:en:Googol and w:en:Googolplex include a <sup>foo</sup> string, which is not correctly displayed in Hovercards.
| Quiddity | |
| Sep 10 2015, 6:05 PM |
| F2565927: Screenshot from 2015-09-10 11:01:21.png | |
| Sep 10 2015, 6:05 PM |
| F2565926: Screenshot from 2015-09-10 11:01:40.png | |
| Sep 10 2015, 6:05 PM |
The articles w:en:Googol and w:en:Googolplex include a <sup>foo</sup> string, which is not correctly displayed in Hovercards.
Hovercards makes a request for https://en.wikipedia.org/w/api.php?action=query&format=json&prop=extracts%7Cpageimages%7Crevisions&formatversion=2&redirects=true&exintro=true&exsentences=5&explaintext=true&piprop=thumbnail&pithumbsize=300&rvprop=timestamp&titles=Googol&smaxage=300&maxage=300&uselang=content
The directive explaintext tells TextExtracts to return extracts as plain text instead of limited HTML... so this is doing exactly what it should. Hovercards should probably request HTML.
What would be the implications of doing this? Are there elements known to be in the initial excerpt that are sure to mess up the Hovercard?
Potentially. We'd need to explore it. I'd expect that we'd need to parse the output into a DOM tree and whitelist only a few images e.g. p tags, sub, and sup.
I'd suggest to implement this we'd try a different mode e.g. explainhtmlsubset and test out on mobile first.
Related to (loading plain text instead of HTML):
should we track tasks like this under one task?