Description: https://meta.wikimedia.org/wiki/Objective_Revision_Evaluation_Service
Timeline: We're hoping to deploy by the end of Nov.
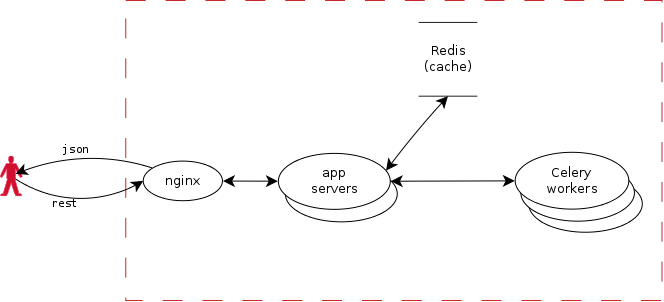
Diagram:
Technologies: python(flask, sklearn, celery), redis
Point person: Aaron Halfaker (@Halfak)
The diagram above depicts a common request flow that comes from the user's browser.
- nginx load balancer
- two web app servers
- if the score is cached in redis, return that
- if the score is not cached in redis, use celery cluster to generate it and store the score in redis.
The only modification that a user can perform is to request that a score be generated and cached. Otherwise the service is read-only.