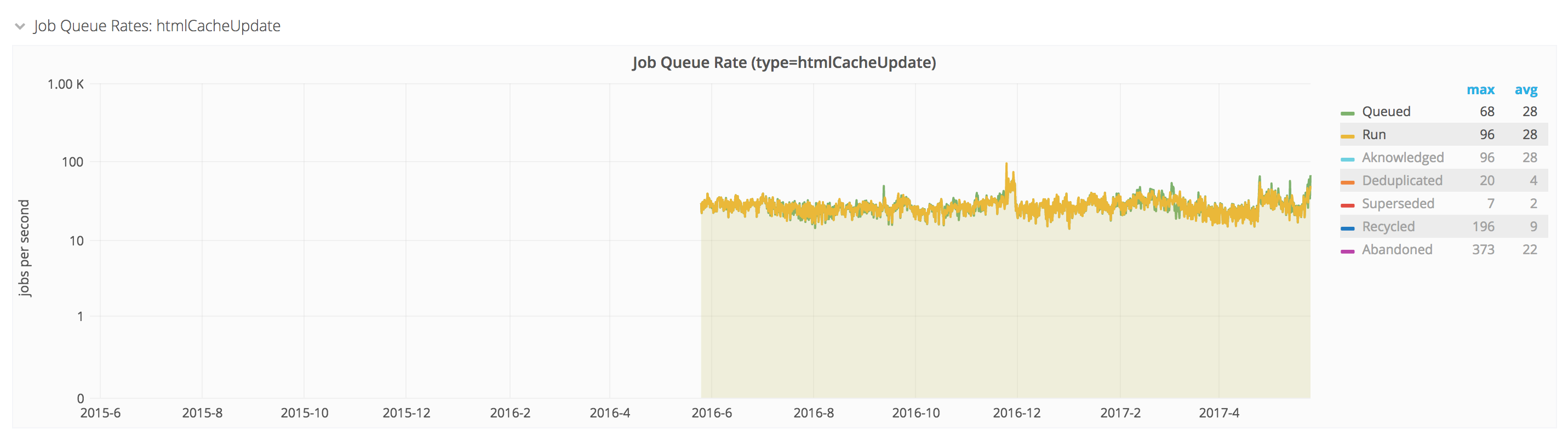
tl;dr - What are the causes for the multiple steps of massive rate increase in the insertion of htmlCacheUpdate jobs shown here? http://graphite.wikimedia.org/render/?width=586&height=308&_salt=1453466175.547&target=MediaWiki.jobqueue.inserts_actual.htmlCacheUpdate.rate&from=-180days
Known background:
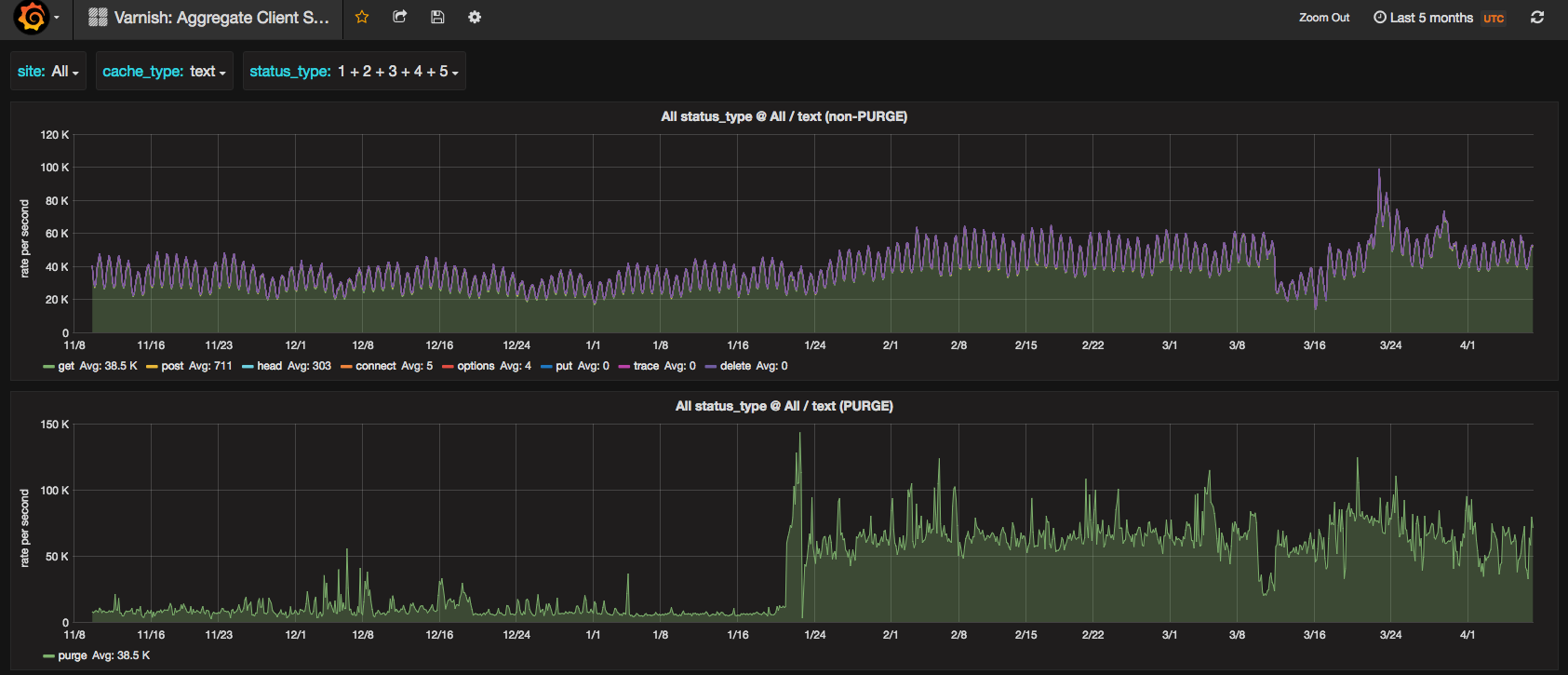
- Grafana shows massive increase in PURGE methods hitting varnishes starting circa 02:00 UTC on Jan 21: https://grafana.wikimedia.org/dashboard/db/varnish-aggregate-client-status-codes?from=1453148402001&to=1453463631092&var-site=All&var-cache_type=All&var-status_type=1&var-status_type=2&var-status_type=3&var-status_type=4&var-status_type=5&theme=dark
- Seems to correlate with T123815 + T124194#1951071 , which is when a job backlogging/throttling issue was "fixed" by making a separate runner for htmlCacheUpdate, which opened the floodgates on those jobs generating cache purges.
- But that leaves the question: when did it start piling up in the job queues in the first place and why? Which leads back to the graph linked at the top showing significant and seemingly permanent rate bumps in htmlCacheUpdate job inserts circa Dec 4, Dec 11, and then Jan 20.