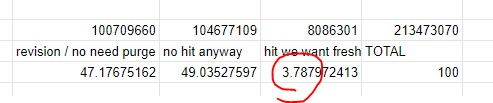
When an entity is edited users expect the data they get via Special:EntityData to change as well. We need to purge the caches there after an edit.
The approach that was decided during the task inspection was to "just not cache these specific page requests" T128486#6376066
Questions from story time:
How quickly do we want Special:EntityData to have the latest data
- As close to immediately as possible without making it a month long project.
Is this specific for JSON only?
- JSON is the most important on (that people talk about the most), but all formats would be good
Is this for all users to just the user that made the edit?
- All users
Points:
- This task only talks about calls to this page that do not specify a concrete revision ID
- Task inspection fnotes rom 11 August 2020 T128486#6376066