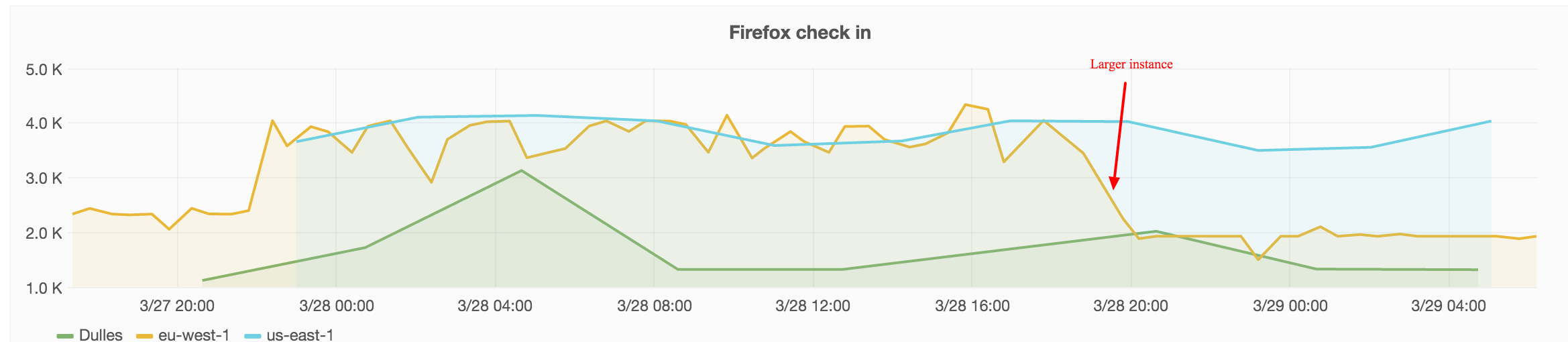
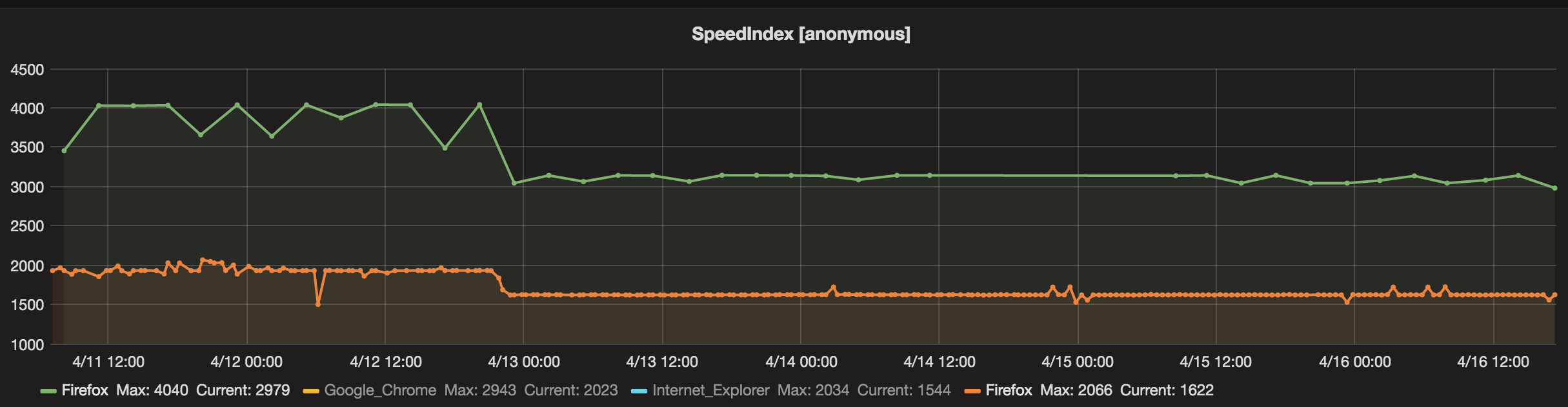
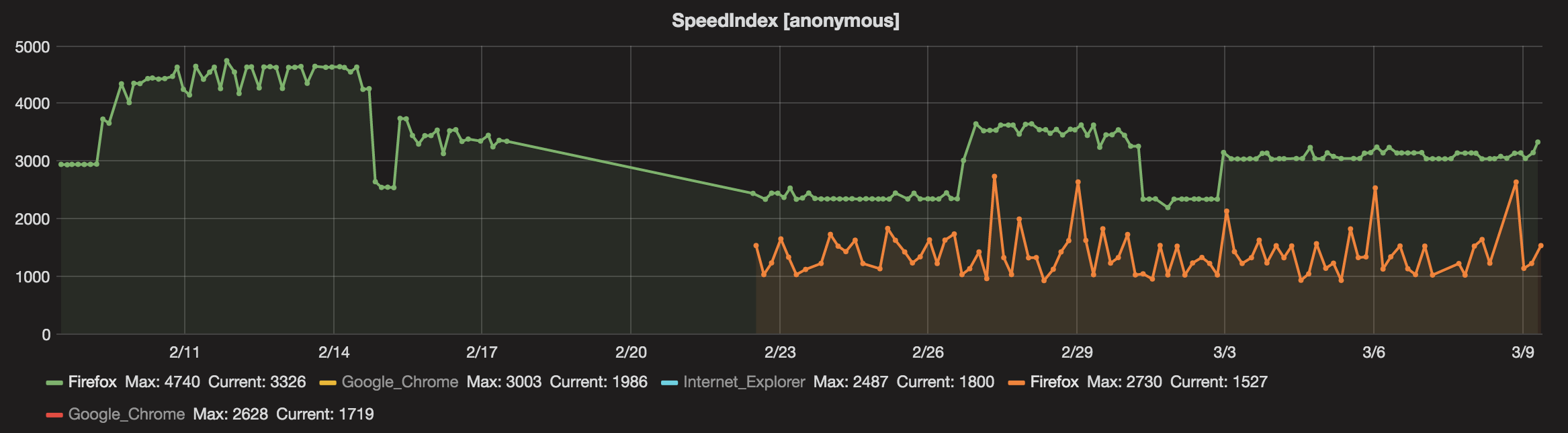
We test the Facebook page on Firefox both on out own instance and on WebPageTest.org. The green lines are from our own instance and the orange is on WebPageTest:
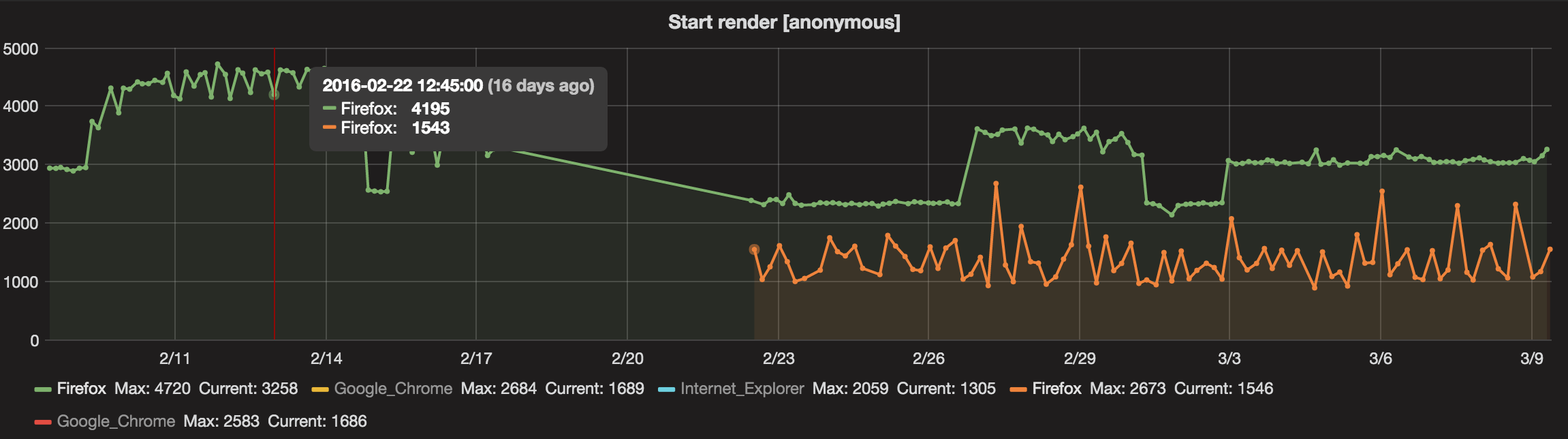
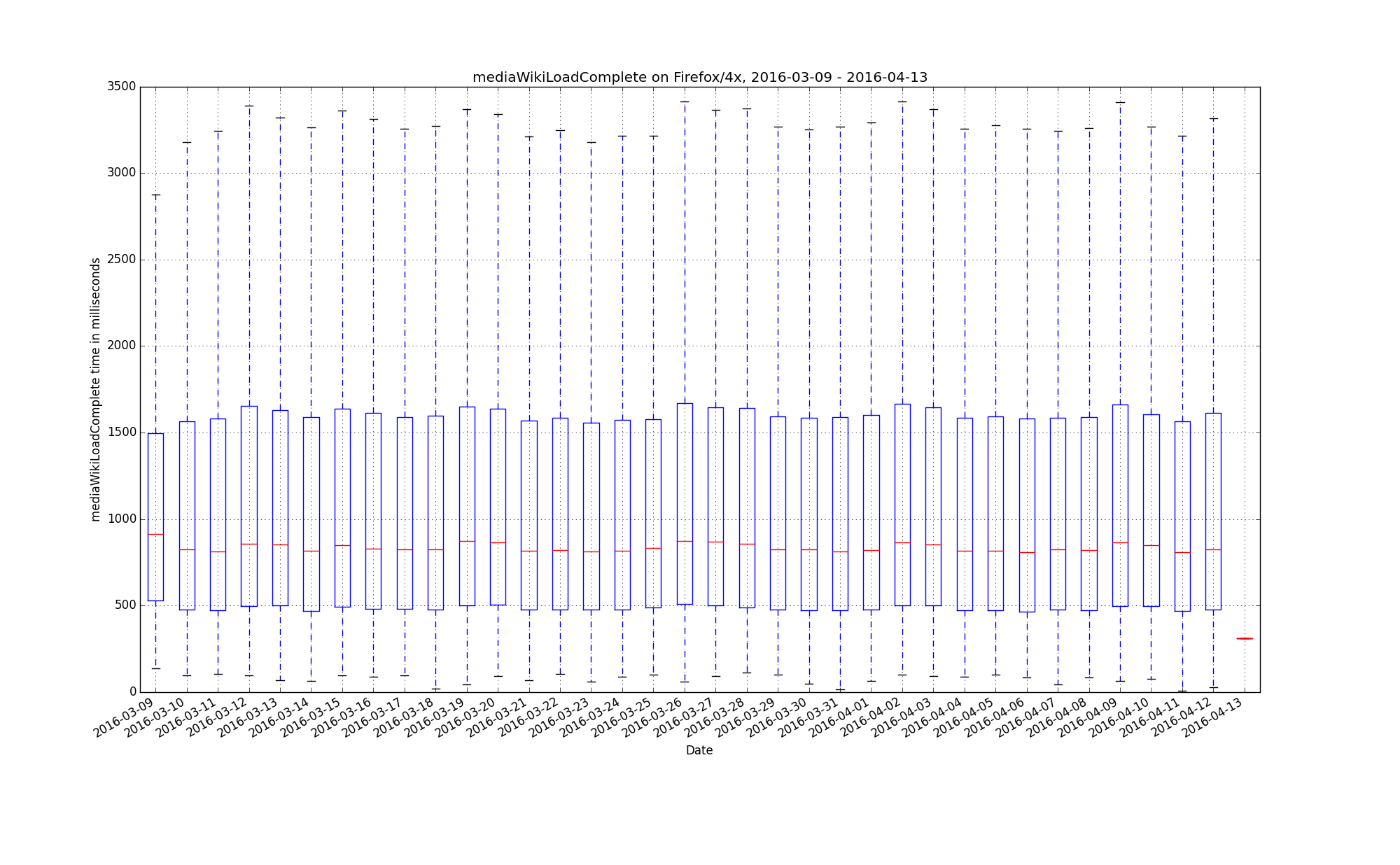
On our local instance the metrics are pretty stable but sometimes they increase with almost 1 second and stays that way for some time. I want to know that these jumps really reflects the page being slower and not something that happens on our WPT server (and I hoped testing using WPT.org would help us with that).
It's hard to say that the numbers from WPT.org shows us the same picture. When we run on WebPageTest.org we don't specify exactly which server that will run the test, that can make the metrics differ between runs.
The first step should be to check that we runs the tests the exact same way on WPT.org and our own server.