Stats: http://labels.wmflabs.org/stats/viwiki/26
- Announce the campaign
- Status update no. 1
- Status update no. 2
- File task for building models based on labeled data.
| Halfak | |
| Mar 17 2016, 8:47 PM |
| F34455397: many-error.png | |
| May 15 2021, 9:40 PM |
| F34455401: one-error.png | |
| May 15 2021, 9:40 PM |
| F34455407: a-bot-use-AWB.png | |
| May 15 2021, 9:40 PM |
| F34455404: alphama-bot.png | |
| May 15 2021, 9:40 PM |
Stats: http://labels.wmflabs.org/stats/viwiki/26
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Resolved | None | T130213 [Epic] Edit quality models (damaging/goodfaith) | |||
| Open | None | T130300 Deploy edit quality models for viwiki | |||
| Open | None | T130273 Complete viwiki edit quality campaign |
Hello developers of ORES and Wiki labels.
After 6 years of launching the viwiki edit quality campaign, the Vietnamese Wikipedia community has completed this campaign. The result is:
Labels done: 4916
Labels needed: 5000
→ 98% done.
Link: https://labels.wmflabs.org/stats/viwiki/26
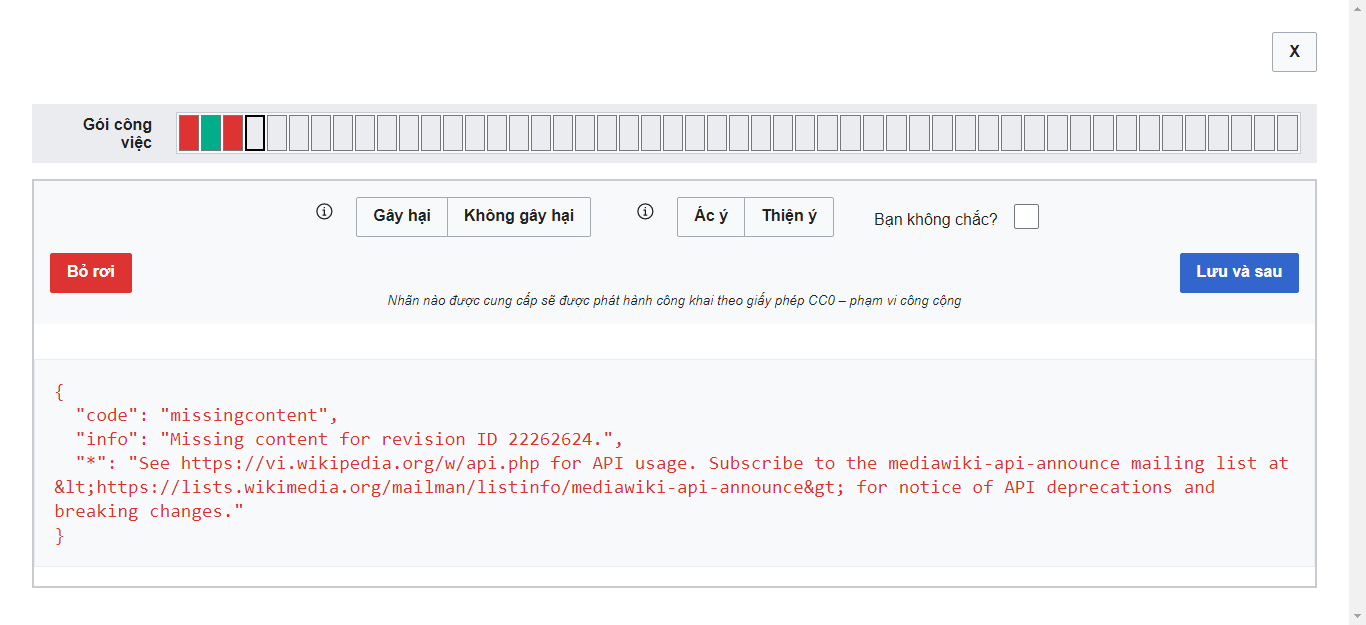
The final labels of the campaign encountered an error as shown below. Therefore, the remaining 2% is probably not very important.
The campaign has been completed, but as a labeler, I feel that this dataset is probably not good enough. A few reasons:
Reason 1. Too many edits in Wiki labels are bot edits. See the proofs below.
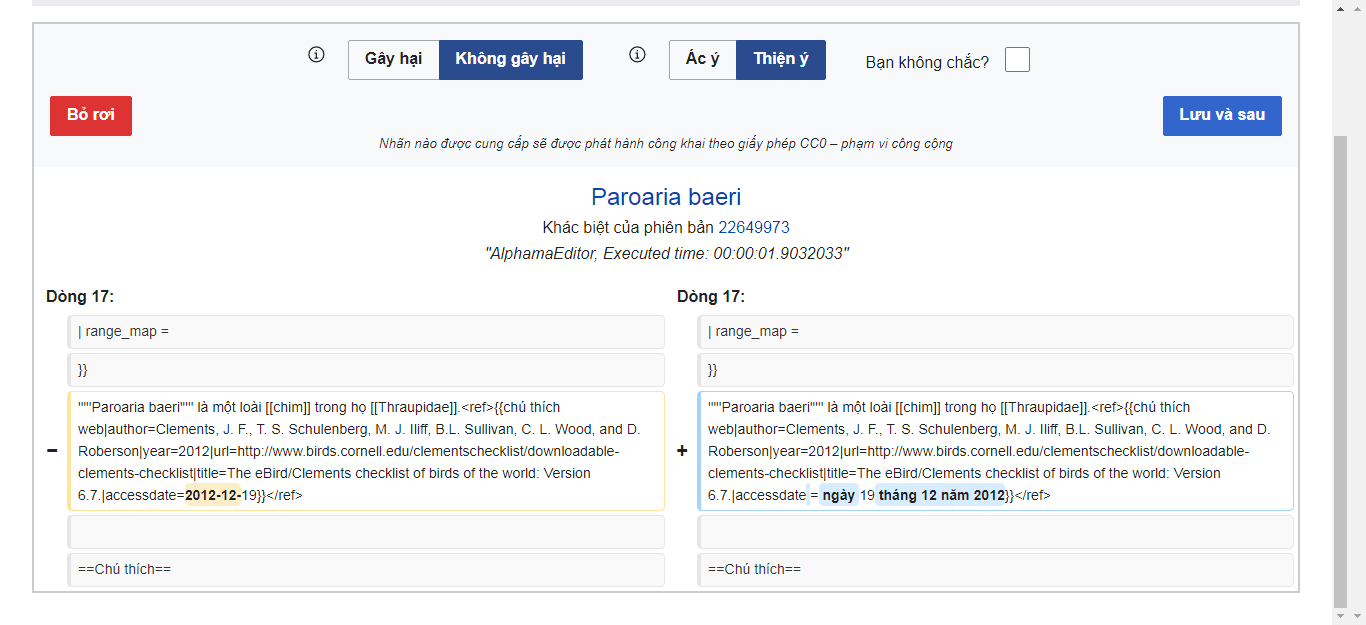
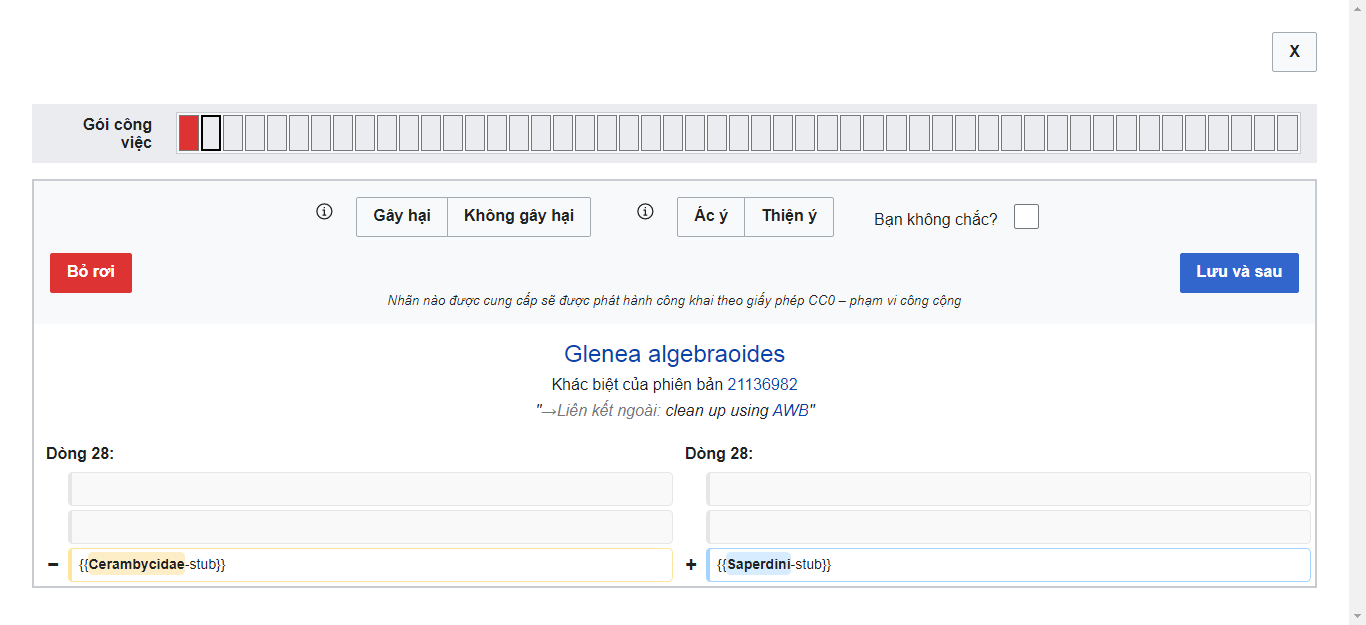
Reason 2. Looks like there are too few damage edits. When I labelled about 100 edits, there were only about 0-5 damage edits.
Therefore, I think this dataset is not good enough for using in the real world. Especially because there are so many bot edits.
So, I suggest increasing the number of edits for the campaign (about 10,000 → 20,000 edits) and should not have bot edits anymore. It is advisable to label edits made by real users and IPs, rather than bots.
I'm not good at English and machine learning, so my views may not be accurate.
Hoping to get feedback from the developers.
Best regards.
Nice work! There should not have been bot edits in the dataset. But this dataset is very very old so I wonder if that is why some snuck in. I wonder if maybe some of those bots aren't using the bot flag? We usually don't filter by username when generating the dataset, but that's an option.
I did a bit of digging (see [1]) and it looks like at least the AWB bot is currently flagged as a bot. It's possible that the bot flag on that account is more recent than when we generated the sample, but either way, it seems wrong.
I propose that we try building a model with what we have now and in parallel we can generate a new sample with the more recent code we have for autolabeling. We should be able to tell whether or not the model based on currently available data is useful. I'm sure that any more labeling work will make the model even better and more relevant.
@Halfak knows far more than me about the implications of using old datasets for training, but +1 to building a model and see how well it works before we spend the time gathering additional data.
Since some bots have flood flag (not bot flag), the old dataset had their edits. Bots on viwiki are often named with the suffix "bot" or "AWB".
I agree with Halfak's proposal: Building a model with currently available data and check its usefulness.
But in my opinion, I think this dataset has too many bot edits (50-70%), so it's possible that the dataset doesn't accurately reflect the activity of viwiki community.
If the dataset isn't useful, I hope you can help to create a new similar campaign, without bot edits.
Thank you!