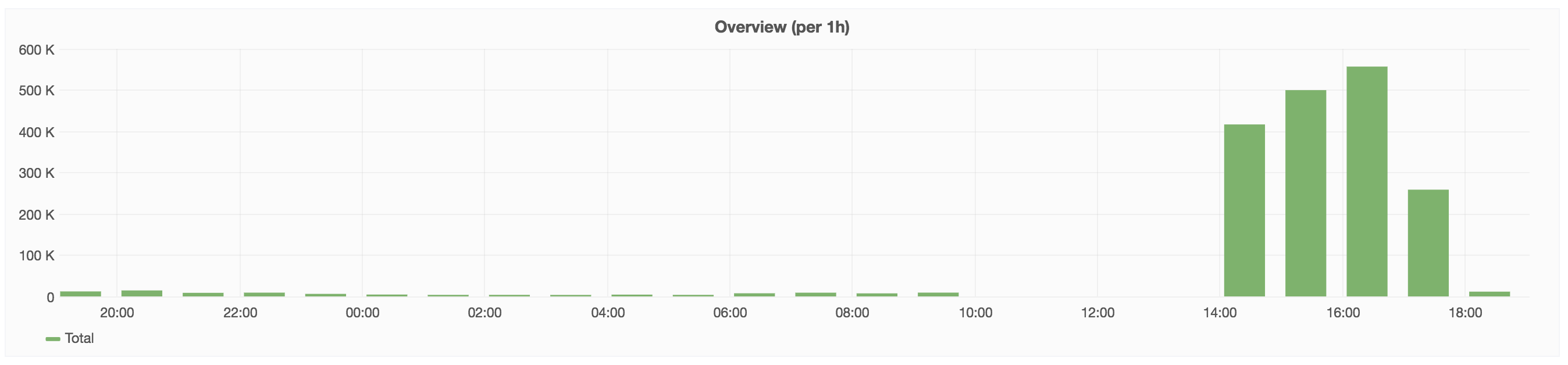
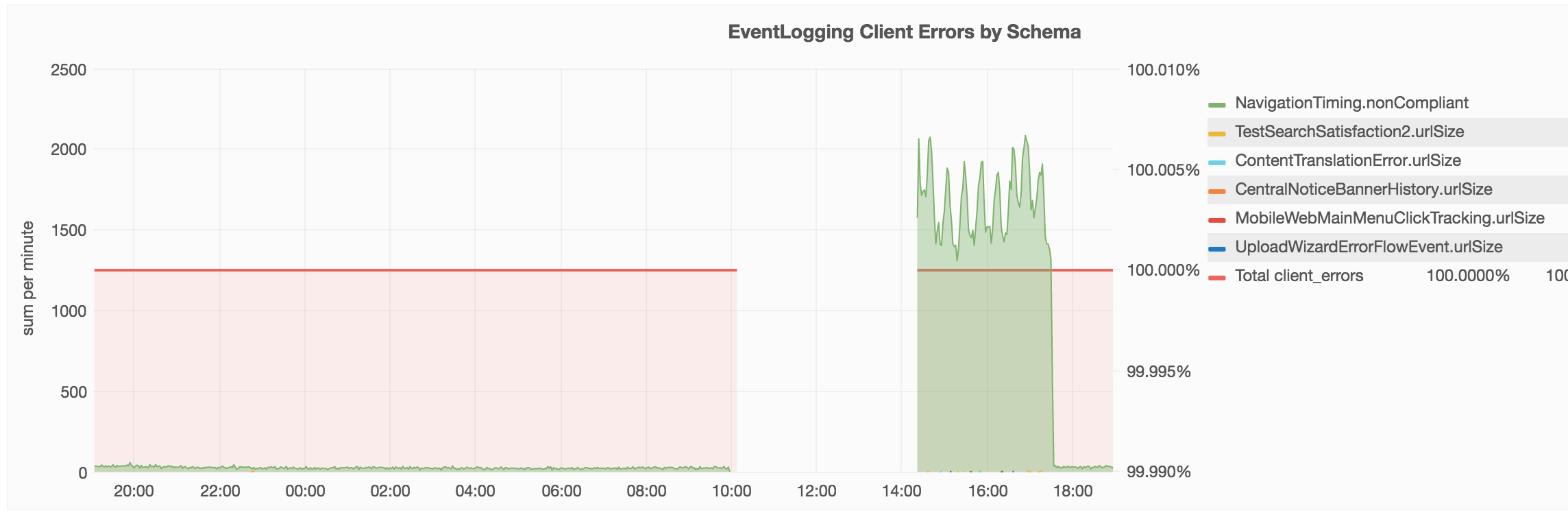
it looks like this event has been UNKNOWN for the last 80d in icinga, likely the metric has disappeared/been renamed, @Ottomata
perhaps?
monitoring::graphite_threshold { 'eventlogging_NavigationTiming_throughput':
description => 'Throughput of EventLogging NavigationTiming events',
metric => "kafka.${kafka_brokers_graphite_wildcard}.kafka.server.BrokerTopicMetrics.MessagesInPerSec.eventlogging_NavigationTiming.OneMinuteRate",
warning => 1,
critical => 0,
percentage => 15, # At least 3 of the 15 readings
from => '15min',
contact_group => 'analytics',
under => true
}