I'm hearing from others that Cassandra's default (calculated) value for memtable_cleanup_threshold is a bit too aggressive (too low), resulting in overly frequent flushing of the largest tables, higher disk IO, and a larger number (of smaller) SSTables, (which in turn creates more compaction activity). I believe this is true for us as well; Our calculated threshold in the RESTBase cluster is only 33% (which does strikes me as quite low).
One side-effect of more frequent memtable flushing is a higher demand for memtable flush writers, and the following plot of pending memtable flush writer jobs would seem to indicate that there is some room for improvement.
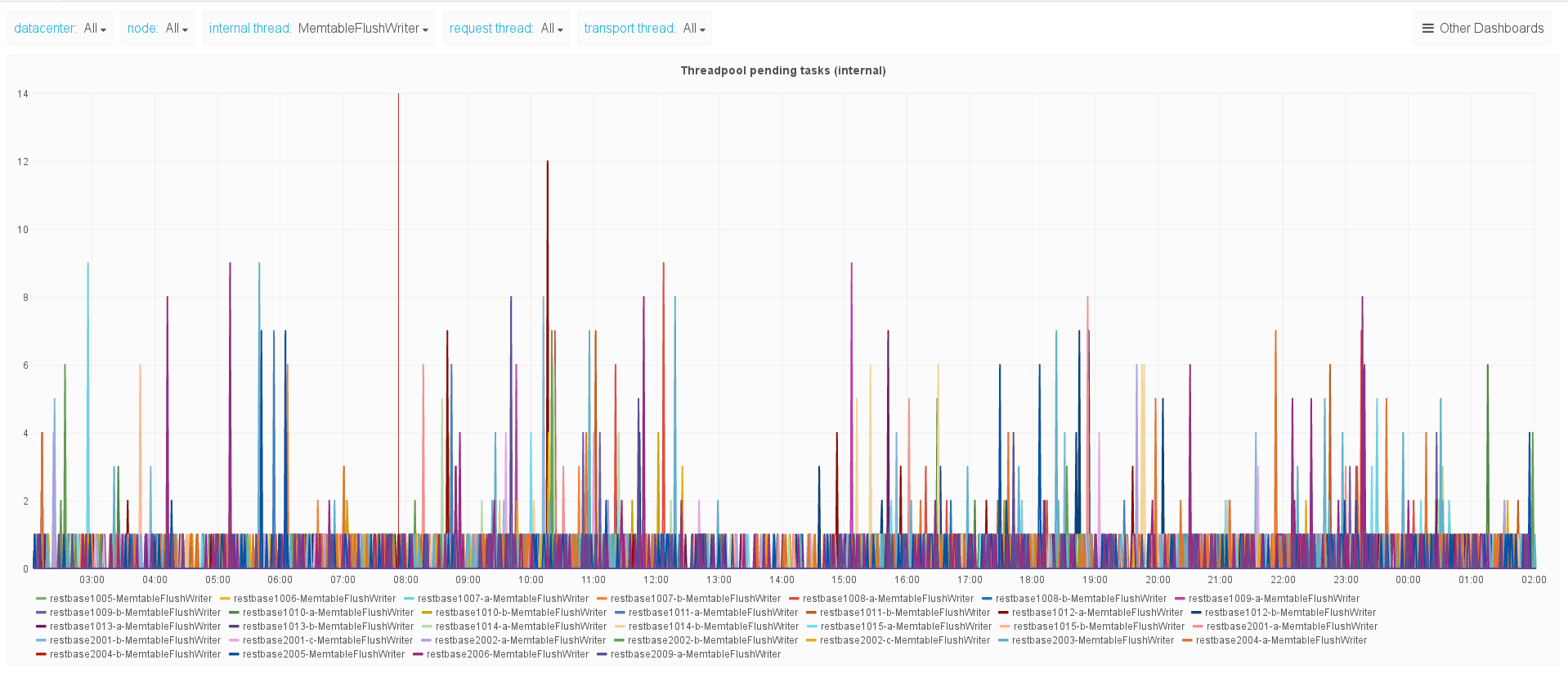
I propose some limited single node experiments of higher values, while monitoring flush frequency, and memtable flush writer pending tasks.