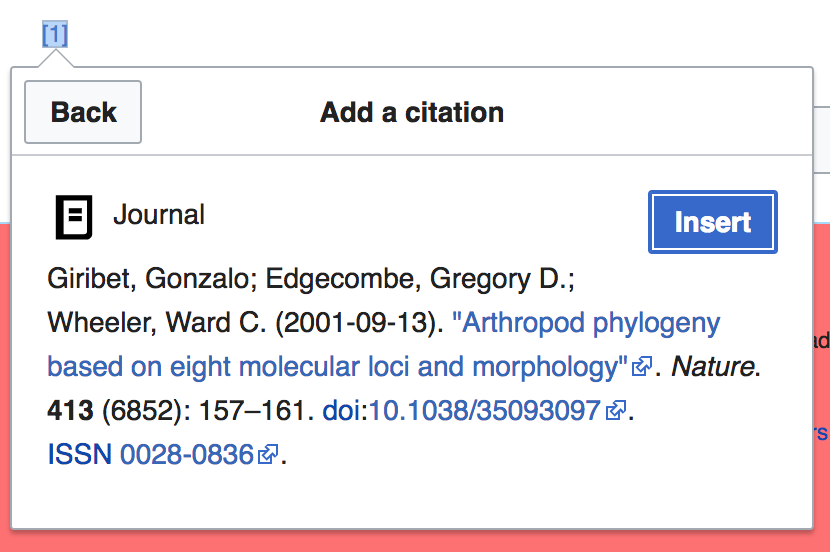
This is a problem for following all nature.com DOIs. which link to an intermediate doi resolver - instead of giving us a redirect, these pages give us 401s. We can use crossRef metadata, but in some cases this metadata is incomplete. i.e. http://www.nature.com/doifinder/10.1038/35093097 which has a missing title.
We are also unable to scrape the page, meaning we are unable to supply the title directly from the page either.
The actual response from the page includes the metadata we want, but we have a policy of not including metadata from non-200 status resources (since these are usually bad).
However, the headers do have the correct content-location- but we can't be certain that in general, the content-location is good, because it could be the location of an error page.
Zotero is able to handle these links when directly given the final url.