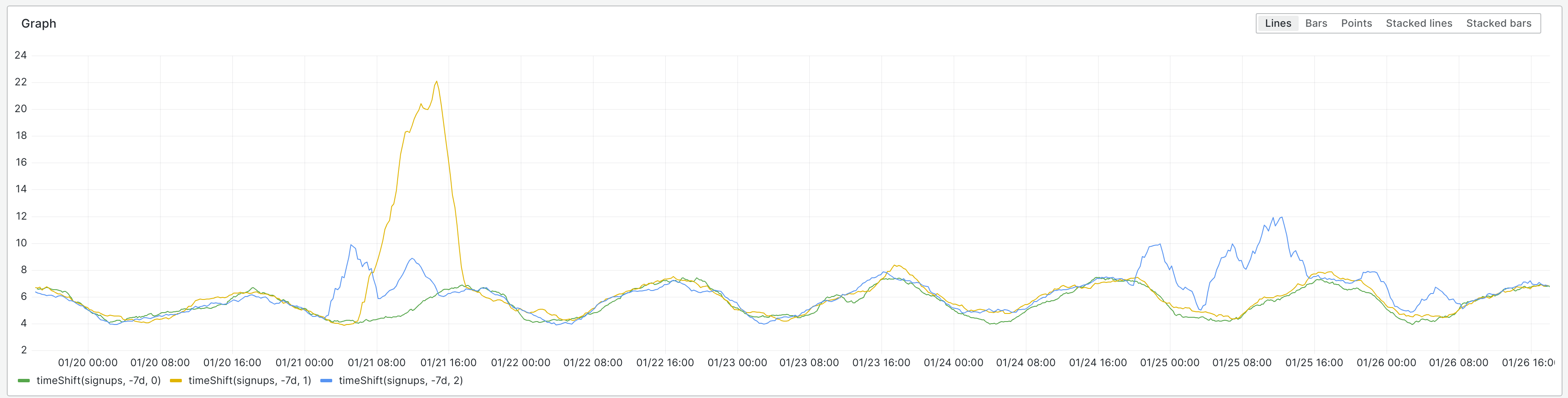
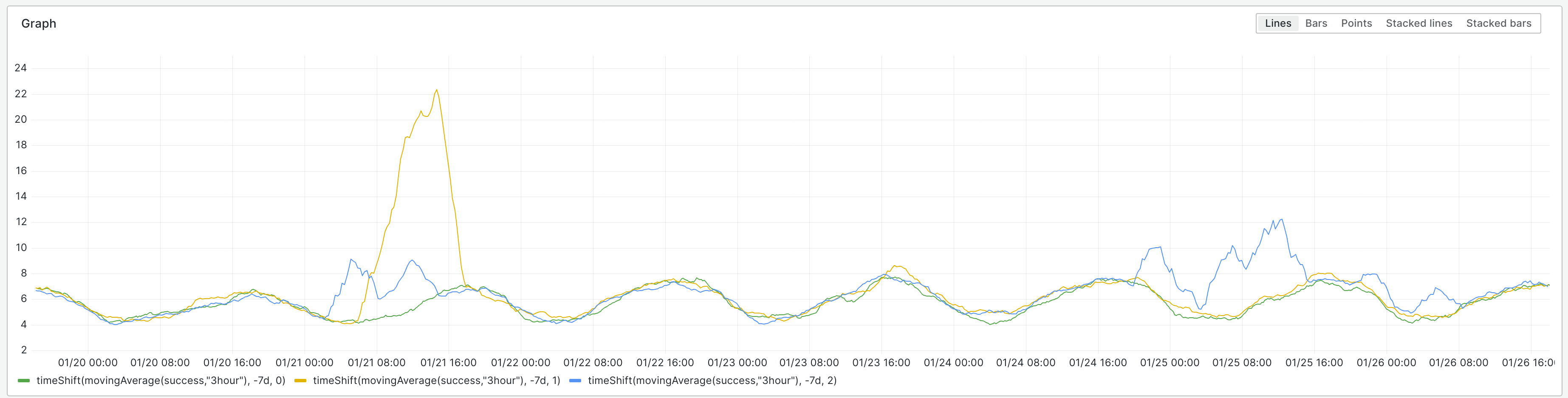
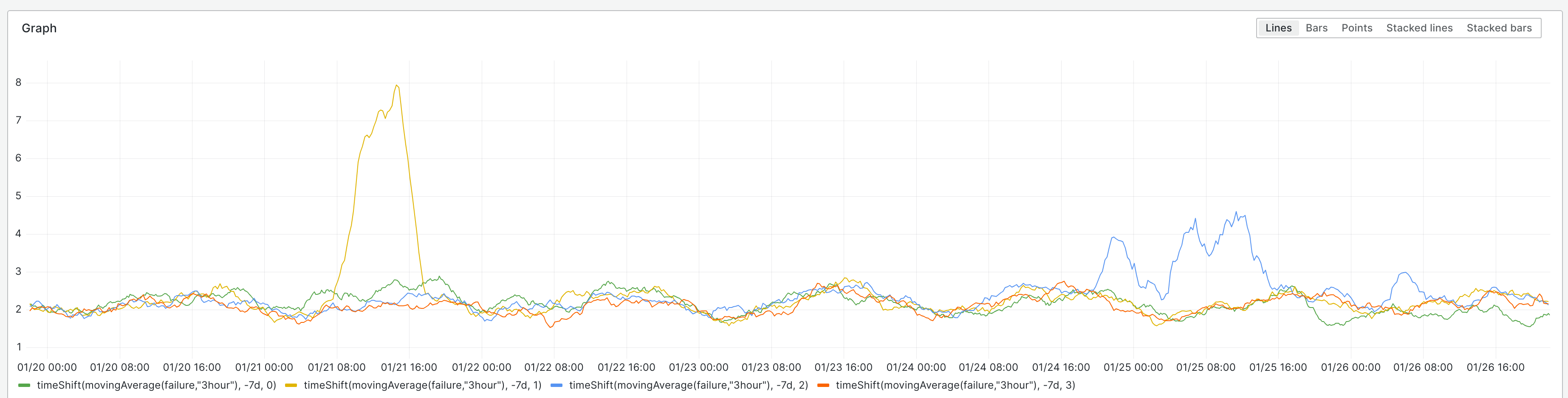
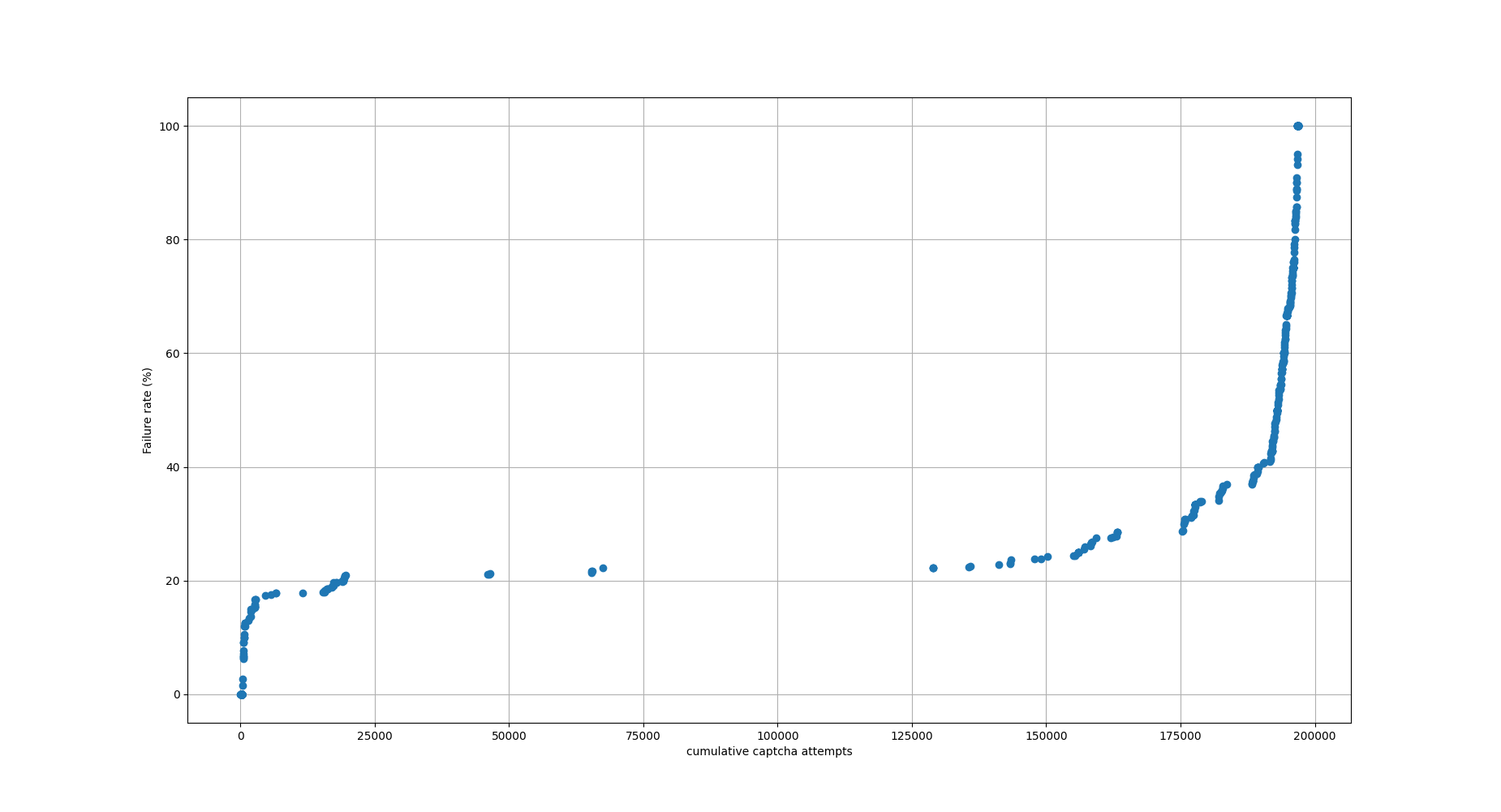
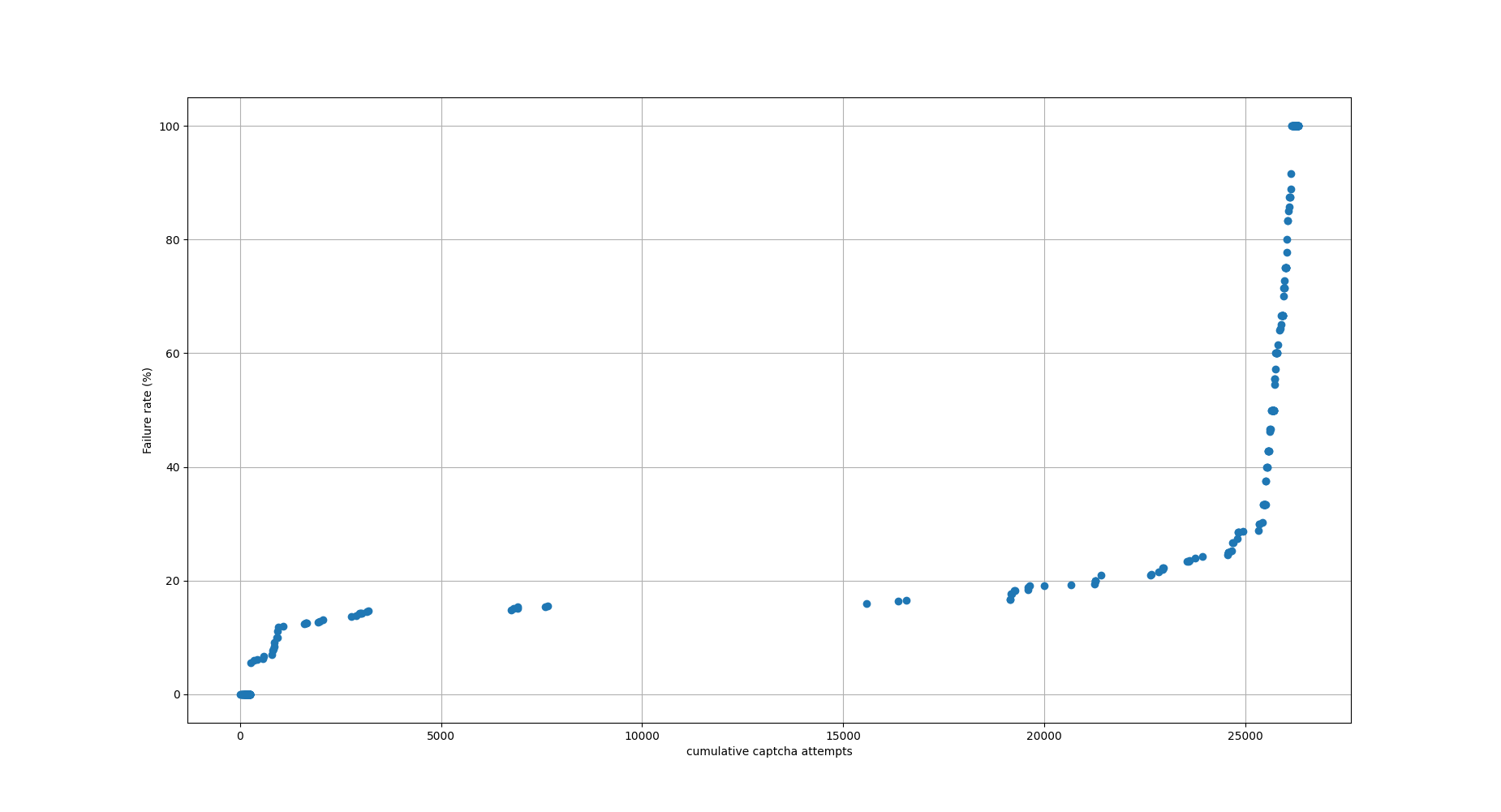
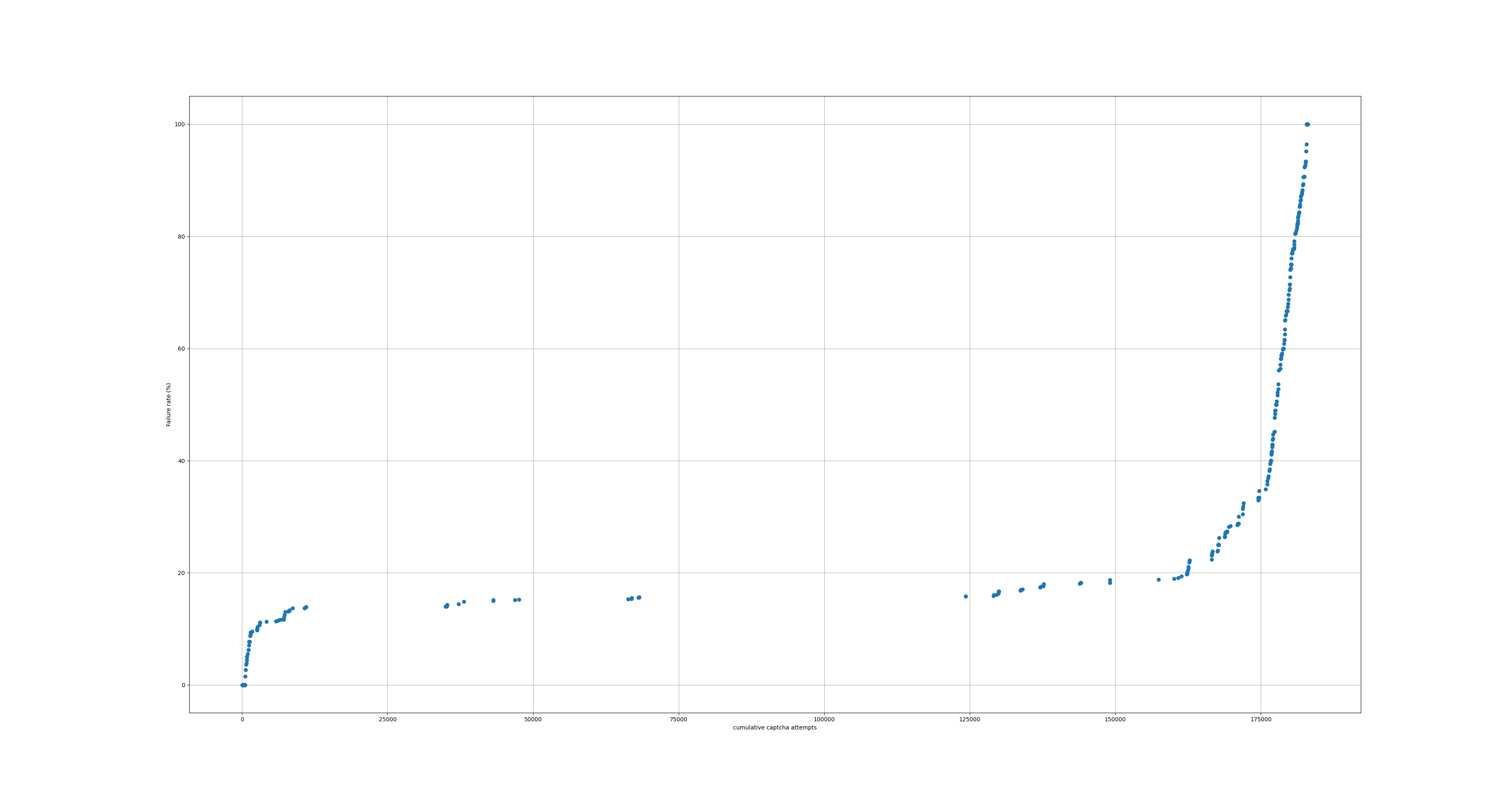
In 2014, I investigated FancyCaptcha's resistance to OCR. I found that it had essentially no resistance, that it could be trivially broken by open source software without image preprocessing or OCR engine configuration.
In these two changes, I implemented changes which were confirmed to defeat such naïve OCR attacks. Specifically, I tweaked the tunable parameters to improve distortion of the baseline, and added low-spatial-frequency noise and a gradient to defeat thresholding.
These changes were never deployed to WMF. I propose now doing so.
Here is some representative output:
| Old | New |
|---|---|
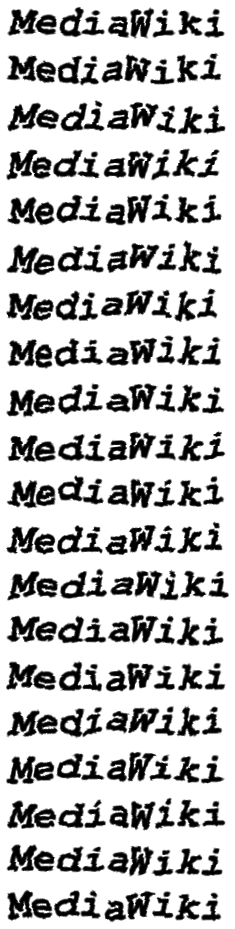 |       |
The procedure to regenerate the captcha image set is documented at https://wikitech.wikimedia.org/wiki/Generating_CAPTCHAs