We have an Icinga check that looks at the rate of MediaWiki fatals and exceptions in Graphite and alarms whenever a threshold is passed.
I found out today that the alarm on IRC seems to have kick of 30 minutes after the spike seen in logstash. From the IRC logs at http://bots.wmflabs.org/~wm-bot/logs/%23wikimedia-operations/20160728.txt
[12:46:28] <icinga-wm> PROBLEM - MediaWiki exceptions and fatals per minute on graphite1001 is CRITICAL: CRITICAL: 20.00% of data above the critical threshold [50.0] [12:50:18] <icinga-wm> RECOVERY - MediaWiki exceptions and fatals per minute on graphite1001 is OK: OK: Less than 1.00% above the threshold [25.0] [12:58:18] <icinga-wm> PROBLEM - MediaWiki exceptions and fatals per minute on graphite1001 is CRITICAL: CRITICAL: 60.00% of data above the critical threshold [50.0] [13:02:27] <icinga-wm> RECOVERY - MediaWiki exceptions and fatals per minute on graphite1001 is OK: OK: Less than 1.00% above the threshold [25.0]
The spike of exceptions happened at 12:15 as can be seen in logstash:
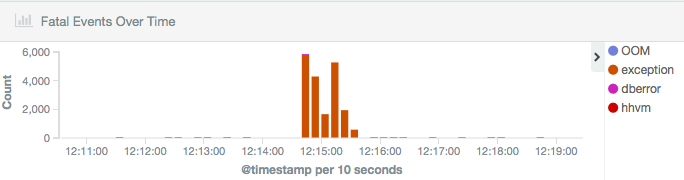
Or in Grafana Production Logging dashboard centered at 12:15 as well:
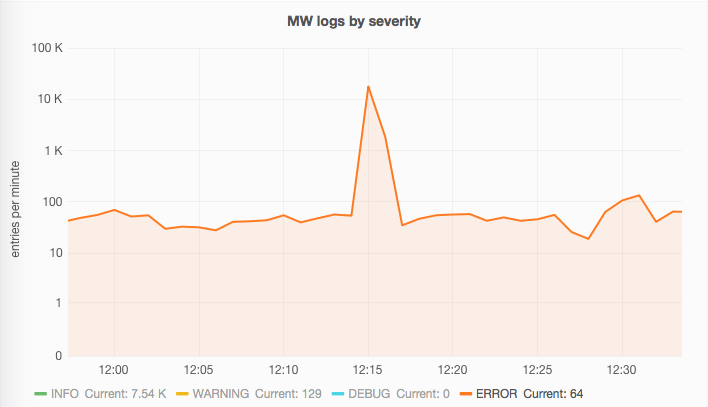
The Grafana metric being checked is transformNull(sumSeries(logstash.rate.mediawiki.fatal.ERROR.sum, logstash.rate.mediawiki.exception.ERROR.sum), 0) with warnings at 25 and critical at 50. Represented with OK state in green, Warning in orange and Critical in red from 12:00 to 13:00:
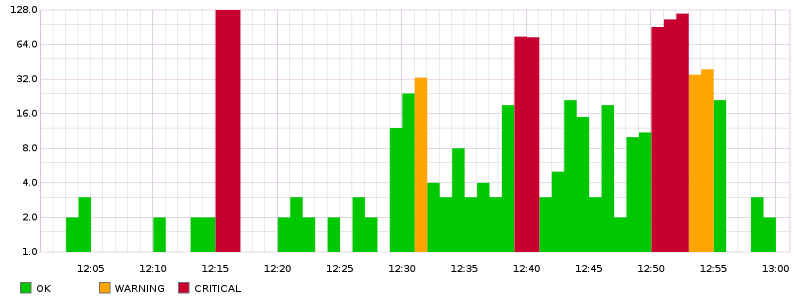
Graphite link for last six hours.
The Icinga logs
| Time | Level | State | State count | Message | |
|---|---|---|---|---|---|
| 2016-07-28 12:08:58 | WARNING | SOFT | 1 | 20.00% of data above the warning threshold [25.0] | |
| 2016-07-28 12:10:57 | OK | SOFT | 2 | Less than 1.00% above the threshold [25.0] | |
| 2016-07-28 12:22:38 | CRITICAL | SOFT | 1 | 40.00% of data above the critical threshold [50.0] | Spike detected after 7 minutes |
| 2016-07-28 12:24:38 | OK | SOFT | 2 | Less than 1.00% above the threshold [25.0] Erroneously cleared? | |
| 2016-07-28 12:36:38 | WARNING | SOFT | 1 | 20.00% of data above the warning threshold [25.0] | |
| 2016-07-28 12:38:38 | OK | SOFT | 2 | Less than 1.00% above the threshold [25.0] | |
| 2016-07-28 12:42:28 | CRITICAL | SOFT | 1 | 20.00% of data above the critical threshold [50.0] | First notice |
| 2016-07-28 12:44:28 | CRITICAL | SOFT | 2 | 40.00% of data above the critical threshold [50.0] | Second |
| 2016-07-28 12:46:27 | CRITICAL | HARD | 3 | 20.00% of data above the critical threshold [50.0] | Third -> HARD == 1st IRC notification (PROBLEM) |
| 2016-07-28 12:50:18 | OK | HARD | 3 | Less than 1.00% above the threshold [25.0] | 2nd IRC notification (RECOVERY) |
| Time | Level | State | State count | Message | |
| 2016-07-28 12:54:18 | CRITICAL | SOFT | 1 | 40.00% of data above the critical threshold [50.0] | |
| 2016-07-28 12:56:18 | CRITICAL | SOFT | 2 | 40.00% of data above the critical threshold [50.0] | |
| 2016-07-28 12:58:18 | CRITICAL | HARD | 3 | 60.00% of data above the critical threshold [50.0] | Third -> HARD = 3rd IRC notification (PROBLEM) |
| 2016-07-28 13:00:18 | WARNING | HARD | 3 | 20.00% of data above the warning threshold [25.0] | |
| 2016-07-28 13:02:27 | OK | HARD | 3 | Less than 1.00% above the threshold [25.0] | 4th IRC notification (RECOVERY) |