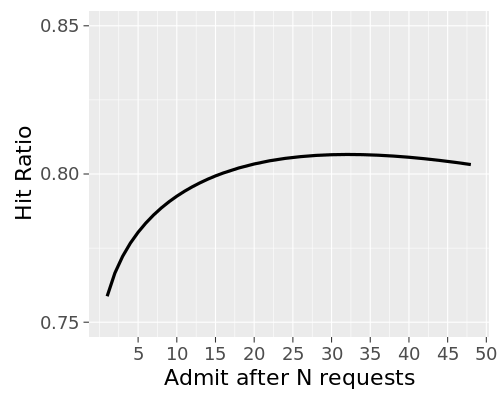
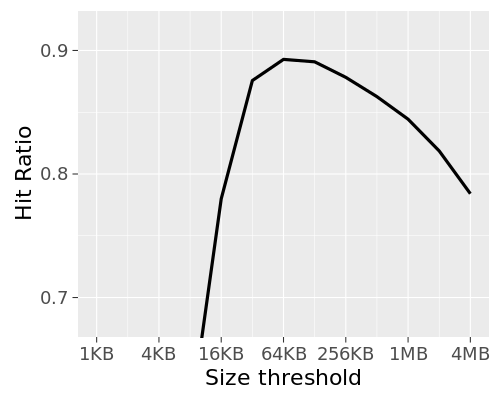
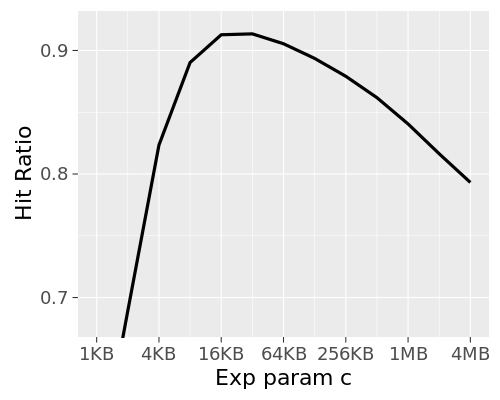
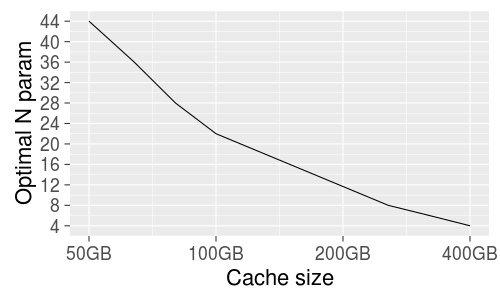
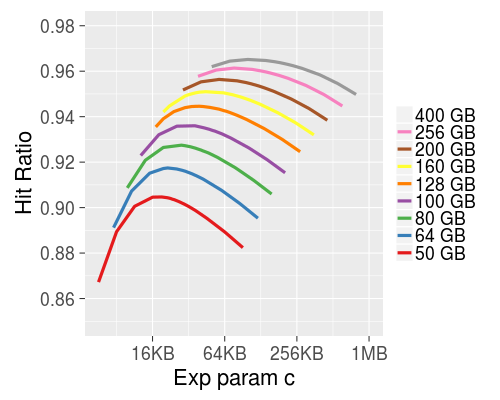
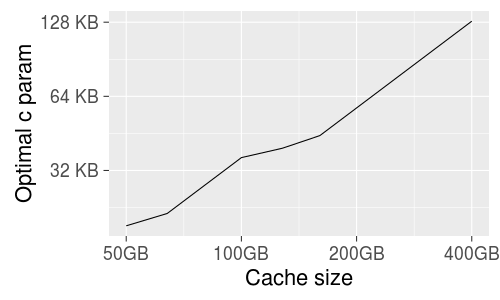
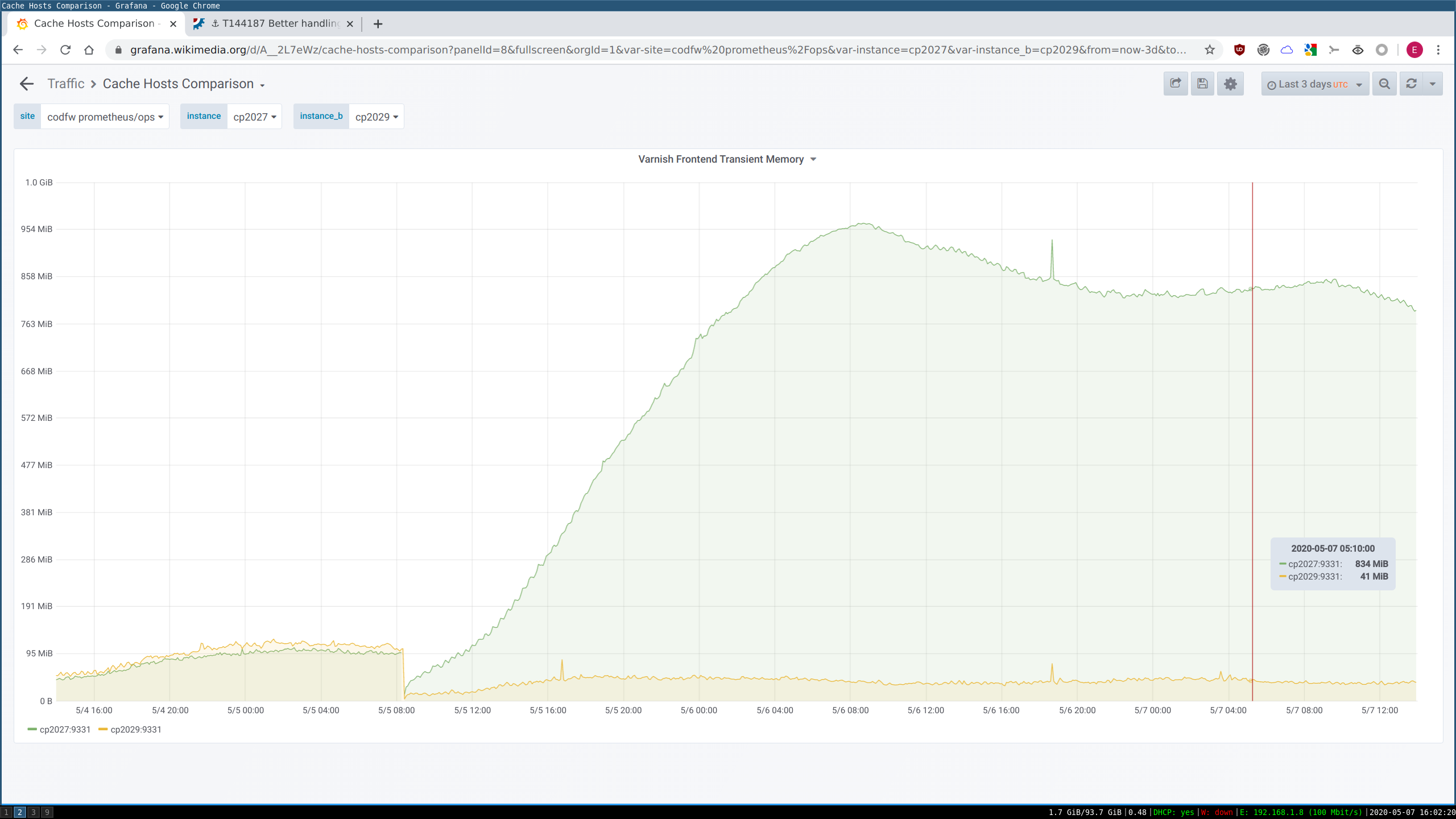
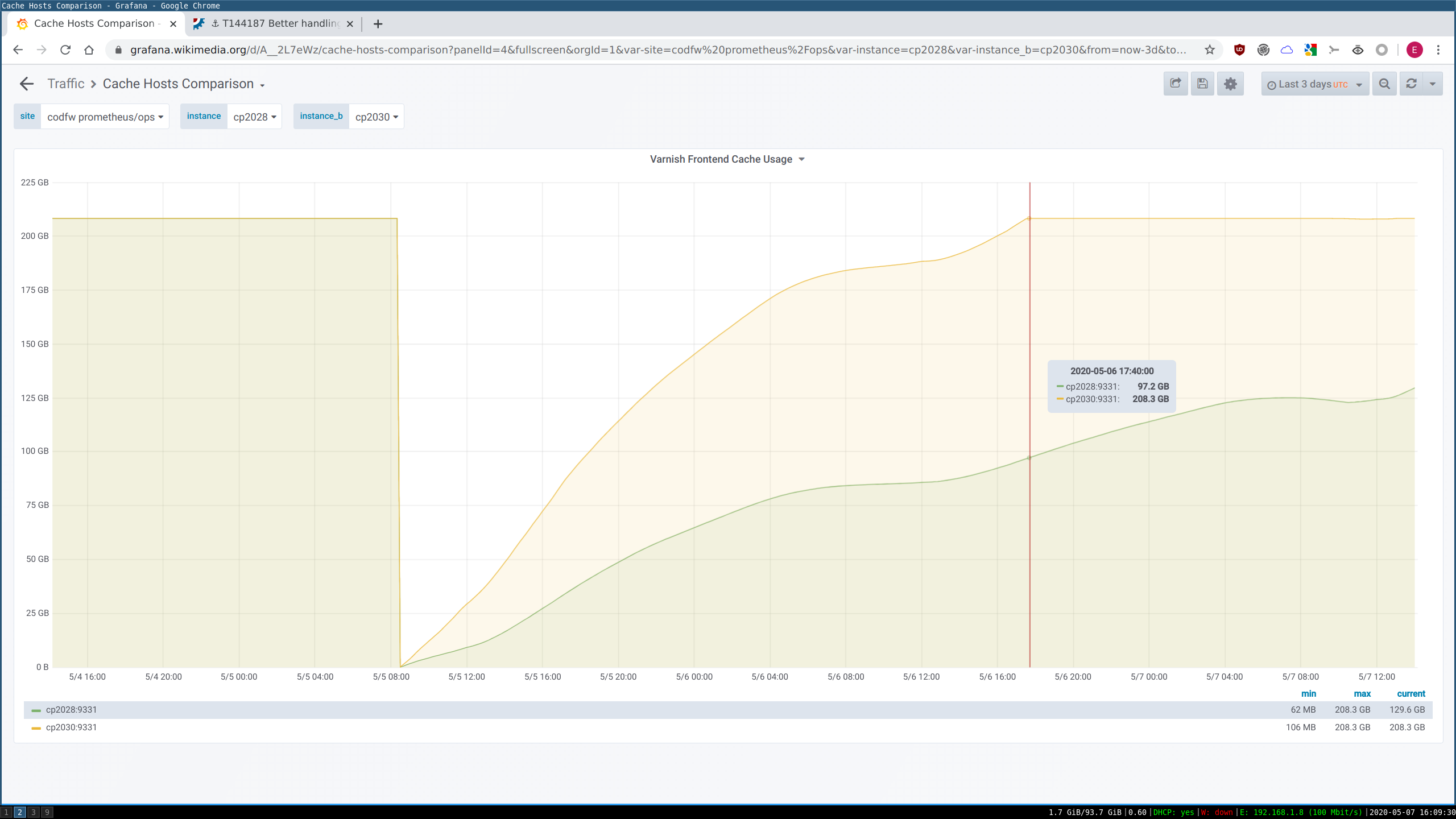
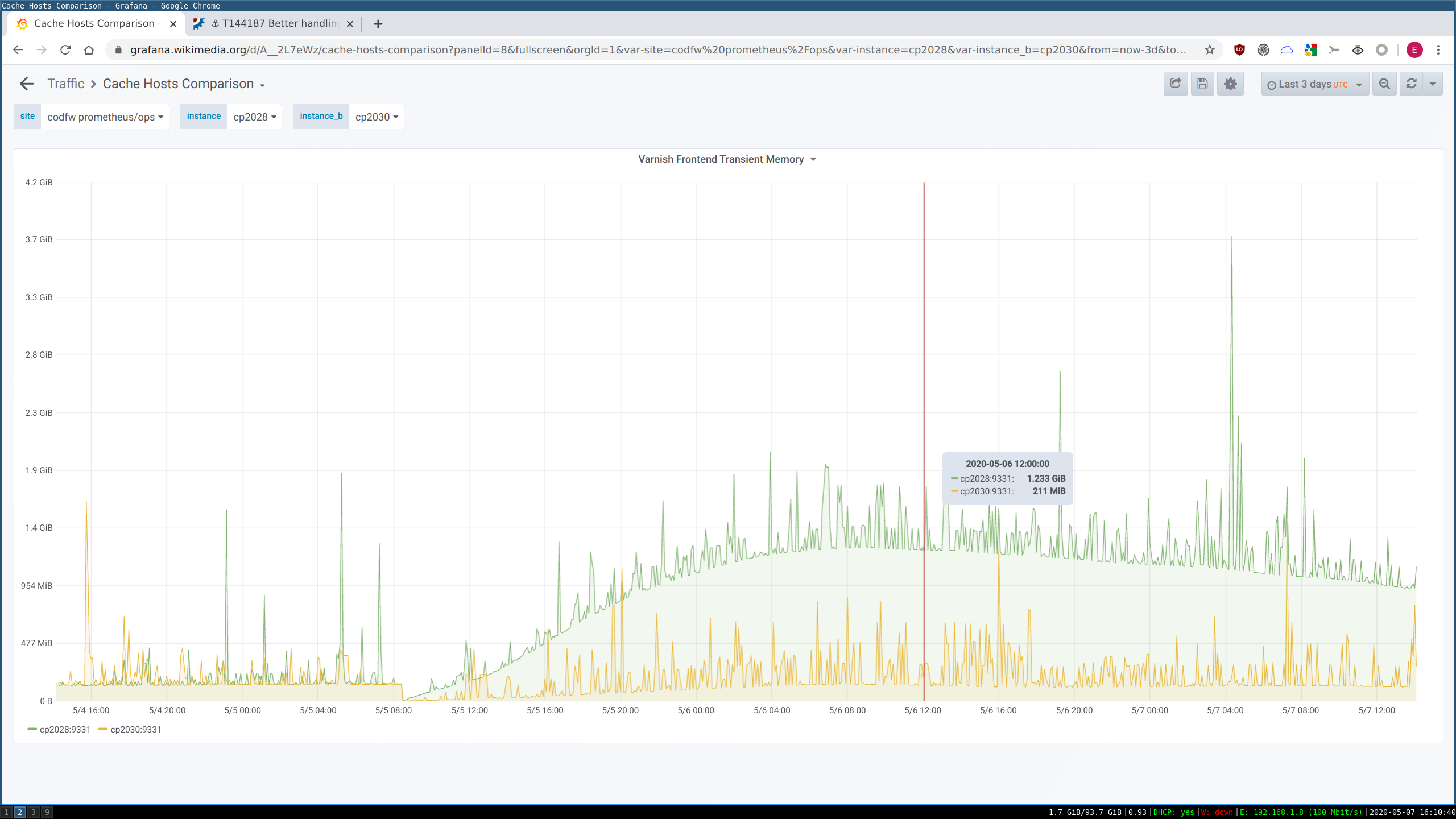
One of the sources of cache hit-rate inefficiency is one-hit-wonder objects. These are objects which are cacheable and get cached on usage, but tend to only get hit once in a blue moon (or once ever). They're still going to evict some other object based on LRU in a tight cache (especially our frontends), and that's usually the wrong choice. The hard part is "predicting" that a missed object will end up being a one-hit-wonder.
The first and most-general approach to this, that we've discussed (mostly offline from phab) in the past is to employ a Bloom Filter. The filter itself would be a fairly large memory object, but small compared to the actual dataset, and would allow us to tell the difference between "first miss ever" and "a miss on an object we've missed before", and effectively prevent caching an object the first time it's ever accessed (waiting for the second access to cache it). I first stumbled on this idea in: https://people.cs.umass.edu/~ramesh/Site/HOME_files/CCRpaper_1.pdf . @ema found this that's probably relevant too on Cuckoo Bloom filters being a better implementation choice: https://www.cs.cmu.edu/~dga/papers/cuckoo-conext2014.pdf .
I had a new idea today, though:
While the Bloom type approach is more general and works for a single cache layer, we already have additional metadata available to us in our frontends (the smallest caches, where this matters most) because of our layered caches. All requests passing through our frontends inevitably go through one or more backend cache layers with much larger storage size. We communicate the miss/hit status from the backend to the frontend on response in the X-Cache-Int header. Therefore we could potentially implement logic in our frontend VCL of the form "If the miss-fetch from the backend indicates the backend also missed, do not cache the object in the frontend". On the second fetch, it would be a hit in the backend (from the earlier miss->fetch->store there) and then also get cached in the frontend as a twice-seen object. This has an upside versus a local bloom filter in each frontend, too: the frontends are effectively sharing (at no cost) the twice-seen dataset (so if it's seen for the first time ever in Frontend1, but Frontend2 had seen it recently, it wouldn't get counted as one-hit-wonder, like it would with local Bloom filters).
There are pragmatic bits and pieces to sort out for this idea:
- Ideally, we should hook in the notion of varnishd uptime, so that the backend-miss-based one-hit-wonder filter doesn't kick in until a given cache daemon has been online and serving requests for longer than X minutes, to avoid doubling the request volume to the backend when warming up a cold cache. Uptime alone doesn't cover all such cases (e.g. depooled frontends...), but it would cover a lot of the common ones.
- How exactly in v3 or v4 do we make a given one-hit-wonder request act in every way like a normal cacheable response but not touch the cache storage? The answer is probably obj.ttl=0s + beresp.uncacheable and similar, but we need to be sure.
This would probably be superior to local Bloom for frontends, and about the same as local Bloom for intermediate backends where chashing is already in effect. This approach doesn't work for backend-most backends which talk directly to the applayer; they'd need a real filter to solve their own one-hit-wonder problem.