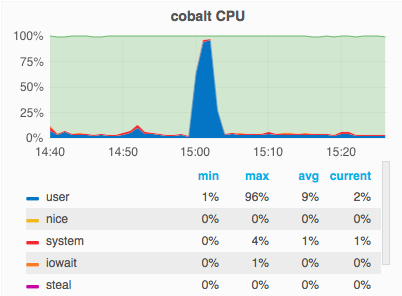
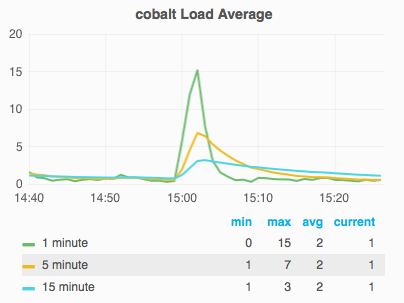
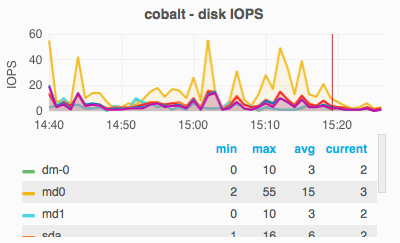
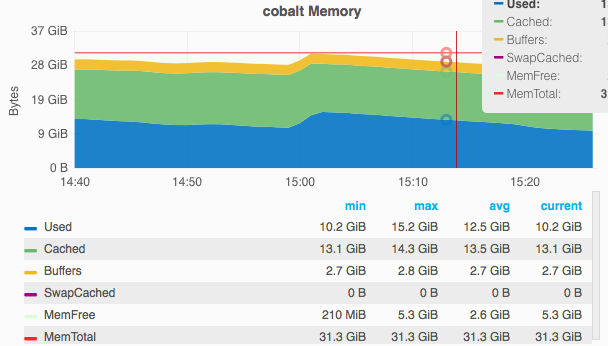
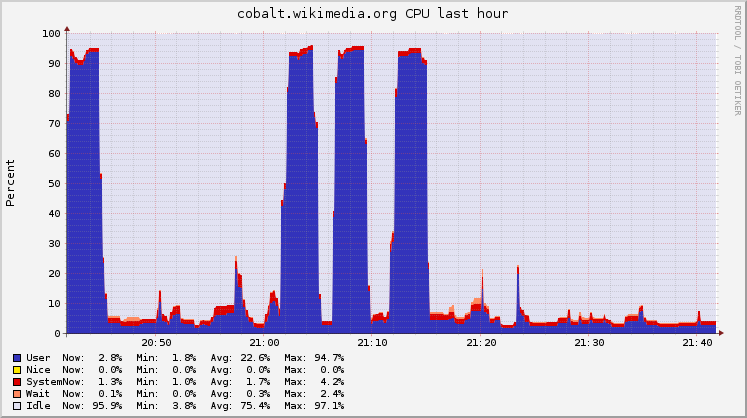
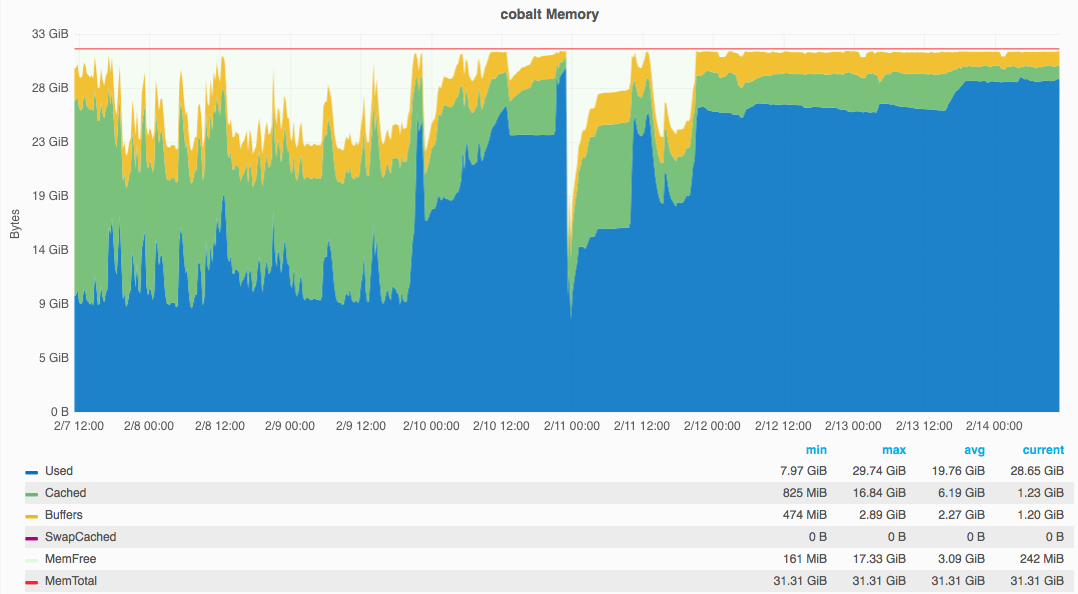
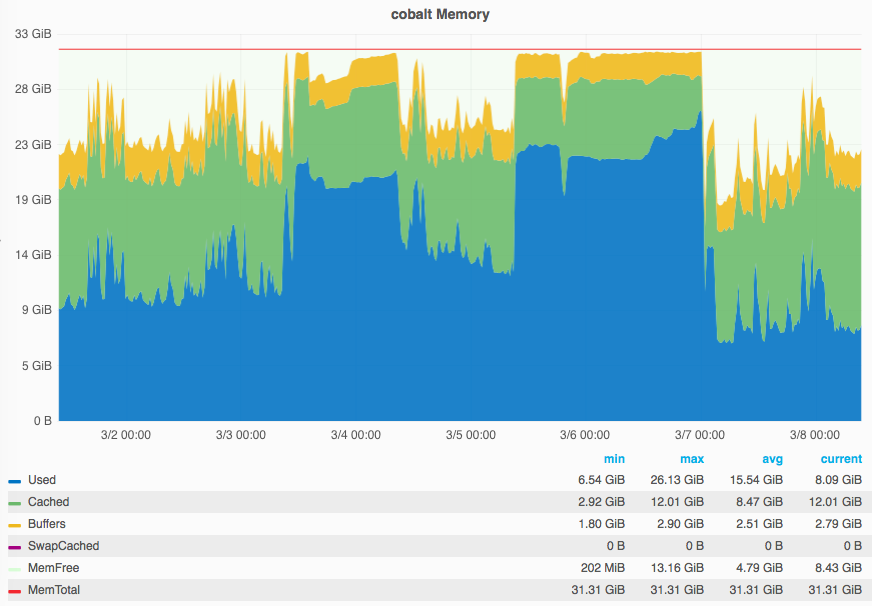
On October 17 2016, gerrit slowed down to the point the website wasn't loading or was taking a long time to load.
Firsts reports
<cwd> gerrit down? <paladox> gerrit.wikimedia.org is not loading for me <p858snake|L2_> mutante: ERR_TIMED_OUT for me, seemed to hanged at "Establishing secure connection" for me @Dzahn restarts gerrit <mutante> !log restarted gerrit on cobalt <mutante> so yea, just restarted the service <mutante> with the normal init.d script
and it works again.
18/10/2016
<andrewbogott> _joe_: they look fine to me — I'm going to leave the submit and merge to you because my gerrit is super slow for some reason <andrewbogott> (maybe yours is too :/ ) <_joe_> andrewbogott: heh indeed <mutante> andrewbogott: do you mean jenkins/zuul or actual gerrit <andrewbogott> actual gerrit <andrewbogott> like when I try to change views there's a 30-second or so pause <mutante> interesting, i cant confirm that <mutante> yet <mutante> seems fast to me <mutante> it had this slow down yesterday where i had to restart it, but now it seems normal <mutante> now i see what Andrew means.. hmmm
gerrit after that then went down at 19:20pm bst time
<mutante> now i see what Andrew means.. hmmmOn October 21 2016
<Nikerabbit> gerrit web interface not responding atm <AndyRussG> Nikerabbit: it's working for me, but excruciatingly slowly... <Dereckson> Nikerabbit: Gerrit back at normal speed for me
But when it slowed down on October 21 2016 there was no indications that gc was running and no high cpu either nor ram.
High cpu usage around the time the problem starts
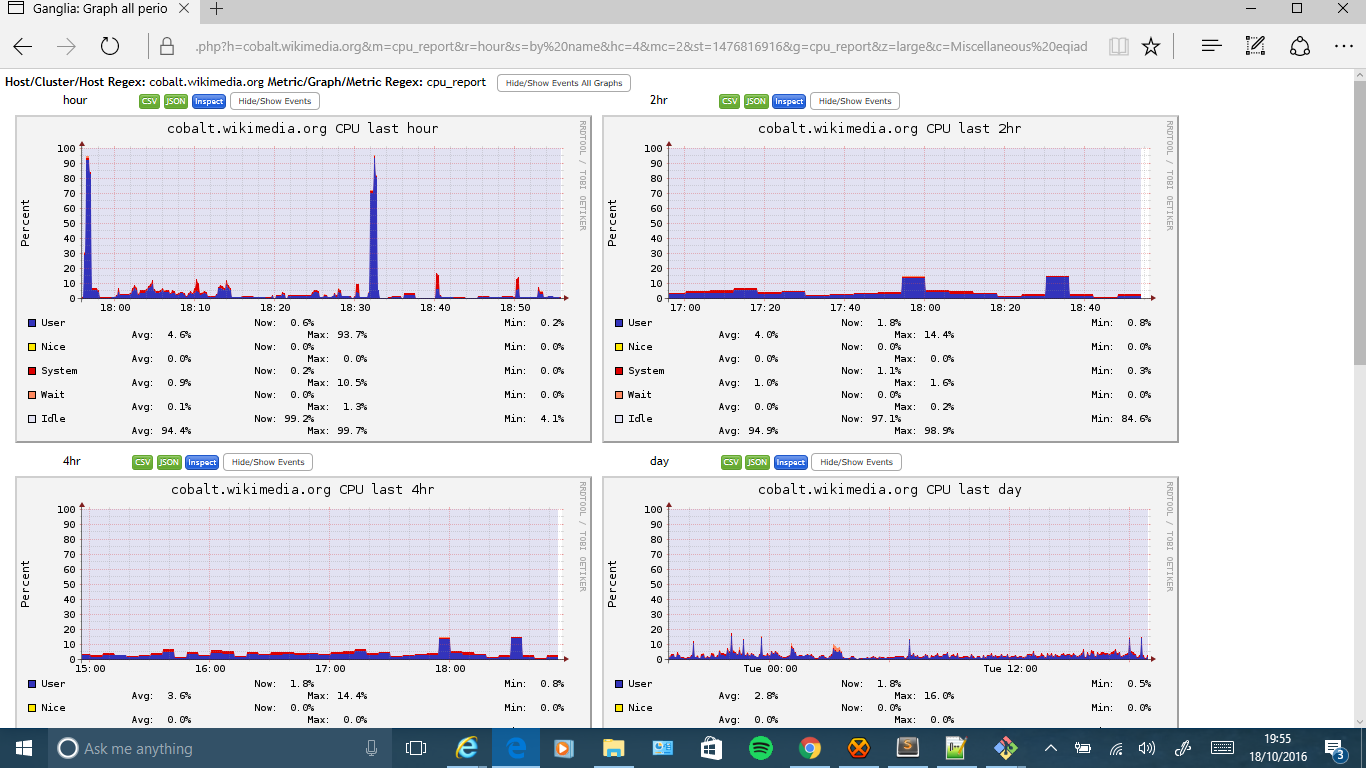
Problem started at around 3pm
Gerrit was reported by @hashar to not be working properly on the 16/12/2016. The cpu was very high at the time of the report
<hashar> I think Gerrit has exploded@Krenair found the web service was broken but ssh was fine
<Krenair> gerrit sshd is fine <Krenair> web server is broken
The new report from 16/12/2016 is after gc was disabled so maybe an aftermath of the problem or another problem just we were thinking it was gc for the other reports?
Investigate the following dates:
- 17/10/2016 (October 17, 2016)
- 18/10/2016 (October 18, 2016)
- 21/10/2016 (October 21, 2016)
- 30/11/2016 (November 30, 2016)
- 16/12/2016 (December 16, 2016)
- 01/01/2017 (January 1, 2017)
- 04/01/2017 (January 4, 2017)
- 10/02/2017 (February 10, 2017)