Happening since 20:51-20:57 2016-12-13 UTC. Reverting 1.29.0-wmf.6 -> wmf.5 made no difference:
- Suspicious patterns on the s3 master (a decrease in writes, but very spiky): https://grafana.wikimedia.org/dashboard/db/mysql?from=now-24h&to=now&var-dc=eqiad%20prometheus%2Fops&var-server=db1075
- 3x the query throughput (not a definitive measure, but could indicate something is wrong): https://grafana.wikimedia.org/dashboard/db/mysql-aggregated?var-dc=eqiad%20prometheus%2Fops&var-group=All&var-shard=s3&var-role=All&from=now-24h&to=now
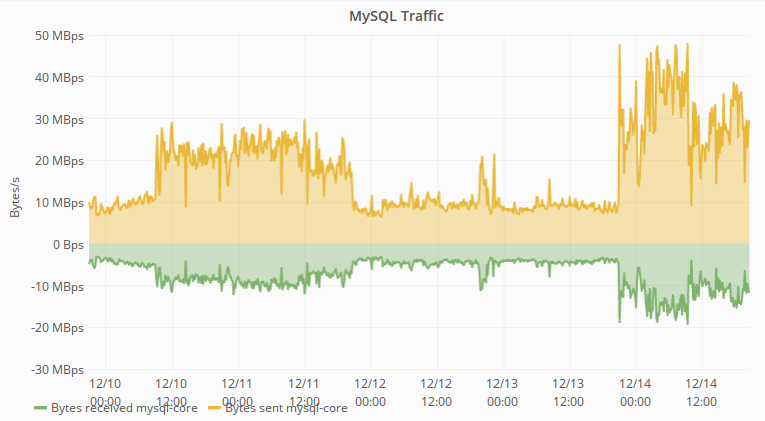
- Traffic increased 5x: https://grafana.wikimedia.org/dashboard/db/mysql-aggregated?panelId=2&fullscreen&var-dc=eqiad%20prometheus%2Fops&var-group=All&var-shard=s3&var-role=All&from=now-24h&to=now
- For a main s3 slave (db1077): 1.5-2x times the load of the average enwiki slave, when it used to be 0.5 times only
- 3-4x the QPS and traffic on a single slave: https://grafana.wikimedia.org/dashboard/db/mysql?panelId=16&fullscreen&var-dc=eqiad%20prometheus%2Fops&var-server=db1077&from=now-24h&to=now https://grafana.wikimedia.org/dashboard/db/mysql?panelId=5&fullscreen&var-dc=eqiad%20prometheus%2Fops&var-server=db1077&from=now-24h&to=now
- 2-3x the server load: https://grafana.wikimedia.org/dashboard/file/server-board.json?var-server=db1077&var-network=eth0&from=now-24h&to=now
- IO activity dropped hugely, which can be a sign of server contention: https://grafana.wikimedia.org/dashboard/db/mysql?panelId=20&fullscreen&var-dc=eqiad%20prometheus%2Fops&var-server=db1077&from=now-24h&to=now https://grafana.wikimedia.org/dashboard/db/mysql?panelId=34&fullscreen&var-dc=eqiad%20prometheus%2Fops&var-server=db1077&from=now-24h&to=now
- Mutex contention increased 10x: https://grafana.wikimedia.org/dashboard/db/mysql?panelId=23&fullscreen&var-dc=eqiad%20prometheus%2Fops&var-server=db1077&from=now-24h&to=now