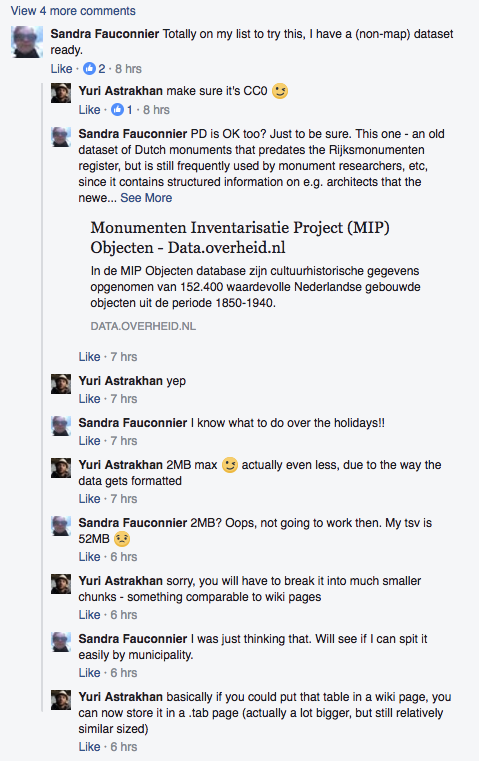
There is a 2MB limit (actually slightly less) for the data that can be used in graphs - let's investigate if and how we can get that raised.
For more background info, here's a Facebook question about it.
| debt | |
| Dec 21 2016, 5:26 PM |
| F5127085: graph question - 2mb vs 52mb.png | |
| Dec 21 2016, 5:26 PM |
There is a 2MB limit (actually slightly less) for the data that can be used in graphs - let's investigate if and how we can get that raised.
For more background info, here's a Facebook question about it.
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Resolved | CKoerner_WMF | T144512 Support Discovery Q2 Goal: Increase maps and graphs usage on Wikipedia | |||
| Open | None | T153878 Investigate how to increase data limit for graphs |
The 2MB limit is imposed by the storage backend. Currently, we could optimize it a bit, so that instead of sending JSON data in a "pretty" format (with spaces and indentations), we only send the compact version - this should increase the amount of the data in some cases 10x, but we will still be under 2MB of the usable space.
For larger datasets, this has been discussed a number of times before - it would be great, but this is a mega epic. It might require a new storage backend cluster, a new way to access that data, a big community engagement to figure out how to curate it, etc etc etc. This is part of the external data feed ideas we discussed in the road map for a year down the line.
Commons is a wiki, same as all others. There are two main stores - for pages and for files. Files can be large, but they lack all the versatility of the page manipulation/editing. Wikipages could be of other formats, not just Wiki markup. JSON storage (.tab & .map) use the later, thus they have the 2MB limit.
Second issue - editing. Files do not get edited by part, they are edited as a whole and uploaded. Technically, so do wiki pages, but because they are small, they are much easier to use in the "edit" mode - send the whole page to the client, alter it a bit, and send it back to the server. Which means a minor modification, like adding an extra table row, is ok. We will not be able to support very large data sets in that mode, but they require it, so we will need to rethink our storage architecture, and likely implement a 3rd way.
Lastly, organizational problem - maintaining a very different type of content is hard - it requires new tools to be built by the community (e.g. bots), it requires a different set of rules and procedures. A file is evaluated in its entirety. The wiki page edit is often looked at as the diff with the previous version. With the large dataset, it might make it increasingly difficult to do it. So it is possible that for large files, we should go the "file-like" route, where the community decides which external sources are valuable, and we do automatic download of that data.
Is there anything we can suggest as a possible work-around for those folks that want to have larger datasets? Is there a better/different way for them to have their data and eat their cake too?
Yep, already suggested - need to split the data up into small chunks, e.g. by region/state/city, or by some aspect, e.g. population data in one vs forestation data in another
That would be great information to be added to the announcement and/or help pages, because I'm positive it'll be asked a few times! :)
32 months later, @Yurik, what's the status regarding implementing a new storage architecture for datasets (assuming that a stopgap measure such as uploading JSON in compact formats is somehow not tenable)? T200968 has officially opened up the floodgates for the upload of larger datasets, but there is still the issue, even when one does split up the data into discrete chunks, of overshooting this 2MB limit. Take, for example, the boundaries of https://www.wikidata.org/wiki/Q338425 : how does one properly split the data up into small chunks when the borders of its constituent elements (which I'm sure people would upload separately if those constituent element borders formed a partition (set theory) of the district) are not known?
(As a note, I see in Wikidata's Special:LongPages, which lists pages and not files, lots of pages over 2MB in size. Where in the wide world of configuration files is the 2MB limit on Commons's storage given? I didn't find anything in InitialiseSettings.php, for example.)