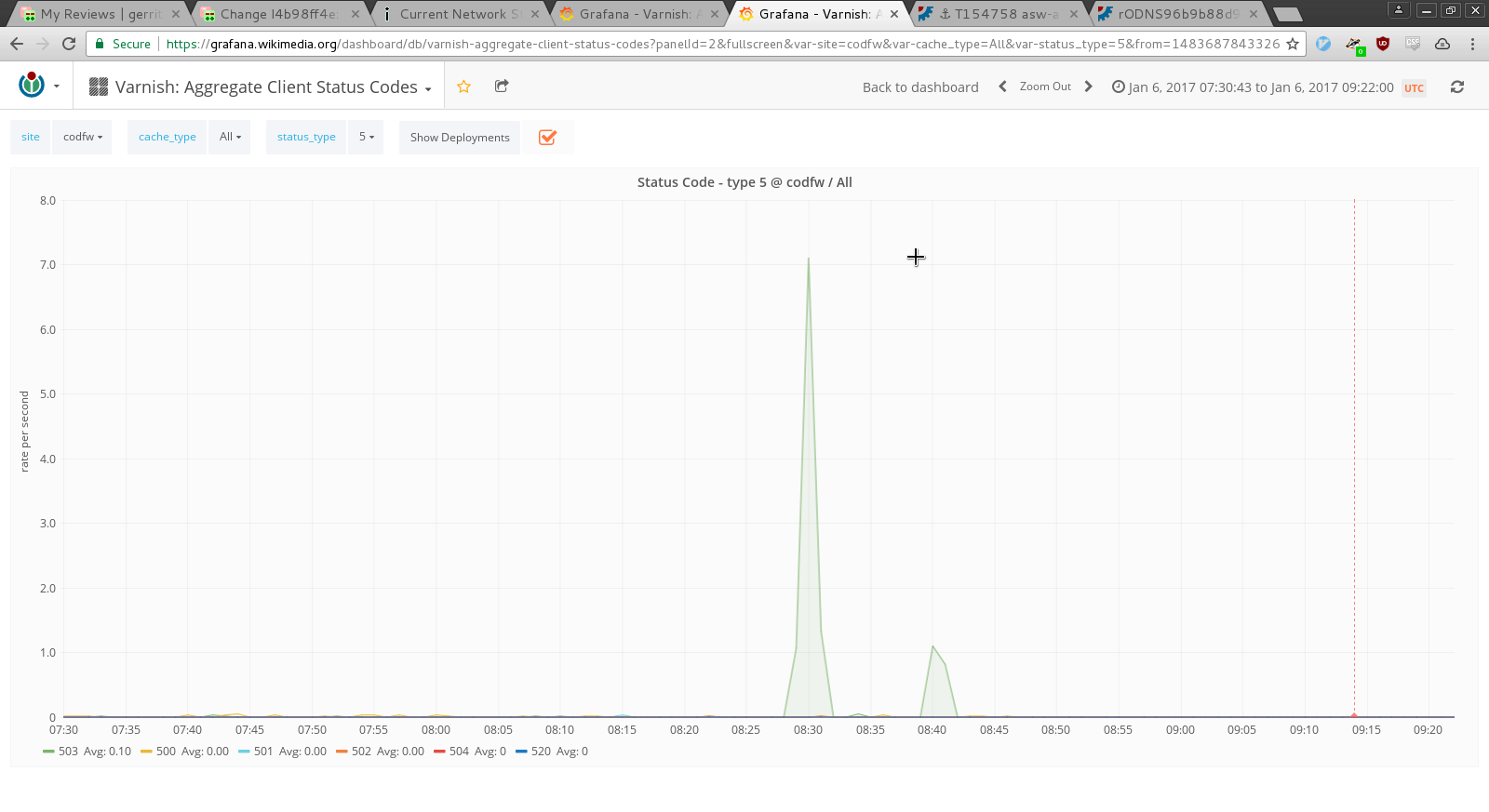
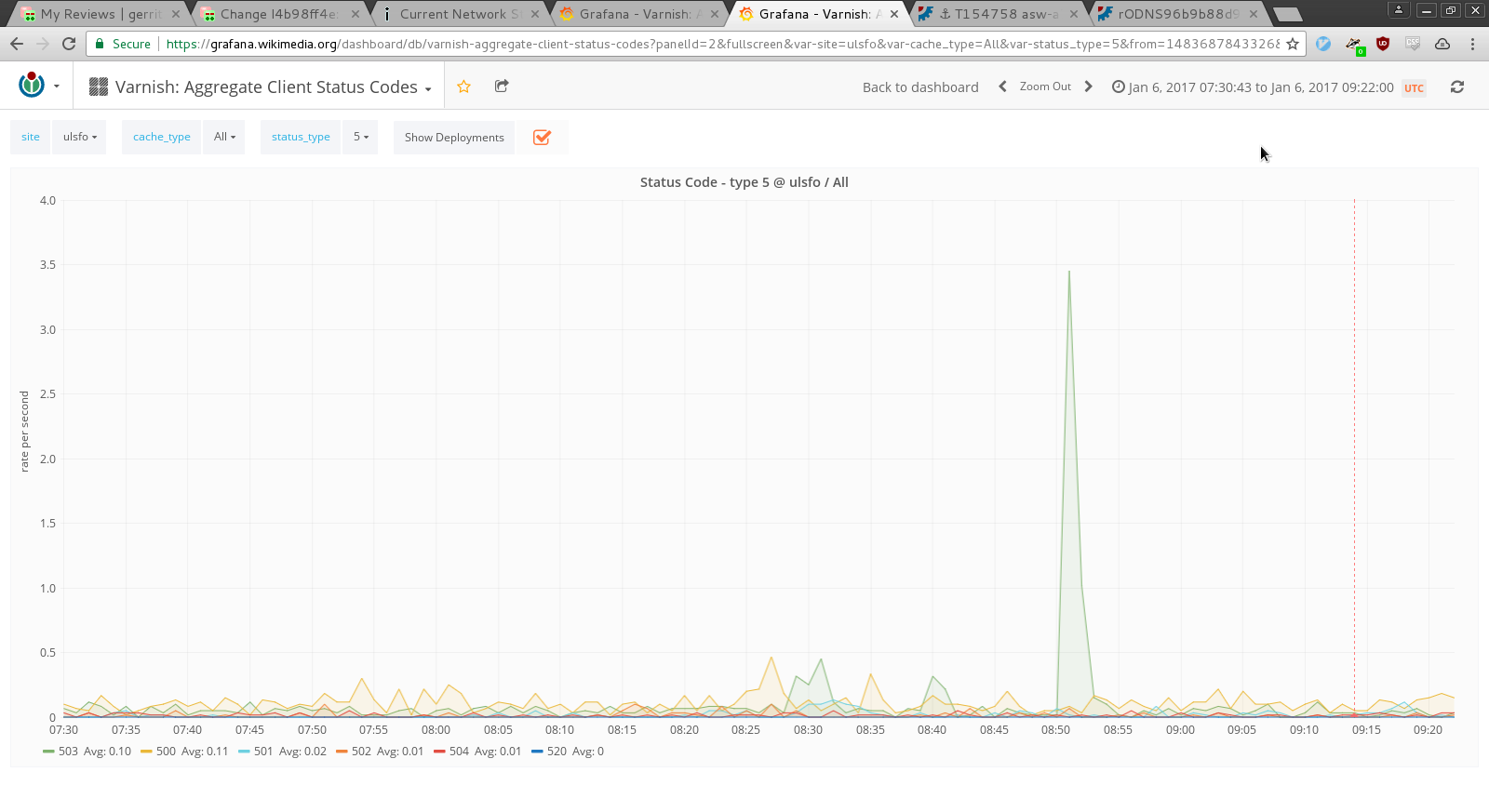
asw-a7-codfw went down at Jan 6th 08:37 UTC. Switch's console is unresponsive, maybe hardware fault? These servers are down:
xe-7/0/0 mc2004
xe-7/0/1 mc2005
xe-7/0/2 mc2006
xe-7/0/3 cp2004
xe-7/0/4 ms-fe2002
xe-7/0/5 cp2005
xe-7/0/6 cp2006
xe-7/0/7 ms-be-2017
xe-7/0/45 lvs2006-eth1
xe-7/0/46 lvs2005-eth1
xe-7/0/47 lvs2004-eth1
et-7/0/52 << cr2-codfw:et-0/0/0 {#10706} [40Gbps DF]Fallout:
- Since 3 cp* are down, @ema/@Joe depooled cp* (3188f9dd078fa8c2d21eeeebb136657cc459926c, 96b9b88d94d3d044972de9580c9cfa5eaab11949). I assume this due to its lack of redundancy and miss rates, since otherwise the clusters (probably?) work.
- On lvs'es, acamar (a row A server) is first in resolv.conf and lvs2006's pybal wasn't happy with the delays and marked everything as down. It's the backup lvs2006, so not user-facing issues but still something to follow up on. I've commented it out on lvs2006 as a manual hack; needs further investigation (T154759). puppetmaster2001 is on row A as well, so puppet is currently unreachable from lvs2004/5/6 (minor).
- Due to cr2-codfw<->asw-a-codfw turning into down (and probably due to the fact that cr2 is the VRRP master) there was a very small flap. This caused issues for ElasticSearch (now recovering) and alert spam.