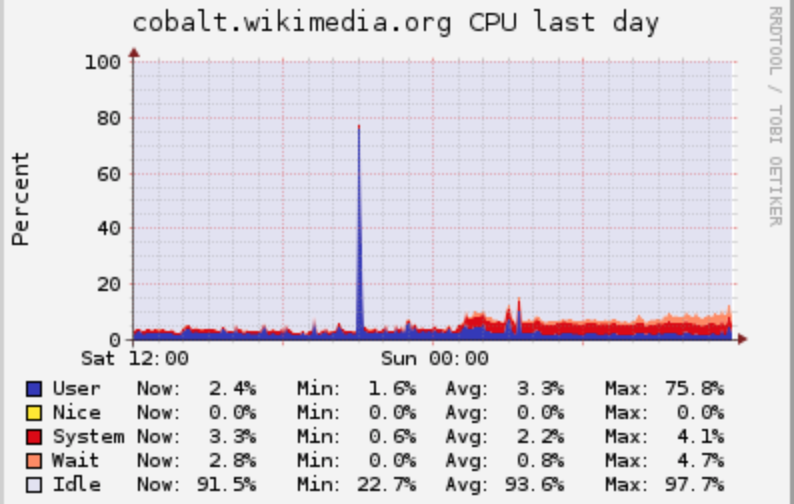
Investigate why gerrit went down for one minute on 05/02/07
[01:06:16] <icinga-wm> PROBLEM - MD RAID on cobalt is CRITICAL: CHECK_NRPE: Socket timeout after 10 seconds. [01:06:17] <icinga-wm> PROBLEM - configured eth on cobalt is CRITICAL: CHECK_NRPE: Socket timeout after 10 seconds. [01:06:26] <icinga-wm> PROBLEM - Check whether ferm is active by checking the default input chain on cobalt is CRITICAL: CHECK_NRPE: Socket timeout after 10 seconds.
then recovered a minute later.
[01:07:07] <icinga-wm> RECOVERY - MD RAID on cobalt is OK: OK: Active: 8, Working: 8, Failed: 0, Spare: 0 [01:07:07] <icinga-wm> RECOVERY - configured eth on cobalt is OK: OK - interfaces up [01:07:16] <icinga-wm> RECOVERY - Check whether ferm is active by checking the default input chain on cobalt is OK: OK ferm input default policy is set
after i created this task, these warnings started
[01:10:16] <icinga-wm> PROBLEM - dhclient process on cobalt is CRITICAL: CHECK_NRPE: Socket timeout after 10 seconds. [01:10:16] <icinga-wm> PROBLEM - salt-minion processes on cobalt is CRITICAL: CHECK_NRPE: Socket timeout after 10 seconds. [01:10:17] <icinga-wm> PROBLEM - Check systemd state on cobalt is CRITICAL: CHECK_NRPE: Socket timeout after 10 seconds. [01:10:17] <icinga-wm> PROBLEM - DPKG on cobalt is CRITICAL: CHECK_NRPE: Socket timeout after 10 seconds. [01:10:17] <icinga-wm> PROBLEM - MD RAID on cobalt is CRITICAL: CHECK_NRPE: Socket timeout after 10 seconds.
then recovered a minute later.
[01:11:07] <icinga-wm> RECOVERY - dhclient process on cobalt is OK: PROCS OK: 0 processes with command name dhclient [01:11:07] <icinga-wm> RECOVERY - salt-minion processes on cobalt is OK: PROCS OK: 1 process with regex args ^/usr/bin/python /usr/bin/salt-minion [01:11:07] <icinga-wm> RECOVERY - Check systemd state on cobalt is OK: OK - running: The system is fully operational [01:11:07] <icinga-wm> RECOVERY - DPKG on cobalt is OK: All packages OK [01:11:07] <icinga-wm> RECOVERY - MD RAID on cobalt is OK: OK: Active: 8, Working: 8, Failed: 0, Spare: 0
times are in utc +0 (uk time)