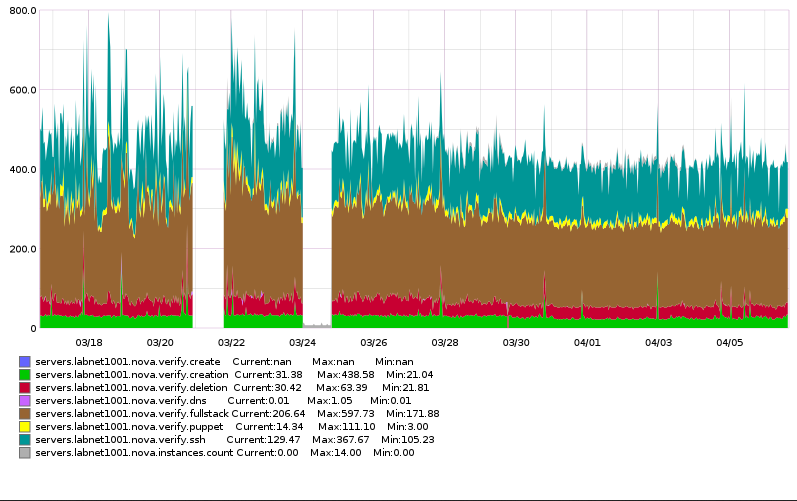
This leaves nodes unreachable. It seems like historically they can be fixed by rebooting the instance which retriggers the rc.local logic (and indicates the initial run of this does not reach a place where it would not-rerun). This may not always be the case however as the latest batch does not present in this manner.
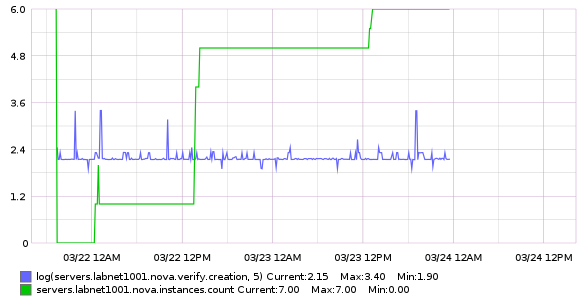
We leaked 4 instances again over the weekend:
| c4ba92cc-f05b-4c1e-9862-a576846e4574 | fullstackd-1489919156 | REBOOT | public=10.68.23.230 | | 02edf4d2-d7b1-4acb-894c-0005322b2bcb | fullstackd-1489833813 | ACTIVE | public=10.68.22.232 | | f472b816-c35b-4795-a886-ebf4c6e7e365 | fullstackd-1489828105 | ACTIVE | public=10.68.18.226 | | 69924d23-263b-461d-962f-8776e58cec89 | fullstackd-1489807288 | ACTIVE | public=10.68.17.181 |
root@labnet1001:~# zgrep -i exception /var/log/upstart/nova-fullstack.log*
/var/log/upstart/nova-fullstack.log.1: raise Exception("SSH for {} timed out".format(address))
/var/log/upstart/nova-fullstack.log.1:Exception: SSH for 10.68.23.230 timed out
/var/log/upstart/nova-fullstack.log.2.gz: raise Exception("SSH for {} timed out".format(address))
/var/log/upstart/nova-fullstack.log.2.gz:Exception: SSH for 10.68.18.226 timed out
/var/log/upstart/nova-fullstack.log.2.gz: raise Exception("SSH for {} timed out".format(address))
/var/log/upstart/nova-fullstack.log.2.gz:Exception: SSH for 10.68.22.232 timed out
/var/log/upstart/nova-fullstack.log.3.gz: raise Exception("creation of {} timed out".format(cserver.id))
/var/log/upstart/nova-fullstack.log.3.gz:Exception: creation of af44fbd0-d4bd-43c2-80f5-c4ef93e33e1a timed out
/var/log/upstart/nova-fullstack.log.3.gz: raise Exception("SSH for {} timed out".format(address))
/var/log/upstart/nova-fullstack.log.3.gz:Exception: SSH for 10.68.17.181 timed outThis has been happening for awhile and surfaced as we addressed T159459: openstack instance creation sometimes takes >480s
I rebooted fullstackd-1489919156.admin-monitoring.eqiad.wmflabs
nova reboot c4ba92cc-f05b-4c1e-9862-a576846e457462-a576846e4574
Which did not come back and has some very wrong console output:
2017-03-20T12:53:32.142146+00:00 localhost systemd[1]: Startup finished in 22.193s (kernel) + 46.685s (userspace) = 1min 8.878s. Debian GNU/Linux 8 localhost ttyS0 localhost login:
This could be related to nova-fullstack using a different image https://gerrit.wikimedia.org/r/#/c/343207/