When using the label service a lot of queries time out.
One can avoid that by using a subquery for fetching the data and add the labels in the outer query.
The problem is not everybody is aware of it and it makes the query more complex.
So one solution could be that the optimizer for labels does this automatically.
Description
Description
Related Objects
Related Objects
- Mentioned In
- T272490: Improve labelling performance in query builder
T272140: Duplicates in the result set
T212933: Optimize SERVICE wikibase:label
T187314: Display labels for entity values at result visualisation step in Wikibase Query Engine
T179879: Provide a 5-minute timeout in WDQS for trusted users using OAuth - Mentioned Here
- P5706 Regular vs. named subquery performance
Event Timeline
Comment Actions
Here’s an example query:
SELECT ?entity ?entityLabel (COUNT(?statement) AS ?count) WHERE {
hint:Query hint:optimizer "None".
?statement wikibase:rank wikibase:DeprecatedRank.
?entity ?p ?statement.
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }
}
GROUP BY ?entity ?entityLabel
HAVING(?count > 10)
ORDER BY DESC(?count)
LIMIT 100
OFFSET 0The HAVING and OFFSET modifiers are somewhat artificial (I added them to have a complete example), but apart from that, this is a real, useful query (entities with most deprecated statements).
Here’s the optimized version:
SELECT ?entity ?entityLabel ?count WITH {
SELECT ?entity (COUNT(?statement) AS ?count) WHERE {
hint:Query hint:optimizer "None".
?statement wikibase:rank wikibase:DeprecatedRank.
?entity ?p ?statement.
}
GROUP BY ?entity
HAVING(?count > 10)
ORDER BY DESC(?count)
LIMIT 100
OFFSET 0
} AS %results WHERE {
INCLUDE %results.
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }
}
ORDER BY DESC(?count)- The inner SELECT clause consists of the original one, but with all Label variables removed.
- The outer SELECT clause consists of all the variables of the original one, but without expressions (e. g. just ?count).
- Of the solution modifiers,
- GROUP BY is only present on the inner query, and with all Label variables removed,
- HAVING, LIMIT and OFFSET are only present on the inner query, and
- ORDER BY is present on both queries.
Of course, this optimization should work with or without explicit rdfs:label parameters for the label service, so it’s probably best to implement this as a separate optimizer which runs after the one that imports rdfs:label parameters from the SELECT clause.
Comment Actions
Note here:
SELECT ?entity (COUNT(?statement) AS ?count) WHERE {
hint:Query hint:optimizer "None".
?statement wikibase:rank wikibase:DeprecatedRank.
?entity ?p ?statement.
}
GROUP BY ?entity ?entityLabel
HAVING(?count > 10)
ORDER BY DESC(?count)
LIMIT 100you group by non-existing variable (?entityLabel). In order to group properly, and also for group variables work properly in projection clause, it will have to understand a lot about the query structure.
I wonder also why the latter is so much faster - maybe we could do something in service to speed it up...
Comment Actions
you group by non-existing variable (?entityLabel).
Thanks, fixed.
In order to group properly, and also for group variables work properly in projection clause, it will have to understand a lot about the query structure.
It doesn’t need to understand that much, right? It only needs to know which variables are label variables, so that they can be removed from the inner SELECT and GROUP BY.
(Hm, what happens if the label variables are used in the HAVING or ORDER BY solution modifiers? I guess for now, the optimization could be disabled in that case.)
Comment Actions
I did a quick check and the first query form resolves 44326 labels, 23178 of them unique, even though it only needs 100 in the second form. The problem is, the query semantics is different there - there's no way to know which labels should be in those 100 selected, and also the label may have participate in projections, conditionals etc. which could influence the result.
This form:
SELECT ?entity ?entityLabel ?count WHERE {
{
SELECT ?entity (COUNT(?statement) AS ?count) WHERE {
?statement wikibase:rank wikibase:DeprecatedRank.
?entity ?p ?statement.
}
GROUP BY ?entity ?entityLabel
HAVING(?count > 10)
ORDER BY DESC(?count)
LIMIT 100
OFFSET 0
}
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }
} ORDER BY DESC(?count)Does not require named subquery and also produces the same result. I'm not sure though how to automatically and cleanly extract label service outside. I'll think about it.
Comment Actions
This form… does not require named subquery and also produces the same result.
Sure, it should be equivalent… but the non-named subquery seems to be a lot slower for whatever reason (~700 ms vs. ~2500 ms). Is there any downside to using a named subquery?
Comment Actions
I found the opposite - the non-named one was faster. I suspect the variance is due to the cache state and the server the query runs on.
The downside is a) more verbose form b) using non-standard SPARQL facility. Also, you don't need to disable the optimizer. Other than that, both should work.
Comment Actions
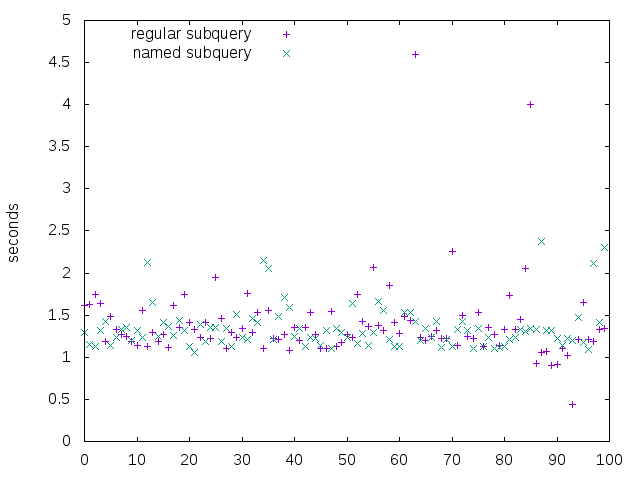
Strange… I was under the impression that named subqueries are typically faster, but in this case it doesn’t seem to make much of a difference. I ran both versions 100 times (P5706), and while regular subqueries have a few slow outliers, overall they seem to perform equally well:
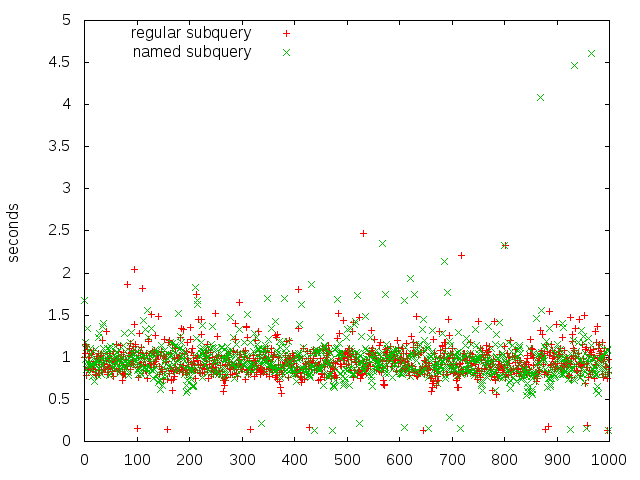
Edit: The picture for 1000 iterations looks pretty similar, except that this time the named subqueries have a few outliers instead of the regular ones:
Comment Actions
I think there must be a misunderstanding here… it’s not clear whether a named subquery or a non-named subquery is faster, but there is a very definitive performance improvement in adding the (named or regular) subquery over the unoptimized query. You yourself wrote:
the first query form resolves 44326 labels, 23178 of them unique, even though it only needs 100 in the second form.
The point of this issue is to defer label service execution until the results have already been found without the label service, unless that’s not possible (e. g. because the labels are used in a HAVING clause, or in an ORDER BY clause where there is also a LIMIT).
Comment Actions
@Smalyshev could you point me to the code in blazegraph where the SERVICE wikibase:label function is implemented?