Try https://github.com/clemtoy/WNAffect on draftquality and report if it helps detect unambiguous advertising or promotion- G11 on https://en.wikipedia.org/wiki/Wikipedia:Criteria_for_speedy_deletion
Description
Description
Related Objects
Related Objects
- Mentioned In
- Blog Post: Status update (October 6, 2017)
Event Timeline
Comment Actions
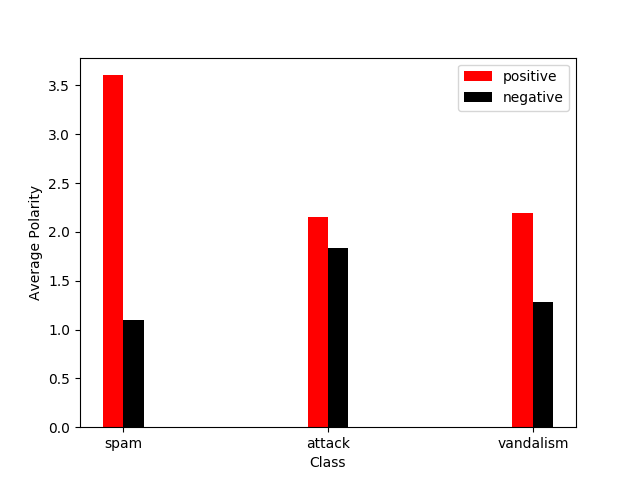
So I could setup a test with the library - https://github.com/kevincobain2000/sentiment_classifier/ that generates raw polarity scores for each document as an aggregate of positive and negative terms in the document. I used the https://github.com/wiki-ai/draftquality/blob/master/datasets/enwiki.draft_quality.75_not_OK_sample.censored.tsv and made the following observations:
The scores represent average polarity per document for each class:
| Spam | Attack | Vandalism | |
|---|---|---|---|
| Positive | 3.605 | 2.149 | 2.192 |
| Negative | 1.095 | 1.835 | 1.284 |
They show some promise for G11: Unambiguous advertising or promotion given the spike in first column
Comment Actions
Some dirty digging around performance, by profiling a script scoring long ( > 20) lines sentences:
Tue Jun 13 02:29:04 2017 stats
187782473 function calls (187763251 primitive calls) in 171.367 seconds
Ordered by: cumulative time
List reduced from 5493 to 50 due to restriction <50>
ncalls tottime percall cumtime percall filename:lineno(function)
1125/1 0.076 0.000 171.370 171.370 {built-in method builtins.exec}
1 0.000 0.000 171.370 171.370 emot.py:1(<module>)
1 0.000 0.000 168.748 168.748 emot.py:19(get_polarity)
2 0.000 0.000 168.740 84.370 /home/sumit/venv/lib/python3.6/site-packages/sentiment_classifier-0.7-py3.6.egg/senti_classifier/senti_classifier.py:234(polarity_scores)
2 0.006 0.003 168.740 84.370 /home/sumit/venv/lib/python3.6/site-packages/sentiment_classifier-0.7-py3.6.egg/senti_classifier/senti_classifier.py:202(classify)
1084 1.248 0.001 168.734 0.156 /home/sumit/venv/lib/python3.6/site-packages/sentiment_classifier-0.7-py3.6.egg/senti_classifier/senti_classifier.py:173(disambiguateWordSenses)
731495 0.795 0.000 152.014 0.000 /home/sumit/venv/lib/python3.6/site-packages/nltk/corpus/reader/wordnet.py:1547(path_similarity)
731495 2.020 0.000 151.219 0.000 /home/sumit/venv/lib/python3.6/site-packages/nltk/corpus/reader/wordnet.py:728(path_similarity)
731495 7.519 0.000 119.911 0.000 /home/sumit/venv/lib/python3.6/site-packages/nltk/corpus/reader/wordnet.py:658(shortest_path_distance)
1447733 34.959 0.000 102.647 0.000 /home/sumit/venv/lib/python3.6/site-packages/nltk/corpus/reader/wordnet.py:634(_shortest_hypernym_paths)From above, path_similarity and disambiguateWordSenses are the bottleneck which is understandable because for each word in the sentence, it takes each synset of the word and sums the path_similarity with every other word of the sentence to find the one with highest path_similarity score. See - disambiguateWordSenses and classify
We have two choices:
- Find better way to disambiguate senses quickly as we process sentence
- Restrict ourselves to a few starting words.
Comment Actions
Removing stop words or restricting sentence to [-1,+1] during disambiguation did not give significant improvement.
Next: take only the most dominant sense of the word and add its polarity score
Comment Actions
Most dominant word sense achieves tremendous improvement in computation, now taking only milliseconds. Now only need to verify if this assumption preserves our hypothesis related to sentiment of draft.
Comment Actions
Apologies if you've already covered this, but it might be helpful to also do a sentiment analysis of non-damaging edits, to determine our baseline?
Comment Actions
@awight yes, thats indeed necessary and thanks for pointing out! but as it turns out I could only work with the sample drafts mentioned above as the makefile would throw me "do not have permissions" error if I try to download the "deleted text" dataset. Can you benchmark those against the normal drafts and create a matrix probably? all the code is already in the PR and all thats needed is to run the utilities from https://github.com/wiki-ai/draftquality/blob/master/Makefile
Comment Actions
Finally, I have some progress to report. I've extracted the baseline feature list and the sentiment-laden feature list, and trained models on both, using the full set of c. 833k observations. The test_model jobs are running on labs, and should complete some time tomorrow.
Comment Actions
Here are the baseline model's statistics,
(.env)awight@ores-compute-01:/srv/awight/draftquality$ revscoring model_info test-wo-sentiment
ScikitLearnClassifier
- type: GradientBoosting
- params: learning_rate=0.01, loss="deviance", n_estimators=700, min_samples_leaf=1, min_samples_split=2, max_depth=7, balanced_sample_weight=false, warm_start=false, verbose=0, scale=false, random_state=null, max_leaf_nodes=null, max_features="log2", subsample=1.0, init=null, presort="auto", balanced_sample=false, center=false, min_weight_fraction_leaf=0.0
- version: 0.0.1
- trained: 2017-07-04T04:40:01.173744
Table:
~OK ~attack ~spam ~vandalism
--------- ----- --------- ------- ------------
OK 96654 5 395 70
attack 138 14 22 55
spam 850 1 1053 27
vandalism 445 19 74 178
Accuracy: 0.979
ROC-AUC:
----------- -----
'OK' 0.984
'attack' 0.985
'spam' 0.988
'vandalism' 0.97
----------- -----
F1:
--------- -----
spam 0.606
attack 0.104
OK 0.99
vandalism 0.34
--------- -----
Filter rate @ 0.75 recall:
label threshold filter_rate recall
----------- ----------- ------------- --------
'OK' 0.998 0.271 0.75
'attack' 0.032 0.986 0.751
'spam' 0.227 0.972 0.75
'vandalism' 0.063 0.975 0.75
Filter rate @ 0.9 recall:
label threshold filter_rate recall
----------- ----------- ------------- --------
'OK' 0.99 0.125 0.9
'attack' 0.011 0.972 0.904
'spam' 0.075 0.949 0.9
'vandalism' 0.014 0.944 0.901The model w/sentiment is forthcoming...
Comment Actions
Here are the long promised stats for a model trained with the sentiment patch,
bzcat datasets/enwiki.draft_quality.201508-201608.test.100k.with_cache.json.bz2 | \
revscoring test_model \
models/enwiki.draft_quality_with_sentiment.gradient_boosting.model \
--observations="<stdin>" \
draft_quality \
-s 'table' -s 'accuracy' -s 'roc' -s 'f1' \
-s 'filter_rate_at_recall(min_recall=0.75)' \
-s 'filter_rate_at_recall(min_recall=0.9)' > test-sentiment
2017-07-06 10:56:36,989 INFO:revscoring.utilities.test_model -- Testing model...
ScikitLearnClassifier
- type: GradientBoosting
- params: max_features="log2", presort="auto", warm_start=false, center=false, max_leaf_nodes=null, init=null, verbose=0, balanced_sample_weight=false, min_samples_leaf=1, scale=false, learning_rate=0.01, min_samples_split=2, balanced_sample=false, loss="deviance", min_weight_fraction_leaf=0.0, subsample=1.0, random_state=null, max_depth=7, n_estimators=700
- version: 0.0.1
- trained: 2017-07-04T11:37:58.707848
Table:
~OK ~attack ~spam ~vandalism
--------- ----- --------- ------- ------------
OK 96681 5 370 68
attack 138 16 17 58
spam 843 1 1059 28
vandalism 454 17 66 179
Accuracy: 0.979
ROC-AUC:
----------- -----
'OK' 0.984
'attack' 0.985
'spam' 0.988
'vandalism' 0.97
----------- -----
F1:
--------- -----
vandalism 0.341
OK 0.99
spam 0.615
attack 0.119
--------- -----
Filter rate @ 0.75 recall:
label threshold filter_rate recall
----------- ----------- ------------- --------
'OK' 0.998 0.271 0.75
'attack' 0.034 0.987 0.751
'spam' 0.233 0.973 0.75
'vandalism' 0.067 0.976 0.75
Filter rate @ 0.9 recall:
label threshold filter_rate recall
----------- ----------- ------------- --------
'OK' 0.99 0.125 0.9
'attack' 0.012 0.974 0.904
'spam' 0.077 0.951 0.9
'vandalism' 0.013 0.943 0.901Comment Actions
My patch to add the sentiment-laden feature list,
--- a/draftquality/feature_lists/enwiki.py +++ b/draftquality/feature_lists/enwiki.py @@ -192,5 +192,8 @@ sentiment_based = [ ] draft_quality = (char_based + token_based + parse_based + + badwords + informals + dict_words + local_wiki) + +draft_quality_with_sentiment = (char_based + token_based + parse_based + badwords + informals + dict_words + local_wiki + sentiment_based)
Comment Actions
@Halfak when you have time to review these results, ping me cos I want to learn how to debunk. For example, how would I tell that I haven't corrupted test data by training on it, or accidentally built both models on draft_quality without any sentiment features?
Comment Actions
I'd try this:
$ cd draftquality/ $ python Python 3.5.1+ (default, Mar 30 2016, 22:46:26) [GCC 5.3.1 20160330] on linux Type "help", "copyright", "credits" or "license" for more information. >>> from revscoring import ScorerModel >>> sm = ScorerModel.load(open("models/enwiki.draft_quality.gradient_boosting.model")) >>> sm.features (<feature.wikitext.revision.chars>, <feature.wikitext.revision.whitespace_chars>, <feature.wikitext.revision.markup_chars>, <feature.wikitext.revision.cjk_chars>, <feature.wikitext.revision.entity_chars>, <feature.wikitext.revision.url_chars>, <feature.wikitext.revision.word_chars>, <feature.wikitext.revision.uppercase_word_chars>, <feature.wikitext.revision.punctuation_chars>, <feature.wikitext.revision.break_chars>, <feature.wikitext.revision.longest_repeated_char>, <feature.(wikitext.revision.whitespace_chars / max(wikitext.revision.chars, 1))>, <feature.(wikitext.revision.markup_chars / max(wikitext.revision.chars, 1))>, <feature.(wikitext.revision.cjk_chars / max(wikitext.revision.chars, 1))>, <feature.(wikitext.revision.entity_chars / max(wikitext.revision.chars, 1))>, <feature.(wikitext.revision.url_chars / max(wikitext.revision.chars, 1))>, <feature.(wikitext.revision.word_chars / max(wikitext.revision.chars, 1))>, <feature.(wikitext.revision.uppercase_word_chars / max(wikitext.revision.chars, 1))>, <feature.(wikitext.revision.punctuation_chars / max(wikitext.revision.chars, 1))>, <feature.(wikitext.revision.break_chars / max(wikitext.revision.chars, 1))>, <feature.(wikitext.revision.longest_repeated_char / max(wikitext.revision.chars, 1))>, <feature.len(<datasource.tokenized(datasource.revision.text)>)>, <feature.len(<datasource.wikitext.revision.numbers>)>, <feature.len(<datasource.wikitext.revision.whitespaces>)>, <feature.len(<datasource.wikitext.revision.markups>)>, <feature.len(<datasource.wikitext.revision.cjks>)>, <feature.len(<datasource.wikitext.revision.entities>)>, <feature.len(<datasource.wikitext.revision.urls>)>, <feature.len(<datasource.wikitext.revision.words>)>, <feature.len(<datasource.wikitext.revision.uppercase_words>)>, <feature.len(<datasource.wikitext.revision.punctuations>)>, <feature.len(<datasource.wikitext.revision.breaks>)>, <feature.max(<datasource.map(<built-in function len>, <datasource.tokenized(datasource.revision.text)>)>)>, <feature.max(<datasource.map(<built-in function len>, <datasource.wikitext.revision.words>)>)>, <feature.(len(<datasource.wikitext.revision.numbers>) / max(len(<datasource.tokenized(datasource.revision.text)>), 1))>, <feature.(len(<datasource.wikitext.revision.whitespaces>) / max(len(<datasource.tokenized(datasource.revision.text)>), 1))>, <feature.(len(<datasource.wikitext.revision.markups>) / max(len(<datasource.tokenized(datasource.revision.text)>), 1))>, <feature.(len(<datasource.wikitext.revision.cjks>) / max(len(<datasource.tokenized(datasource.revision.text)>), 1))>, <feature.(len(<datasource.wikitext.revision.entities>) / max(len(<datasource.tokenized(datasource.revision.text)>), 1))>, <feature.(len(<datasource.wikitext.revision.urls>) / max(len(<datasource.tokenized(datasource.revision.text)>), 1))>, <feature.(len(<datasource.wikitext.revision.words>) / max(len(<datasource.tokenized(datasource.revision.text)>), 1))>, <feature.(len(<datasource.wikitext.revision.uppercase_words>) / max(len(<datasource.tokenized(datasource.revision.text)>), 1))>, <feature.(len(<datasource.wikitext.revision.punctuations>) / max(len(<datasource.tokenized(datasource.revision.text)>), 1))>, <feature.(len(<datasource.wikitext.revision.breaks>) / max(len(<datasource.tokenized(datasource.revision.text)>), 1))>, <feature.(max(<datasource.map(<built-in function len>, <datasource.tokenized(datasource.revision.text)>)>) / max(len(<datasource.tokenized(datasource.revision.text)>), 1))>, <feature.(max(<datasource.map(<built-in function len>, <datasource.wikitext.revision.words>)>) / max(len(<datasource.tokenized(datasource.revision.text)>), 1))>, <feature.wikitext.revision.content_chars>, <feature.wikitext.revision.headings>, <feature.wikitext.revision.external_links>, <feature.wikitext.revision.wikilinks>, <feature.wikitext.revision.tags>, <feature.wikitext.revision.ref_tags>, <feature.wikitext.revision.templates>, <feature.(wikitext.revision.content_chars / max(len(<datasource.tokenized(datasource.revision.text)>), 1))>, <feature.(wikitext.revision.headings / max(len(<datasource.tokenized(datasource.revision.text)>), 1))>, <feature.(wikitext.revision.external_links / max(len(<datasource.tokenized(datasource.revision.text)>), 1))>, <feature.(wikitext.revision.wikilinks / max(len(<datasource.tokenized(datasource.revision.text)>), 1))>, <feature.(wikitext.revision.tags / max(len(<datasource.tokenized(datasource.revision.text)>), 1))>, <feature.(wikitext.revision.ref_tags / max(len(<datasource.tokenized(datasource.revision.text)>), 1))>, <feature.(wikitext.revision.templates / max(len(<datasource.tokenized(datasource.revision.text)>), 1))>, <feature.len(<datasource.english.badwords.revision.matches>)>, <feature.(len(<datasource.english.badwords.revision.matches>) / max(len(<datasource.wikitext.revision.words>), 1))>, <feature.len(<datasource.english.informals.revision.matches>)>, <feature.(len(<datasource.english.informals.revision.matches>) / max(len(<datasource.wikitext.revision.words>), 1))>, <feature.len(<datasource.english.dictionary.revision.dict_words>)>, <feature.len(<datasource.english.dictionary.revision.non_dict_words>)>, <feature.(len(<datasource.english.dictionary.revision.dict_words>) / max(len(<datasource.wikitext.revision.words>), 1))>, <feature.(len(<datasource.english.dictionary.revision.non_dict_words>) / max(len(<datasource.wikitext.revision.words>), 1))>, <feature.enwiki.revision.image_links>, <feature.(enwiki.revision.image_links / max(wikitext.revision.content_chars, 1))>, <feature.enwiki.revision.category_links>, <feature.(enwiki.revision.category_links / max(wikitext.revision.content_chars, 1))>, <feature.enwiki.revision.cite_templates>, <feature.(enwiki.revision.cite_templates / max(wikitext.revision.content_chars, 1))>, <feature.(enwiki.revision.cite_templates / max(wikitext.revision.ref_tags, 1))>, <feature.max((wikitext.revision.ref_tags - enwiki.revision.cite_templates), 0)>, <feature.(max((wikitext.revision.ref_tags - enwiki.revision.cite_templates), 0) / max(wikitext.revision.content_chars, 1))>, <feature.enwiki.revision.non_cite_templates>, <feature.(enwiki.revision.non_cite_templates / max(wikitext.revision.content_chars, 1))>, <feature.enwiki.revision.infobox_templates>, <feature.enwiki.revision.cn_templates>, <feature.(enwiki.revision.cn_templates / max(wikitext.revision.content_chars, 1))>, <feature.enwiki.revision.cn_templates>, <feature.(enwiki.revision.cn_templates / max(wikitext.revision.content_chars, 1))>, <feature.enwiki.main_article_templates>, <feature.(enwiki.main_article_templates / max(wikitext.revision.content_chars, 1))>, <feature.(english.stemmed.revision.stems_length / max(wikitext.revision.content_chars, 1))>)
Do that for both models and you should see a difference that will confirm that the model was in fact trained on new features.
Comment Actions
Verified that the with_sentiment model includes <feature.positive_polarity>, <feature.negative_polarity>, <feature.diff_polarity> and without sentiment doesn't include them.
Is this the "surprising" turn of events, in which case we should investigate further?
Another very likely possibility is that I just didn't read the test stats correctly.
Comment Actions
Here's what I got. It roughly matches Adama's 2nd model. But one surprising bit that I've only noticed now is that we're better at attack pages than we were before. This might be worth merging.
Table:
~OK ~attack ~spam ~vandalism
--------- ------ --------- ------- ------------
OK 877115 57 3324 658
attack 1104 200 184 571
spam 8182 8 9271 238
vandalism 4074 185 638 1606
Accuracy: 0.979
ROC-AUC:
----------- -----
'OK' 0.984
'attack' 0.982
'spam' 0.988
'vandalism' 0.97
----------- -----
F1:
--------- -----
OK 0.99
attack 0.159
vandalism 0.335
spam 0.596
--------- -----
Filter rate @ 0.75 recall:
label threshold filter_rate recall
----------- ----------- ------------- --------
'OK' 0.998 0.271 0.75
'attack' 0.037 0.987 0.752
'spam' 0.204 0.971 0.75
'vandalism' 0.062 0.975 0.751
Filter rate @ 0.9 recall:
label threshold filter_rate recall
----------- ----------- ------------- --------
'OK' 0.99 0.125 0.9
'attack' 0.011 0.971 0.902
'spam' 0.068 0.948 0.9
'vandalism' 0.011 0.936 0.901