@AVasanth_WMF just got an error when confirming OAUTH on login.
He got the puppy error screen (not sure which that is), and already had an account on the platform. Will do some further debugging.
| Samwalton9-WMF | |
| Jun 13 2017, 5:33 PM |
| F31057263: no-session-token.png | |
| Nov 7 2019, 5:22 PM |
@AVasanth_WMF just got an error when confirming OAUTH on login.
He got the puppy error screen (not sure which that is), and already had an account on the platform. Will do some further debugging.
Just popped in over my lunch. That's a 500 error, not seeing anything specific to that user account in the logs.
Looks like we failed during the oauth callback. @AVasanth_WMF's account looks totally correct, so I'm thinking it was not particular to this user. Because of the way we pause in the middle of the oauth exchanges, it's possible that it was something silly like a token expiration. Which might happen if a user sat at the login page for a while. @AVasanth_WMF, were you already logged in to meta when this error occurred, or were you prompted to sign in?
@AVasanth_WMF Looks like there was something hinky with your numeric account id migration. Can you try logging in with @AVasanth_WMF again?
When I click sing up/log in (top right) it no longer takes me to confirm my OAuth, rather directly takes me to the error 500. I tried clearing cache/cookies and also tried logging out and back in of my Wikimedia account. URL: https://wikipedialibrary.wmflabs.org/oauth/callback/?oauth_verifier=463a91d5286bd8c790b0cf98d913f928&oauth_token=9d350146b076c9569c52eeacb740ff32
I was thinking this was down to a mistake in the migration to global accounts. But now I'm thinking not.
The short version of what I did troubleshooting. checked your global userid:
https://www.mediawiki.org/w/api.php?action=query&meta=globaluserinfo&guiuser=AVasanth%20(WMF)
this is what we had in the platform already
then I checked your local meta userid:
https://meta.wikimedia.org/w/api.php?action=query&list=users&ususers=AVasanth%20(WMF)
and plugged that value in.
When you tried to log in again, it created a stub account under the global id. Basically, if we were not using the correct identifier, this would have sussed that out.
I deleted the stub account and remapped your wikipedia library account to the global id.
basically, we're stepping into
_get_and_update_user_from_identity
and not throwing errors for any of the things we check for.
But we're also not completing the user.save that needs to happen for successful login to the platform.
Thus the generic 500 error.
I'm going to do some research and add some debug code to our staging environment in several hours, where I'd like you to try logging in once I've got it ready. I'll post the details here.
@AVasanth_WMF I'm able to replicate this in staging with my WMF account, but not my regular account. I'll update when I believe I have it resolved and have you retest.
I believe this may be related to spaces in the username, but I'm not certain about that. @Samwalton9 can you test with your WMF account?
Confirmed that I get the error on my WMF account and not my normal one.
Also tested "Samwalton9 is testing" and got the error.
@Samwalton9 @AVasanth_WMF issue should be resolved in all environments, but please test.
The immediate problem:
I wasn't properly encoding the username when making the api call for global userinfo. It wasn't a dangerous mistake because of how I'm assembling the api call, but it could cause failures like this.
The immediate fix:
encoding the username as url form data
The slightly larger problem:
Our authorization code was previously too lax. I have now tightened things up considerably to the point where if we're not certain about a user, we always error out. In this case, the api call that was failing was just the call for global edit count. We should probably allow users to finish logging in when we're unable to get valid results from that call and just return an empty count for new users and not update the count for existing users. In other situations where we error out, we'll need to return much more appropriate messages via T167194
Additional followup task for me:
I burned several hours troubleshooting this, because their was so little information in the logs. I'll add some logger calls following each api call so I can have better visibility into what pieces of code have and haven't executed successfully.
^ Created a task for the api call. Want a phab task for the logging, or are you planning to do it shortly?
It looks like we're not getting a request_token from the oauth initialization. Upon researching this further, it looks like there are several ways in which the mediawiki oauth implementation deviates from standards, and it also appears to have some limitations in dealing with unicode data from service providers. It looks like there are situations in which initialization will silently fail for non-english users due to one of these unicode issues. We use the mwoauth package as a shim that works around many of these issues, and it looks like they released an update 5 days ago that might fix this particular issue. The update is currently wending its way through the deployment pipeline
REPOST (minus potentially sensitive info.)
This issue seemed to have cropped up, not necessarily for the same reasons as above, but for a real user this time.
Traceback: File "/venv/lib/python2.7/site-packages/django/core/handlers/exception.py" in inner 41. response = get_response(request) File "/venv/lib/python2.7/site-packages/django/core/handlers/base.py" in _legacy_get_response 249. response = self._get_response(request) File "/venv/lib/python2.7/site-packages/django/core/handlers/base.py" in _get_response 187. response = self.process_exception_by_middleware(e, request) File "/venv/lib/python2.7/site-packages/django/core/handlers/base.py" in _get_response 185. response = wrapped_callback(request, *callback_args, **callback_kwargs) File "/venv/lib/python2.7/site-packages/django/views/generic/base.py" in view 68. return self.dispatch(request, *args, **kwargs) File "/venv/lib/python2.7/site-packages/django/views/generic/base.py" in dispatch 88. return handler(request, *args, **kwargs) File "/app/TWLight/users/authorization.py" in get 384. request_token = _rehydrate_token(session_token) File "/app/TWLight/users/authorization.py" in _rehydrate_token 75. request_token = ConsumerToken(token['key'], token['secret']) Exception Type: TypeError at /oauth/callback/ Exception Value: 'NoneType' object has no attribute '__getitem__' Request information: USER: **********
@AVasanth_WMF It looks like this is impacting you directly? Does this only happen intermittently? I set my client settings to be as similar to yours as possible (language set to en-GB, tried both WMF and personal handles) and was not able to reproduce. Clearly a problem is occurring as evidenced by your reports and the error logs. If the issue is intermittent, I suspect that it's due to meta not completing the oauth process occasionally, or perhaps a network interruption. Your browser is what makes the requests between the Oauth IdP on meta and the Oauth SP on twl (eg. there is no backend server <-> server communication for this part of the process). Do you have any interesting browser configuration that you could turn off for a while? or have you been experiencing intermittent network problems?
@jsn.sherman this hasn't happened to me recently, no. From the logs in the email, last this happened was to a user at 6 Nov 2019 20:46:24 +0000 if that helps?
It *looks* like this is from a user trying to complete an oauth process that got interrupted midway through. That can happen a few ways:
Given that these are all potentially common scenarios, I've pushed a hotfix that should catch this issue and give the user a warning message instead of a 500 error. It's in the deployment pipeline now
Verified that we no longer dump users out to a 500 error in this circumstance. Now we throw a 403 with a warning message:
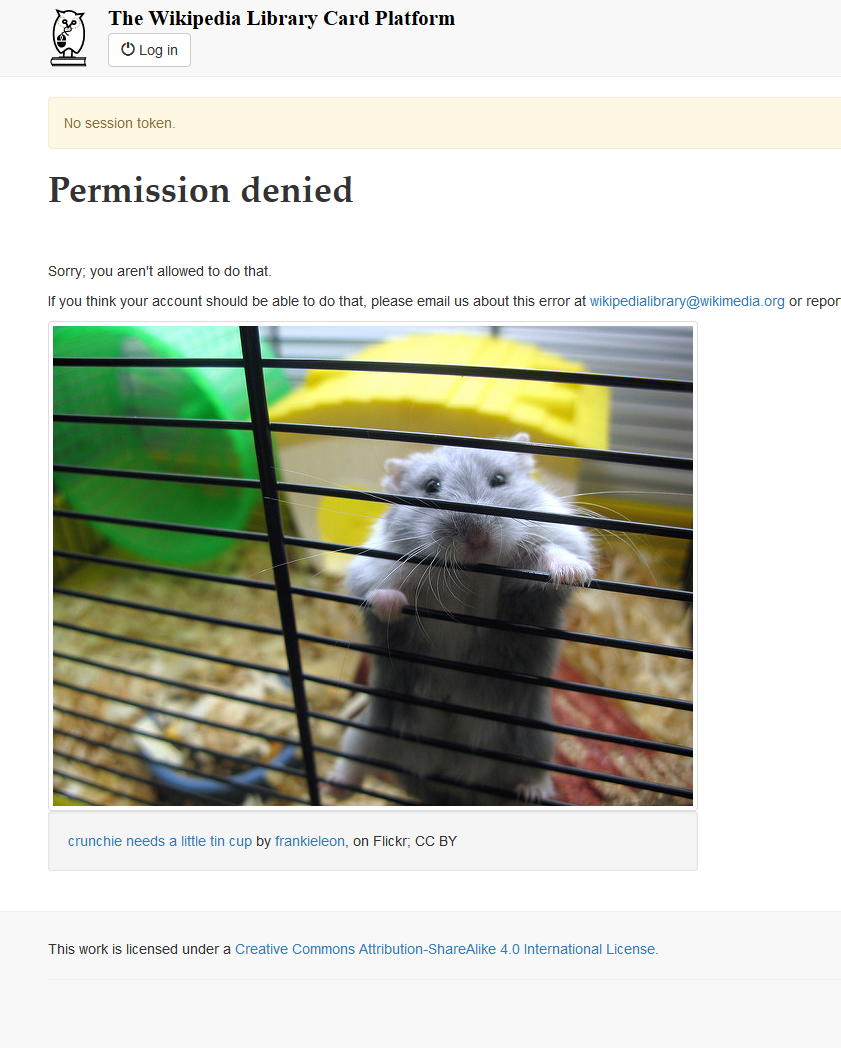
I'm going to close this issue out. The underlying cause (that we can't complete the oauth process when it gets interrupted) isn't really resolvable, but we are now doing something more useful than letting an exception whiz by uncaught and sending users to a generic 500 error.