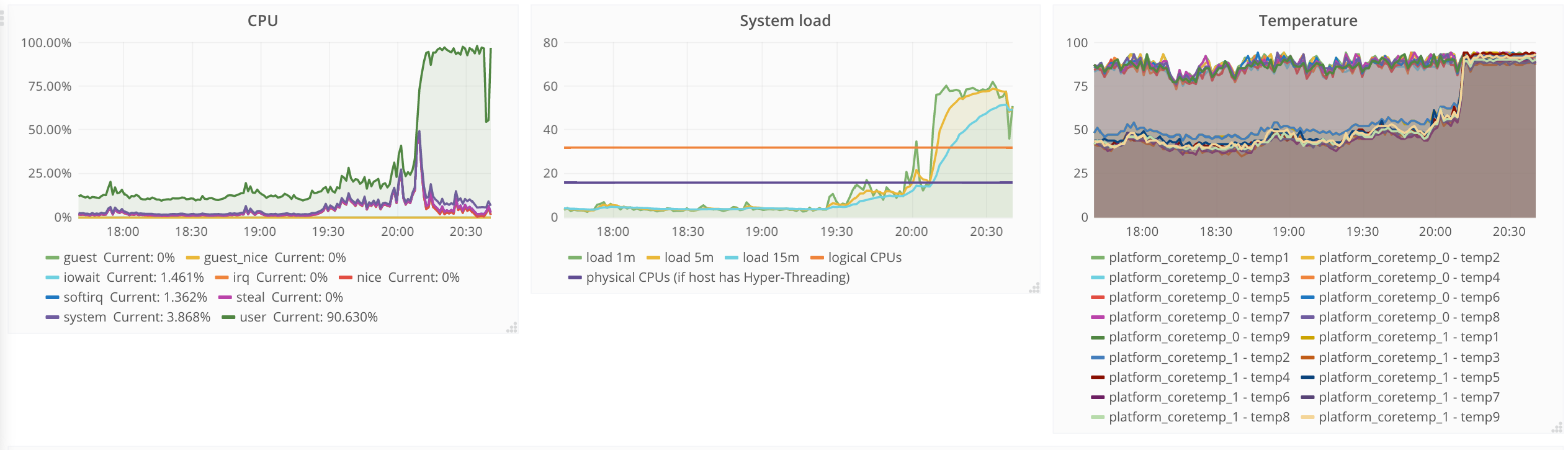
elastic1017.eqiad.wmnet shutdown on its own Saturday June 24 08:21. Looking at kern.log I see a number of "Package temperature above threshold, cpu clock throttled" which indicate overheating. A quick look with cumin (see log below) indicates that a number of the older elasticsearch servers have similar behaviour, even if not as bad as elastic1017. The following servers have a non zero count of "Package temperature above threshold" in kern.log:
- elastic1017
- elastic[1019-1020]
- elastic[1023-1026]
It might make sense to reapply thermal paste on elastic1017-elastic1031 (the oldest batch of elasticsearch servers).
@Cmjohnson what do you think? Should we do it? Should we do the whole batch or just the ones which are exposing the issue? Ping me to arrange a schedule to take those servers down if needed. We can easily take 4 of them down at the same time, but it takes some time for the cluster to recover between 2 groups.
gehel@neodymium:~$ sudo cumin 'elastic*.wmnet' 'grep "Package temperature above threshold" /var/log/kern.log | wc -l' 72 hosts will be targeted: elastic[2001-2036].codfw.wmnet,elastic[1017-1052].eqiad.wmnet Confirm to continue [y/n]? y ===== NODE GROUP ===== (1) elastic1025.eqiad.wmnet ----- OUTPUT of 'grep "Package te...kern.log | wc -l' ----- 4223 ===== NODE GROUP ===== (1) elastic1020.eqiad.wmnet ----- OUTPUT of 'grep "Package te...kern.log | wc -l' ----- 173 ===== NODE GROUP ===== (1) elastic1019.eqiad.wmnet ----- OUTPUT of 'grep "Package te...kern.log | wc -l' ----- 4286 ===== NODE GROUP ===== (65) elastic[2001-2036].codfw.wmnet,elastic[1018,1021-1022,1027-1052].eqiad.wmnet ----- OUTPUT of 'grep "Package te...kern.log | wc -l' ----- 0 ===== NODE GROUP ===== (1) elastic1017.eqiad.wmnet ----- OUTPUT of 'grep "Package te...kern.log | wc -l' ----- 19611 ===== NODE GROUP ===== (1) elastic1023.eqiad.wmnet ----- OUTPUT of 'grep "Package te...kern.log | wc -l' ----- 30 ===== NODE GROUP ===== (1) elastic1024.eqiad.wmnet ----- OUTPUT of 'grep "Package te...kern.log | wc -l' ----- 155 ===== NODE GROUP ===== (1) elastic1026.eqiad.wmnet ----- OUTPUT of 'grep "Package te...kern.log | wc -l' ----- 4189 ================ PASS |███████████████████████| 100% (72/72) [00:00<00:00, 83.64hosts/s] FAIL | | 0% (0/72) [00:00<?, ?hosts/s] 100.0% (72/72) success ratio (>= 100.0% threshold) for command: 'grep "Package te...kern.log | wc -l'. 100.0% (72/72) success ratio (>= 100.0% threshold) of nodes successfully executed all commands.