Create an API that does the following:
- Gets ALL Reference Lists from a page
- Returns a structured lists of references, complete with the section headers that the references were contained in
- If some text appears at the top or bottom of a reference list within reference section, return it within the structure for the section
References will be used in 2 contexts:
- A popup (as seen now in mobile web and ops)
- A list (similar to references sections at the end of an article)
Proposed popup for desktop:
 | 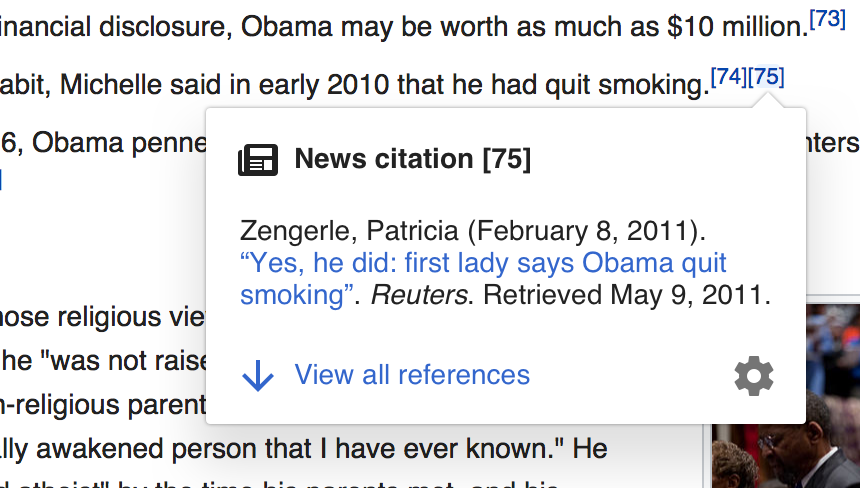 |  |
Proposed list for desktop:
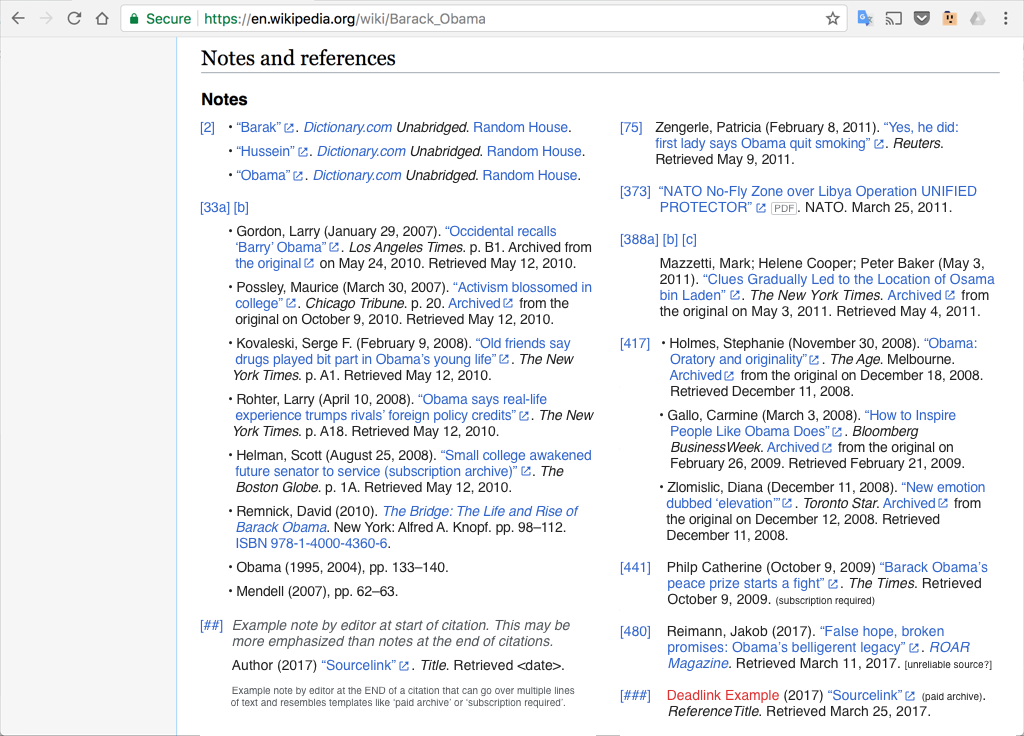
Example application of list as a popover:

Example application of 'grouped' citation pop-up:
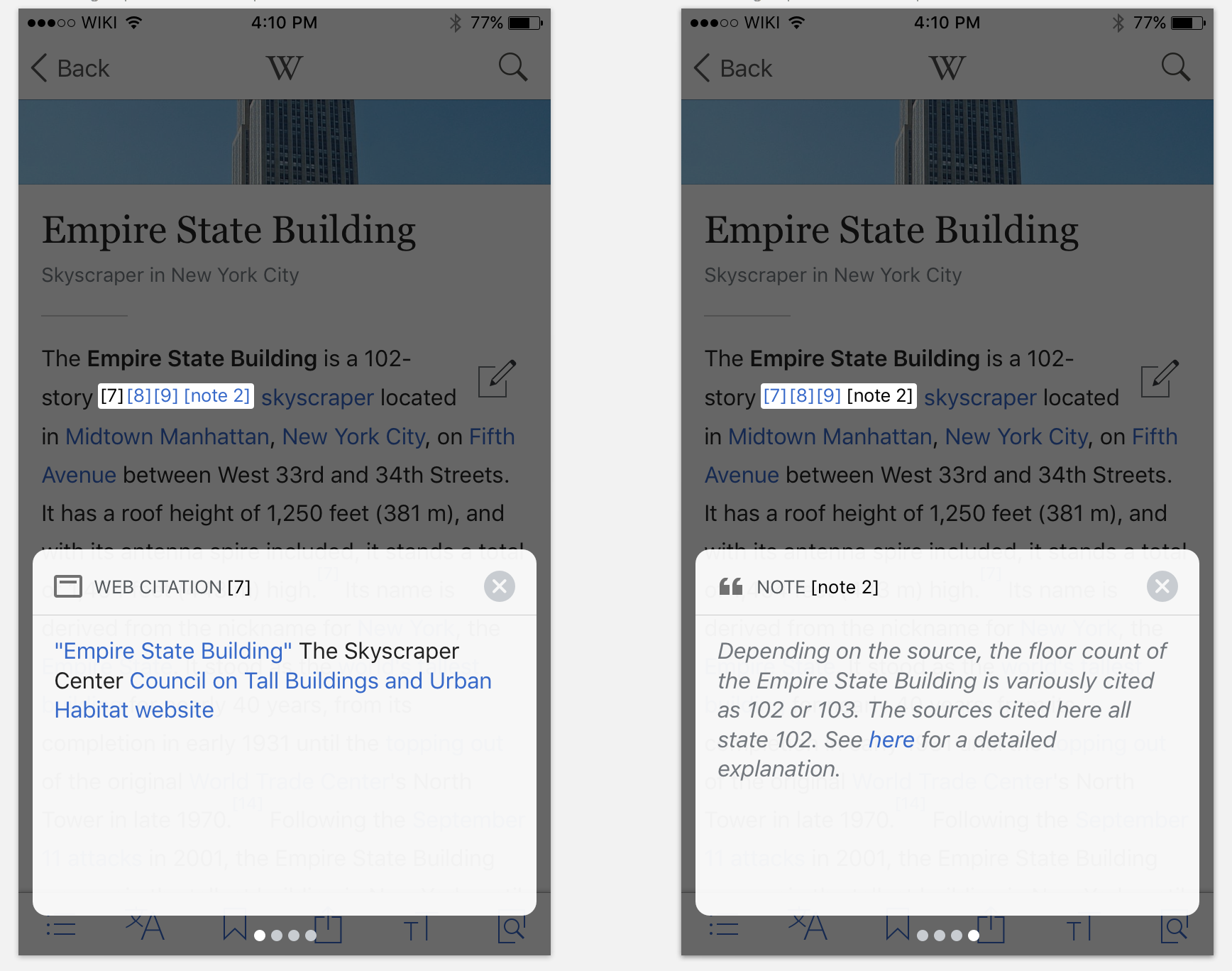
See proposed data structure outlined in the doc:
https://docs.google.com/presentation/d/19EC_6kOYREwwC9Fieme_CcKQaT-X13Ks4IkGqR6vFFI/edit#slide=id.g2546c2693e_0_99
[pertinent slides are from 6-13]
