We want to get rid of the current maps-test cluster on real hardware in the production zone, and replace it with a test cluster running on our cloud. See T171746 for the rational.
Description
Description
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Resolved | MSantos | T152196 Kartotherian snapshots always return low DPI images | |||
| Resolved | Gehel | T198622 migrate maps servers to stretch with the current style | |||
| Resolved | • Mholloway | T198485 Verify loading instructions for existing styles on Stretch | |||
| Resolved | • Mholloway | T172090 move maps-test cluster to cloud infrastructure | |||
| Resolved | debt | T171746 Determining the plan for the maps-test cluster |
Event Timeline
Comment Actions
We need to determine the sizing needed for a maps test cluster on WMCS. Here are a few idea, to be discussed with @Pnorman. Once we agree, we can send that proposal to the WMCS team (anyone is welcomed to patricipate before that, just understand this is work in progress).
note 1
Splitting the different maps components to different VMs makes more sense in our opinion. It makes it easier to ensure that separation of concern is clear, easier to experiment on a subset of the components (for example, we could start a new WM to test a specific branch of Kartotherian, while using the same Postgresql and Cassandra).
note 2
There is a question on the IOPs available on WMCS. @Pnorman's recommendation would be to have 1k IOPs available, I'm unsure if that is possible on labs. The functionalities most impacted by slow IOPs will be:
- initial data import
- OSM replication
- tile pregeneration
Since those operations are asynchronous and we are planning to work on a small subset of OSM data, slower IOPs will probably not be an issue.
absolute minimum
This is sufficient to test application functionalities, with a minimal dataset and minimal performance.
- 1x Postgresql (m1.medium: 2 CPU, 4GB RAM, 40GB Disk)
- 1x Cassandra (m1.medium: 2 CPU, 4GB RAM, 40GB Disk)
- 1x Apps (m1.small: 1 CPU, 2GB RAM, 20GB Disk)
Total: 5 CPU, 10GB RAM, 100GB Disk
clustering test
This allow to also test things related the Postgresql / Cassandra replication
- 2x Postgresql (m1.medium: 2 CPU, 4GB RAM, 40GB Disk)
- 2x Cassandra (m1.medium: 2 CPU, 4GB RAM, 40GB Disk)
- 1x Apps (m1.small: 1 CPU, 2GB RAM, 20GB Disk)
Total: 9 CPU, 18GB RAM, 180GB Disk
full dataset option
This would allow to have a full dataset, and reasonable performances. This option would allow much more complete testing, but the cost in term of resources is probably not worth the added benefit.
- 2x Postgresql (8CPU, 32GB RAM, 1TB Disk)
- 2x Cassandra (8CPU, 16BG RAM, 500TB Disk)
- 1x Apps (m1.small: 1 CPU, 2GB RAM, 20GB Disk)
Total: 33 CPU, 98GB RAM, 3TB Disk
@Pnorman: do the options above looks reasonable to you? Any comment?
Comment Actions
The disk amounts for the first two are probably more than we need, but given CPU and RAM amounts, we're probably going to end up overprovisioned on space.
We do need adequate iops, as it's the biggest factor in determining how long anything takes.
The loading scripts will need to differ between prod and test, because some of the options used for the full planet will not be used for a small extract.
Comment Actions
I think this task should be done to help maintainability (testability) of the maps codebase.
It seems to be mostly operations with no or minimal involvement from the dev team. Not sure who would prioritize it.
Comment Actions
While this is definitely something that is more operations than dev, it could be done by anyone with a limited understanding of puppet. Some projects have the dev team fully managing the test environment.
That being said, this is something I should be looking into. Having a dev team needing a test environment (which wasn't the case until recently) is raising the priority of this task in my personal todo list!
Comment Actions
We now have a maps instance on deployment-prep (deployment-maps03) thanks to @Catrope. We still need to kill the current maps-test servers which are end of life.
deployment-maps03 only has a subset of data, which limits our testing abilities (the production instances have 1.4TB of data space, of which ~800GB are used, ~600GB for postgres, ~200GB for cassandra). I can see the following solutions:
- Live with only the subset of data. This might be the right solution if maps moves back to maintenance mode, with only minimal changes. This is the current plan.
- Request additional space on labs. 1.4TB of space in labs is not something we usually do and brings a few problems and delays.
- Request new servers to host a full data set in production. This was not budgeted, so we need to be either creative or plan this for next fiscal year (2019-2020).
Comment Actions
I had to powercycle maps-test2003 twice in the last week. I have not investigated further, since we should really decommission this server. This raises the priority of this task a bit.
Comment Actions
deployment-maps04 is up and running (many thanks to @Krenair for the assistance with that!) but the services are failing to start because of an error in node-mapnik:
/srv/deployment/kartotherian/deploy-cache/revs/3aa87ff5e3b3d81ea5e4dda39b331350f1174f59/node_modules/mapnik/lib/binding/node-v48-linux-x64/mapnik.node: undefined symbol: _ZN6mapnik14save_to_stringINS_5imageINS_7rgba8_tEEEEESsRKT_RKSsRKNS_12rgba_paletteE
Comment Actions
This is an error from a mismatch between a node-mapnik compiled binary and the mapnik library it's linking against. The only Mapnik we should have is the 3.5.x version we compile.
Comment Actions
Note that in T198828 we discovered that we are pulling in both 3.5.14 and 3.6.2. We shouldn't be pulling in the latter.
Comment Actions
The issue with multiple node-mapnik versions is resolved and the services are up and running on deployment-maps04. Next step is to get the data loaded.
Comment Actions
Here are the map data PBFs located in /srv/downloads on the existing Jessie maps testing instance on deployment-maps03:
mholloway-shell@deployment-maps03:/srv$ ls -l downloads total 3531816 -rw-r--r-- 1 osmupdater osmupdater 1367177170 Apr 12 17:50 be-cn-gr-il-ps-ch.pbf -rw-r--r-- 1 osmupdater osmupdater 917046515 Apr 13 18:06 be-gr-il-ps-ch.pbf -rw-r--r-- 1 osmupdater osmupdater 328490916 Mar 28 20:01 belgium-latest.osm.pbf -rw-r--r-- 1 osmupdater osmupdater 436111580 Apr 10 23:01 china-latest.osm.pbf -rw-r--r-- 1 osmupdater osmupdater 171095173 Apr 10 23:58 greece-latest.osm.pbf -rw-r--r-- 1 osmupdater osmupdater 72414770 Mar 29 17:13 israel-and-palestine-latest.osm.pbf -rw-r--r-- 1 osmupdater osmupdater 324215325 Mar 28 20:02 switzerland-latest.osm.pbf
be-cn-gr-il-ps-ch.pbf and be-gr-il-ps-ch.pbf appear to be consolidated data files generated from the individual country files. I can't find any record of how these countries were chosen, but I am guessing that it was for linguistic variation in the service of the i18n work.
We know that we'll be similarly limited to a subset of the full planet data on the new Stretch testing instance on deployment-maps04. Should we load the same country data for consistency's sake? Any reason to change?
Comment Actions
For posterity: going with the same data (latest versions) for deployment-maps04.
Edit: Ended up going with just Belgium, Switzerland, Israel and Palestine because I was running out of space otherwise.
Comment Actions
It's probably worth a status update here.
We now have two maps testing instances in the beta cluster: deployment-maps03 and deployment-maps04. Both have map data loaded and the latest kartotherian and tilerator code deployed, and neither of them is currently working correctly.
deployment-maps03 was set up during the Map Improvements 2018 project and is running Debian Jessie. It has code deployed from the master branches of the /package and /deploy repos. On startup the kartotherian and tilerator services are currently exhibiting the error described in T196141, which in that instance was thought to be caused by not having a v3 keyspace present and properly configured in Cassandra; but deployment-maps03 has a v3 keyspace and its configuration looks sane.
deployment-maps04 was recently launched, runs Debian Stretch, and has code deployed from the stretch branches of /package and /deploy. I am currently running into an error when attempting to create the v3 keyspace. Interestingly, the kartotherian and tilerator services start up and run without issue despite the absence of a v3 keyspace.
Comment Actions
The error mentioned could be related to this step on OSM configuration, which configures GRANT settings for the user that access Postgres DB.
If that is not the case you should consider a misconfiguration with your create-sources.yaml. You might need to add extra credential configurations to fix database access for both Cassandra and Postgres, see examples:
https://github.com/wikimedia/puppet/blob/production/modules/profile/templates/maps/sources.yaml.erb#L9
https://github.com/mateusbs17/gisdock/blob/master/kartotherian/sources.docker.yaml#L8
https://github.com/mateusbs17/gisdock/blob/master/kartotherian/sources.docker.yaml#L31
And update your config.yaml file variables for the credential configurations, like this.
Interestingly, the kartotherian and tilerator services start up and run without issue despite the absence of a v3 keyspace.
I have noticed this too. The server runs but no tile is served.
Comment Actions
I had indeed skipped a permissions granting step. Performing the steps described in https://wikitech.wikimedia.org/wiki/Maps/ClearTables/Loading#Database_setup before loading the data solved the issue. (Note: I had to adjust permissions again after adding water polygons, and I've updated https://wikitech.wikimedia.org/wiki/Maps#Importing_database to reflect that).
Keyspace creation (as described in https://wikitech.wikimedia.org/wiki/Maps#Manual_steps) still failed, and I think it was because only the default cassandra user was set up. I tried performing the "Setup of user access / rights for cassandra" step in https://wikitech.wikimedia.org/wiki/Maps#Manual_steps to add the user, but that failed also (see output). In the course of trying to fix that, I removed cassandra with apt and deleted all associated directories, then reinstalled via puppet, and now cassandra won't start.
mholloway-shell@deployment-maps04:~$ sudo service cassandra status ● cassandra.service - distributed storage system for structured data Loaded: loaded (/lib/systemd/system/cassandra.service; static; vendor preset: enabled) Active: inactive (dead) Aug 01 14:34:28 deployment-maps04 systemd[1]: cassandra.service: Unit entered failed state. Aug 01 14:34:28 deployment-maps04 systemd[1]: cassandra.service: Failed with result 'exit-code'. Aug 01 14:35:13 deployment-maps04 systemd[1]: Started distributed storage system for structured data. Aug 01 14:45:40 deployment-maps04 systemd[1]: Stopping distributed storage system for structured data... Aug 01 14:45:43 deployment-maps04 systemd[1]: cassandra.service: Main process exited, code=exited, status=143/n/a Aug 01 14:45:43 deployment-maps04 systemd[1]: Stopped distributed storage system for structured data. Aug 01 14:45:43 deployment-maps04 systemd[1]: cassandra.service: Unit entered failed state. Aug 01 14:45:43 deployment-maps04 systemd[1]: cassandra.service: Failed with result 'exit-code'. Aug 01 14:49:03 deployment-maps04 systemd[1]: Started distributed storage system for structured data. Aug 01 14:49:28 deployment-maps04 systemd[1]: Started distributed storage system for structured data.
I can't find any logs (/var/log/cassandra is empty), so I'm not sure yet how to go about fixing this.
Comment Actions
deployment-maps03 error:
This is quite an odd problem. It doesn't have a date/time pattern, so it's not related to data loading or any kind of osm sync. Also, T196141 is related to the new styles and has been reported to the tilelive-tmstyle project, and it happens because the library can't extract the vector_layers from the source, which is loaded by osm-bright.tm2. The current style uses tilejson data structure to define which vector_layers should be loaded and the config file is published at https://maps.wikimedia.org/osm-pbf/info.json.
My theory is that sometimes info.json is unreachable and then kartotherian gets a undefined object. I don't know how to confirm this theory yet.
Comment Actions
deployment-maps04 (the Stretch instance) is up and running. I'll create a new Beta Cluster loading doc to help anyone setting up Beta Cluster instances in the future avoid the gotchas I ran into. One thing worth mentioning here is that I had problems with the osm2pgsql process getting OOM killed when attempting to load even a relatively small amount of data. Ultimately I ended up loading only Israel and Palestine (based on the small size of the data set) just to get the instance up and running.
Comment Actions
New Wikitech page documenting Beta Cluster maps instance setup: https://wikitech.wikimedia.org/wiki/Maps/Beta_Cluster_setup
Comment Actions
Fixed deployment-maps03 by dropping and re-creating the v3 keyspace. Running tileshell to regenerate some tiles now.
Comment Actions
So beta cluster is now using the labs instance? Or is there more to do.
@Mholloway Can you add an update to https://www.mediawiki.org/wiki/Wikimedia_Maps in a new August section?
Comment Actions
@Jhernandez I updated the wiki.
The Beta Cluster (i.e., the deployment-prep project in WMCS) now contains a new deployment-maps04 instance running Stretch, in addition to the deployment-maps03 instance running Jessie. The Beta Cluster wikis request map data from https://maps-beta.wmflabs.org/, which is configured in Horizon to proxy to deployment-maps03.
For some reason neither labs instance is any longer serving the tiles generated last week. I just discovered this and I'm not sure what's up with it yet. :(
As I mentioned in 1:1 earlier, I'm concerned about the limited memory and storage availability in the Beta Cluster and WMCS generally, but we'll see how it goes.
All that is to say, I think this is basically complete. Maybe we could keep it open while we troubleshoot the mysterious vanishing tiles.
The maps-test cluster in production still needs to be shut down, but that should really be a separate task.
Comment Actions
@Mholloway let's keep it open until we're sure it is stable and not broken. Feel free to move it back to doing when you work on it.
Any idea on how to proceed to diagnose the instances?
Comment Actions
Looking again today, deployment-maps04 has the generated tiles as expected. I am not sure what was going on yesterday; possibly a PEBKAC problem.
However, deployment-maps03 really has no tiles in cassandra:
mholloway-shell@deployment-maps03:/var/log$ nodetool cfstats v3 Keyspace: v3 Read Count: 14653 Read Latency: 0.023984030573943903 ms. Write Count: 0 Write Latency: NaN ms. Pending Flushes: 0 Table: tiles SSTable count: 0 Space used (live): 0 Space used (total): 0 Space used by snapshots (total): 0 Off heap memory used (total): 0 SSTable Compression Ratio: 0.0 Number of keys (estimate): -1 Memtable cell count: 0 Memtable data size: 0 Memtable off heap memory used: 0 Memtable switch count: 0 Local read count: 14653 Local read latency: NaN ms Local write count: 0 Local write latency: NaN ms Pending flushes: 0 Bloom filter false positives: 0 Bloom filter false ratio: 0.00000 Bloom filter space used: 0 Bloom filter off heap memory used: 0 Index summary off heap memory used: 0 Compression metadata off heap memory used: 0 Compacted partition minimum bytes: 0 Compacted partition maximum bytes: 0 Compacted partition mean bytes: 0 Average live cells per slice (last five minutes): NaN Maximum live cells per slice (last five minutes): 0 Average tombstones per slice (last five minutes): NaN Maximum tombstones per slice (last five minutes): 0 ----------------
I was consuming the tiles from the new v3 keyspace on deployment-maps03 on 8/2, so I know they were being generated. I can't find anything interesting in the cassandra logs. I guess I'll try generating some tiles again and keep a closer eye on what happens subsequently.
Comment Actions
Should we connect the test servers to a dashboard like the production one where we could see stats for tile generation rates, etc? (excuse me if it is already somewhere, couldn't find it). Seems like it could be a good idea to check on the servers before rolling to production when we make changes.
Comment Actions
For the record, I just logged back on to deployment-maps03 and attempted to generate tiles again, and ran into our old friend, the tilelive-tmstyle "Cannot read property 'length' of undefined" error:
TypeError: Cannot read property 'length' of undefined
at /srv/deployment/tilerator/deploy-cache/revs/52720d602fc5455423f722baa213affdbc87fe0f/node_modules/tilelive-tmstyle/index.js:180:56
at Array.map (native)
at /srv/deployment/tilerator/deploy-cache/revs/52720d602fc5455423f722baa213affdbc87fe0f/node_modules/tilelive-tmstyle/index.js:179:34
at CassandraStore.handler.getInfo (/srv/deployment/tilerator/deploy-cache/revs/52720d602fc5455423f722baa213affdbc87fe0f/node_modules/@kartotherian/core/lib/sources.js:260:7)
at /srv/deployment/tilerator/deploy-cache/revs/52720d602fc5455423f722baa213affdbc87fe0f/node_modules/tilelive-tmstyle/index.js:118:20
at tryCatcher (/srv/deployment/tilerator/deploy-cache/revs/52720d602fc5455423f722baa213affdbc87fe0f/node_modules/bluebird/js/release/util.js:16:23)
at Promise.successAdapter (/srv/deployment/tilerator/deploy-cache/revs/52720d602fc5455423f722baa213affdbc87fe0f/node_modules/bluebird/js/release/nodeify.js:23:30)
at Promise._settlePromise (/srv/deployment/tilerator/deploy-cache/revs/52720d602fc5455423f722baa213affdbc87fe0f/node_modules/bluebird/js/release/promise.js:566:21)
at Promise._settlePromiseCtx (/srv/deployment/tilerator/deploy-cache/revs/52720d602fc5455423f722baa213affdbc87fe0f/node_modules/bluebird/js/release/promise.js:606:10)
at Async._drainQueue (/srv/deployment/tilerator/deploy-cache/revs/52720d602fc5455423f722baa213affdbc87fe0f/node_modules/bluebird/js/release/async.js:138:12)
at Async._drainQueues (/srv/deployment/tilerator/deploy-cache/revs/52720d602fc5455423f722baa213affdbc87fe0f/node_modules/bluebird/js/release/async.js:143:10)
at Immediate.Async.drainQueues (/srv/deployment/tilerator/deploy-cache/revs/52720d602fc5455423f722baa213affdbc87fe0f/node_modules/bluebird/js/release/async.js:17:14)
at runCallback (timers.js:672:20)
at tryOnImmediate (timers.js:645:5)
at processImmediate [as _immediateCallback] (timers.js:617:5)So I dropped and recreated the v3 keyspace, and reran tileshell, and tiles are once again being generated and served.
For the record, the tileshell command I've been using to get some tiles going, on both deployment-maps03 and -maps04, is:
node /srv/deployment/tilerator/deploy/node_modules/tilerator/scripts/tileshell.js --config /etc/tilerator/config.yaml -j.fromZoom 0 -j.beforeZoom 8 -j.generatorId gen -j.storageId v3 -j.deleteEmpty -j.saveSolid -j.zoom=0
That seems like a good idea. To be honest, I have no idea how to go about creating a grafana dashboard :)
Comment Actions


There is some info here, not very friendly tho: https://wikitech.wikimedia.org/wiki/Grafana.wikimedia.org
If you go to https://grafana.wikimedia.org/ and you log in (click wikimedia logo top left, and login with ldap credentials):
Once logged in click on the Home button top left:

You will see a "New dashboard" button:
There you get a GUI where you can add panels with different types of graphs and new rows to the dashboard. Whenever I've looked into it I've explored more than followed any tutorial.
Once done, remember to save your dashboard:
For the name prefix it with "Maps" so that it shows grouped with the other ones in the big list.
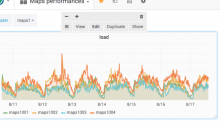
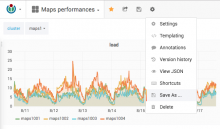
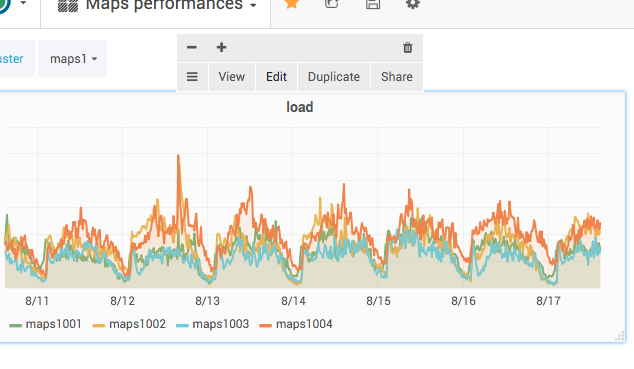
One thing I've done too before is look at how an existing dashboard is made. For example if you go to the Maps performance one, you can poke the panels and edit them to see how they are configured. For that click on the title of the pane and a submenu appears, then you can click "Edit"
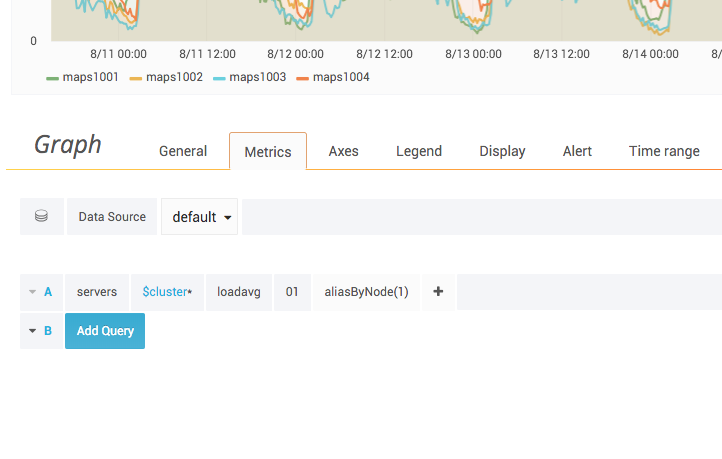
Then you will see the graph fullscreen and the configuration with the queries at the bottom. Feel free to poke around and change things, there is autocomplete and it is quite approachable:
NOTE: Don't save your changes if you are just poking around!
Another option is to clone a dashboard, which could be useful for what we are doing which is mirror the dashboard but with the test environment. For that click on the settings icon and then "Save as":
Then you can make the appropriate changes after cloning it.
Regarding the data sources, we'll need to check that the deployment is configured to log to the appropriate statsd/graphite (more general info here, there seems to be a beta cluster graphite instance so maybe we should use that). I'm not sure exactly how we proceed here, depends on how things are logged and configured.
cc/ @Gehel for feedback about how we go on about doing this appropriately
Comment Actions
FYI, the issue with deployment-maps03 dropping tiles has not recurred since I fixed it by dropping and regenerating the keyspace as described in T172090#4502941. It's been serving tiles as expected since then. I think we can consider the issue resolved.