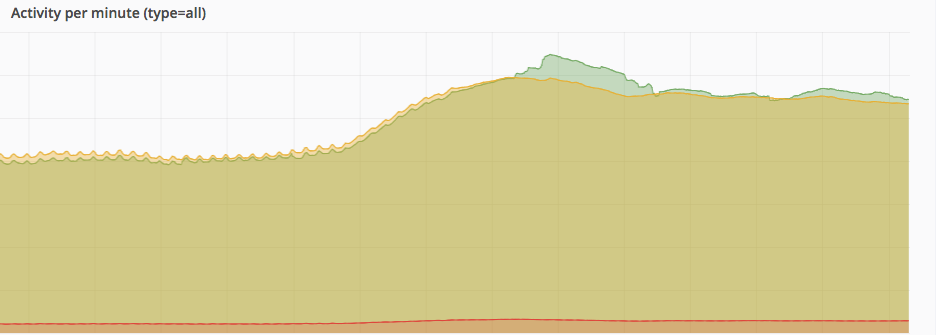
This doesn't sound good:
| August 21 |
|---|
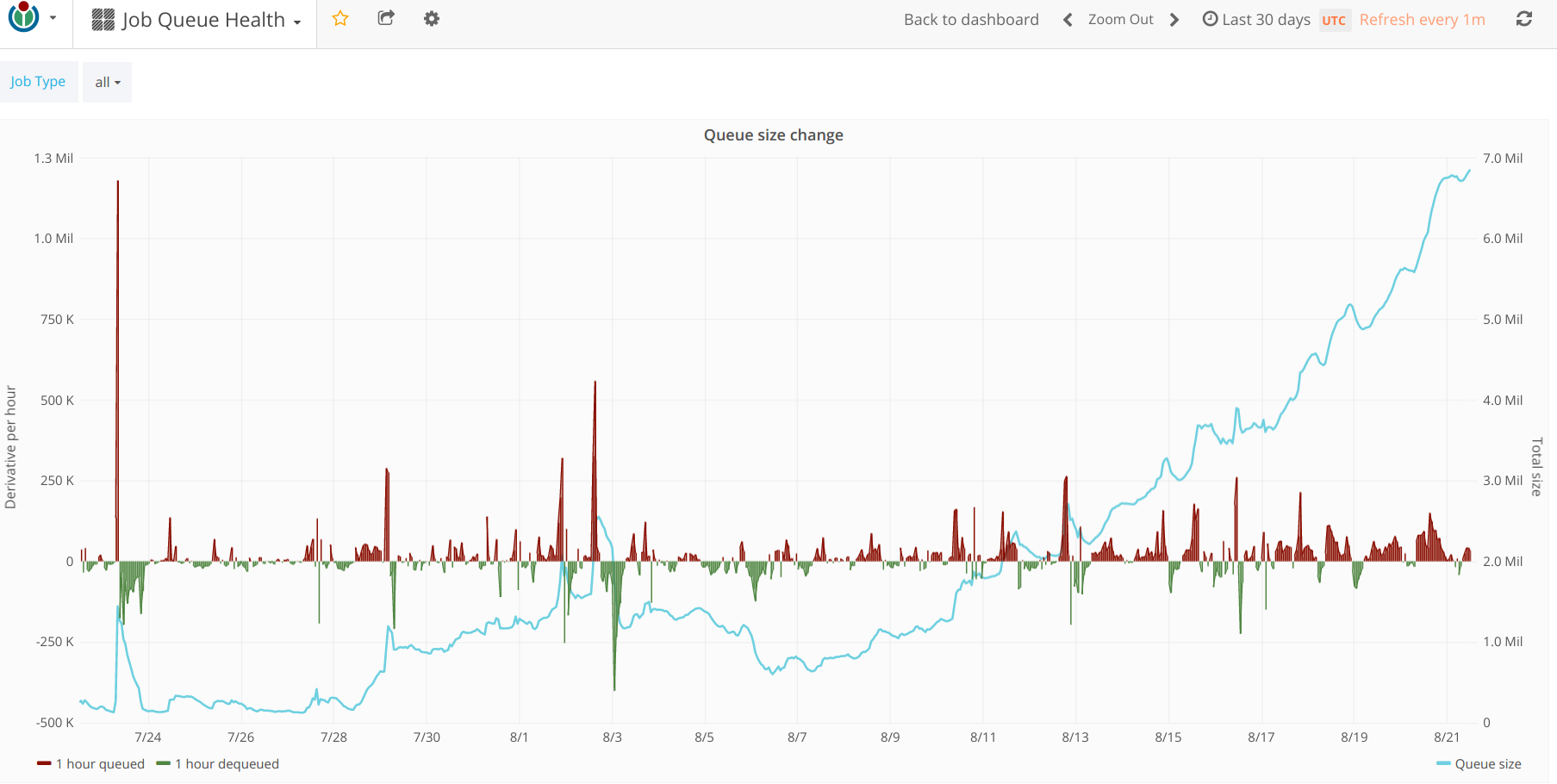 |
Current: https://grafana.wikimedia.org/dashboard/db/job-queue-health?refresh=1m&orgId=1
Mitigation
- 6898d06f8f Disable rebound CDN purges for backlinks in HTMLCacheUpdateJob. @aaron, https://gerrit.wikimedia.org/r/373705
In MediaWiki 1.27 (2015) we introduced $wgCdnReboundPurgeDelay (more information at https://www.mediawiki.org/wiki/Manual:$wgCdnReboundPurgeDelay). This means that effectively every purge is actually two purges, spaced out by a few seconds, to account for race conditions between database replication and cache population. However, the common case of recursive updates (e.g. from templates) is already delayed through the JobQueue, so we can omit the rebound purge in that case.
→ Fixing this improved job execution throughput, and decreased job queue growth.
- 70d1bc0091 Make workItemCount() smarter for htmlCacheUpdate/refreshLinks. @aaron, https://gerrit.wikimedia.org/r/373325
To avoid pressure on CDN and database, job execution can be throttled via https://www.mediawiki.org/wiki/Manual:$wgJobBackoffThrottling. The placeholder jobs for recursive updates (e.g. for templates) were being counted as 1, which needlessly subjected them to throttling.
→ Fixing this improved job execution throughput.
- 56ed177f1 Reduce batch size in WikiPageUpdater. @Ladsgroup, https://gerrit.wikimedia.org/r/#/c/373551/
→ Fixing this improved job execution throughput.
- cb7c910ba Fix old regression in HTMLCacheUpdate de-duplication. @aaron, https://gerrit.wikimedia.org/r/373979
Following a refactor in mid-2016, the duplication logic for recursive updates started to be miscalculated (based on current time, instead of time from the initial placeholder/root job).
→ Fixing this significantly decreased job queue growth.
| Dashboard: Job Queue Helath |
|---|
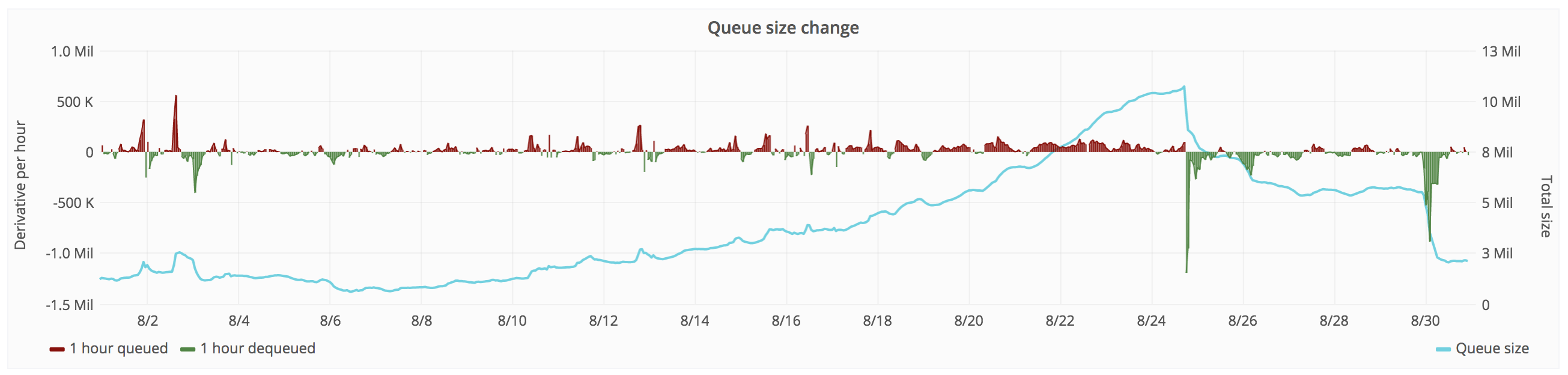 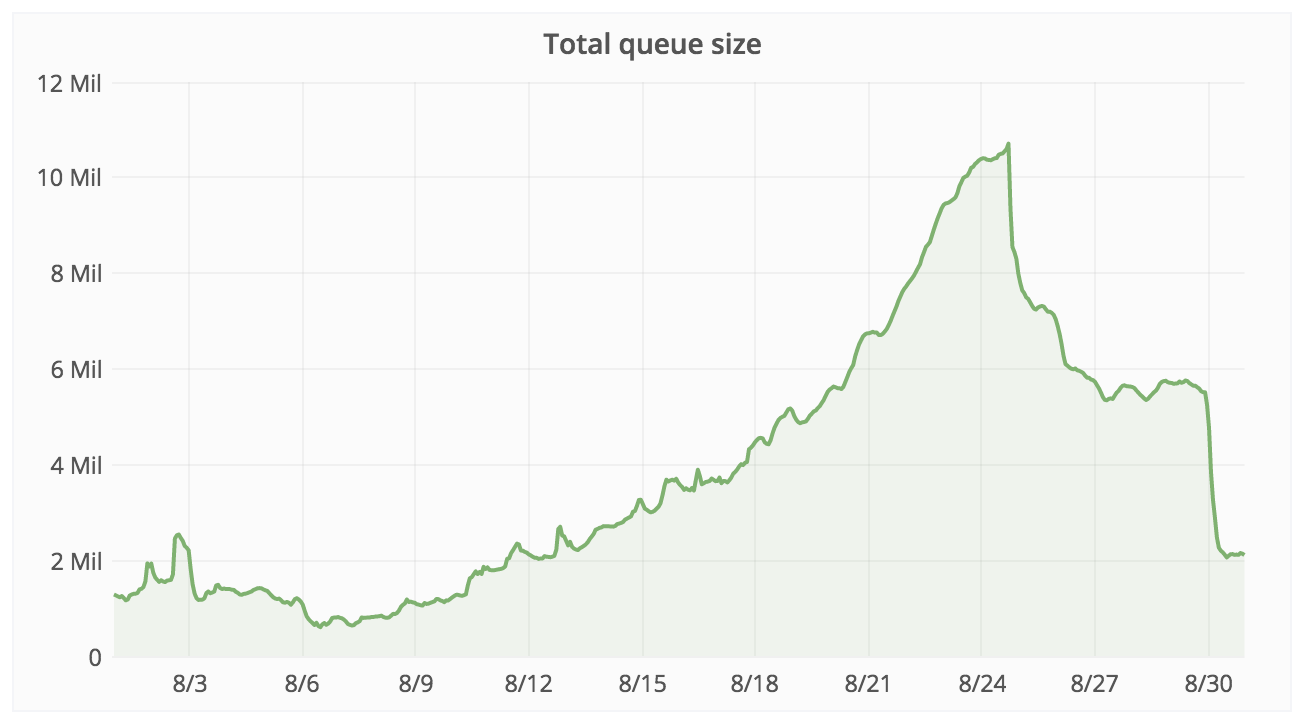 |
| Job queue size down from 10M to a steady ~2M. Before the regression it was a steady between 100K -1M. |
| Dashboard: Varnish stats |
|---|
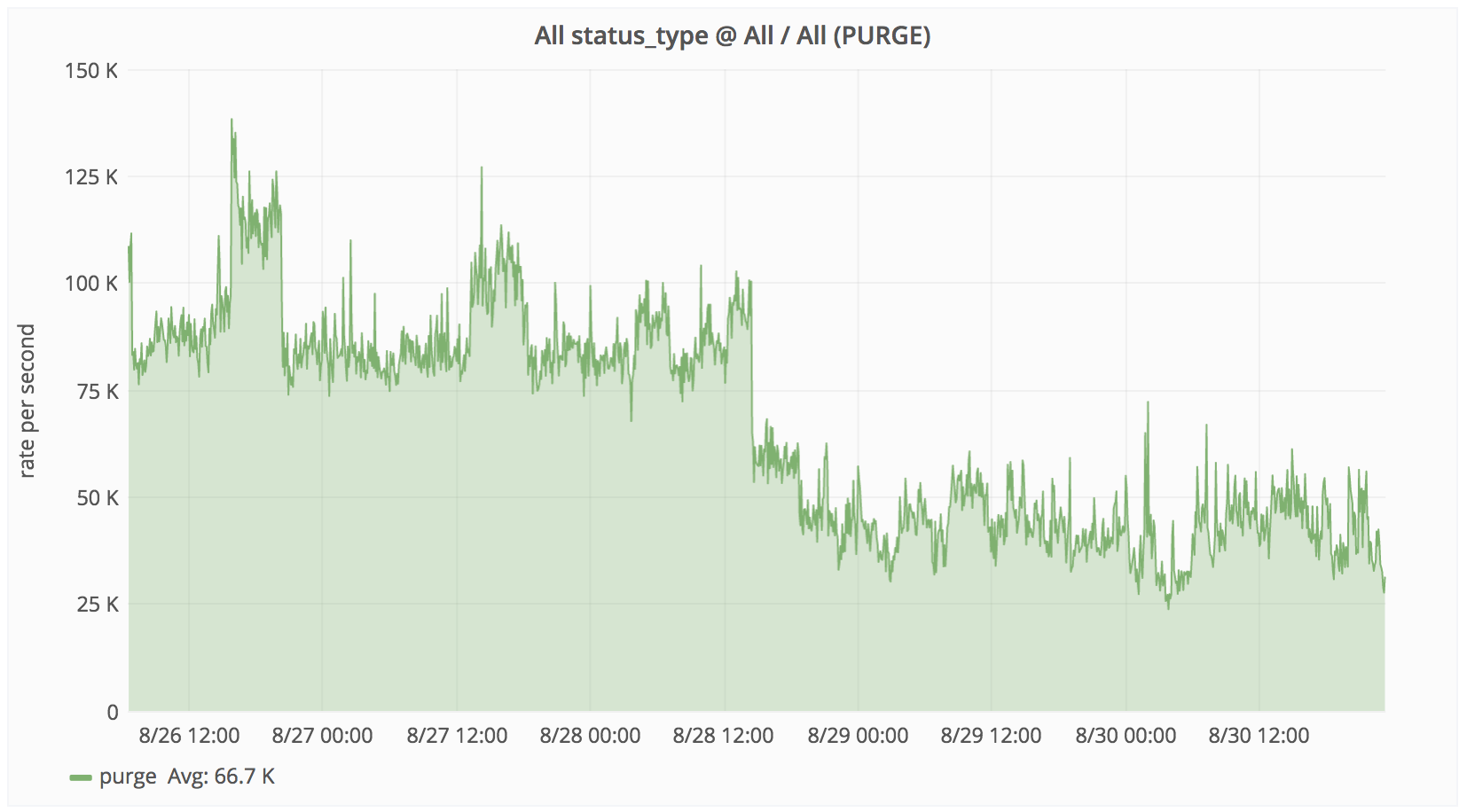 |
| Purge rate from production Varnish servers reduced by 2-3X, from 75-100K/s to ~30K/s. |
| Dashboard: Job Queue Rate for htmlCacheUpdate |
|---|
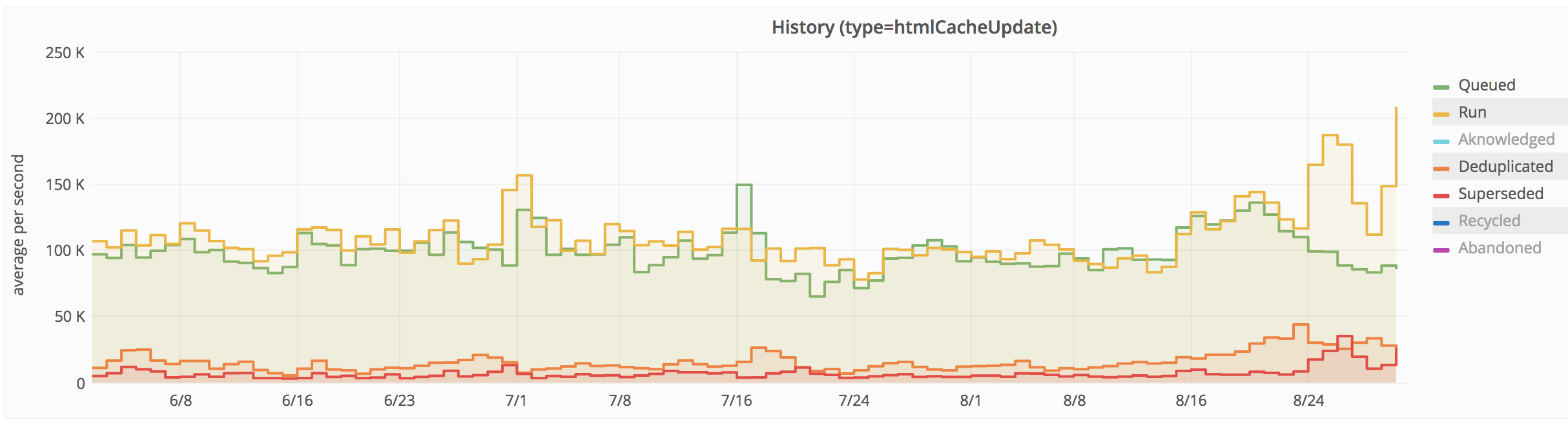 |
| Queue rate of htmlCacheUpdate back to normal. Deduplication/Superseding optimisation is now working. Execution speed has increased. |
- https://gerrit.wikimedia.org/r/295027
- https://gerrit.wikimedia.org/r/373325
- https://gerrit.wikimedia.org/r/373390
- https://gerrit.wikimedia.org/r/373521
- https://gerrit.wikimedia.org/r/373539
- https://gerrit.wikimedia.org/r/373547
- https://gerrit.wikimedia.org/r/373548
- https://gerrit.wikimedia.org/r/373551
- https://gerrit.wikimedia.org/r/373705
- https://gerrit.wikimedia.org/r/373979
- https://gerrit.wikimedia.org/r/373984
- https://gerrit.wikimedia.org/r/375819
- https://gerrit.wikimedia.org/r/376562
- https://gerrit.wikimedia.org/r/377046
- https://gerrit.wikimedia.org/r/377458
- https://gerrit.wikimedia.org/r/377811
- https://gerrit.wikimedia.org/r/378719
- https://gerrit.wikimedia.org/r/386636
See also: