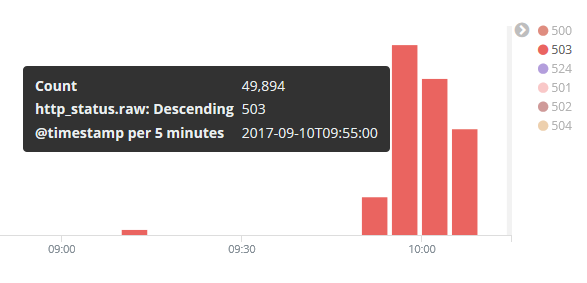
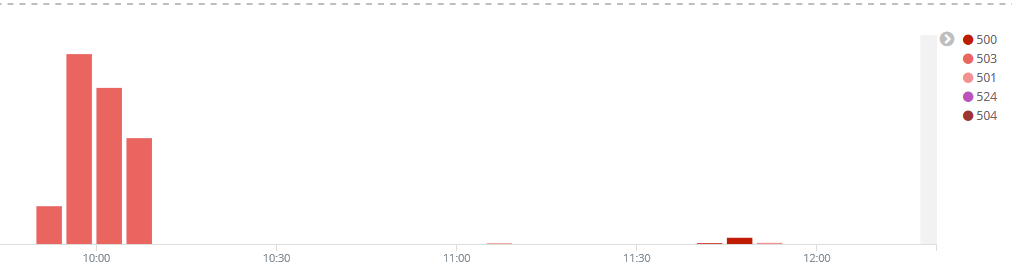
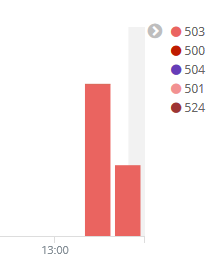
Currently a high number of 503 Erros's, see the attached log from wmops irc channel.
11:58:28 <icinga-wm> PROBLEM - Text HTTP 5xx reqs/min on graphite1001 is CRITICAL: CRITICAL: 11.11% of data above the critical threshold [1000.0] 11:58:48 <icinga-wm> PROBLEM - Esams HTTP 5xx reqs/min on graphite1001 is CRITICAL: CRITICAL: 50.00% of data above the critical threshold [1000.0] 11:59:48 <icinga-wm> PROBLEM - Eqiad HTTP 5xx reqs/min on graphite1001 is CRITICAL: CRITICAL: 44.44% of data above the critical threshold [1000.0] 12:00:38 <icinga-wm> PROBLEM - Ulsfo HTTP 5xx reqs/min on graphite1001 is CRITICAL: CRITICAL: 44.44% of data above the critical threshold [1000.0] 12:01:14 → ShakespeareFan00 joined (~chatzilla@gfarlie-adsl.demon.co.uk) 12:01:47 <ShakespeareFan00> Getting a lot of errors of the "Request from <redacted> via cp1053 cp1053, Varnish XID 883949803 12:01:49 <ShakespeareFan00> Error: 503, Backend fetch failed at Sun, 10 Sep 2017 10:00:53 GMT" kind 12:01:54 <ShakespeareFan00> Replication running? 12:02:03 <ShakespeareFan00> or was there planned mantainence? 12:02:58 <tiddlywink> Wikidata has just died (normally I'd be grateful, but as I'm trying to sort out stuff there, it's a nuisance right now) 12:04:25 <tiddlywink> same error, cp1053, hitting refresh fixes it 12:04:38 <Vito> same here 12:04:43 <Vito> cp1053 12:04:54 <Vito> and no css 12:05:01 <Vito> (from esams) 12:05:57 <rxy> me too. x-cache:cp1053 int, cp2004 miss, cp4028 pass, cp4027 miss 12:06:36 <ShakespeareFan00> I'd recentlly updated a template at Commons? 12:06:44 <TheresNoTime> cp1053 looks OK in icinga, loads of 503s from 09:50 UTC onwards 12:06:46 <ShakespeareFan00> Would that cause meltdown? I hope not 12:07:57 <ShakespeareFan00> Also https://ganglia.wikimedia.org/latest seems to giving 403's 12:08:18 <ShakespeareFan00> Presumably it's intended only approrpiate staff can access it 12:08:28 <ShakespeareFan00> 401's sorru 12:08:54 <Steinsplitter> getting tons of such errors: Caused by: java.io.IOException: Server returned HTTP response code: 503 for URL: https://commons.wikimedia.org/w/api.php?format=xml&rawcontinue=1&maxlag=6&action=query&prop=categories&cllimit=max&titles=File%3A%C3%89glise+St+%C3%89tienne+Montcet+6.jpg 12:09:47 <Steinsplitter> * Ops Clinic Duty: ema 12:09:59 <TheresNoTime> Welp, cp1053 does have a critical (Varnish HTTP text-backend - port 3128) 12:10:18 <icinga-wm> PROBLEM - MediaWiki exceptions and fatals per minute on graphite1001 is CRITICAL: CRITICAL: 70.00% of data above the critical threshold [50.0]