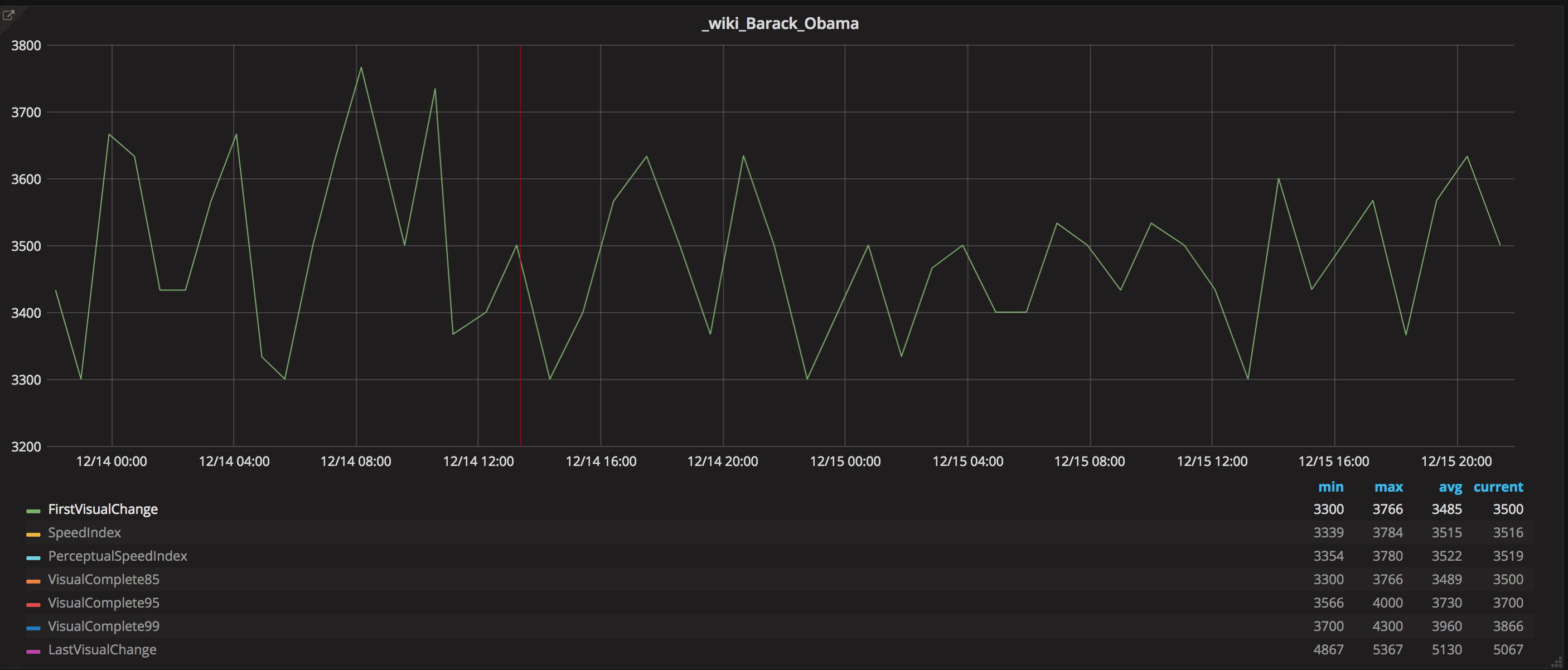
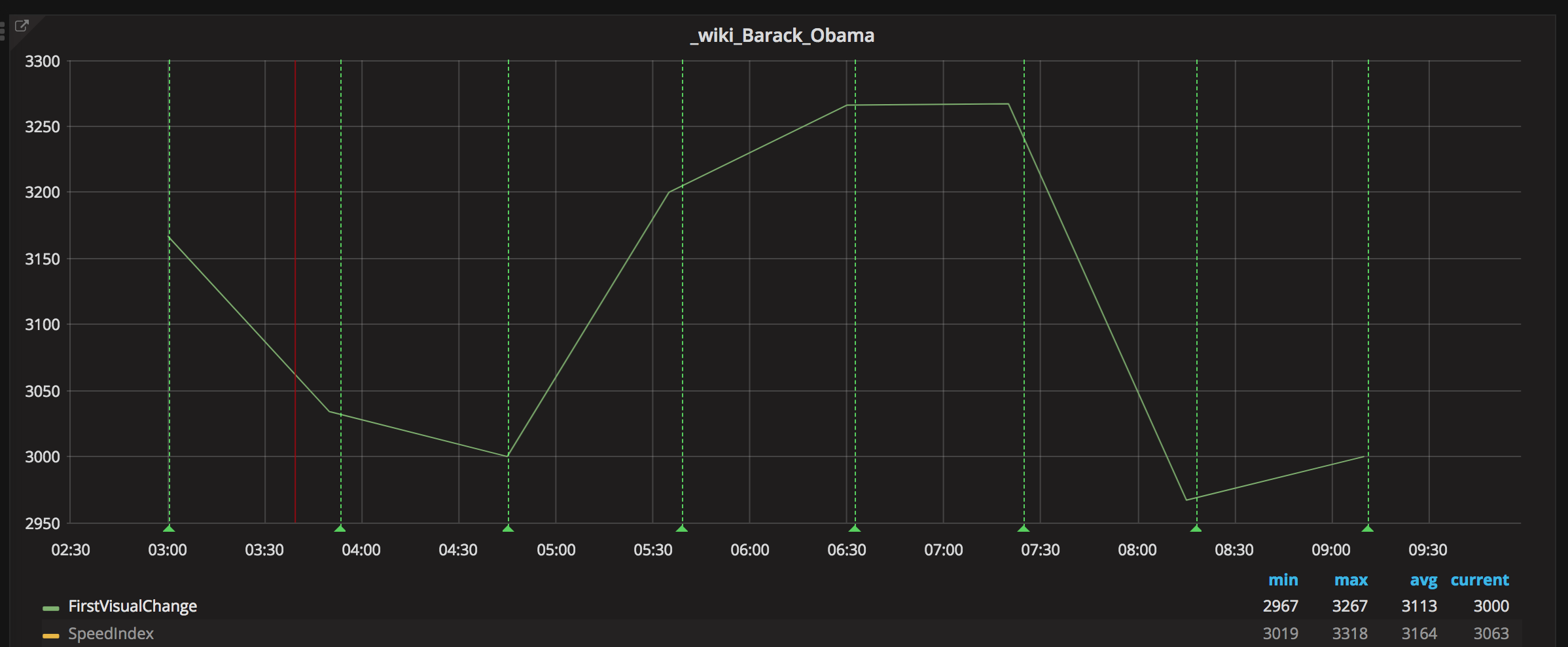
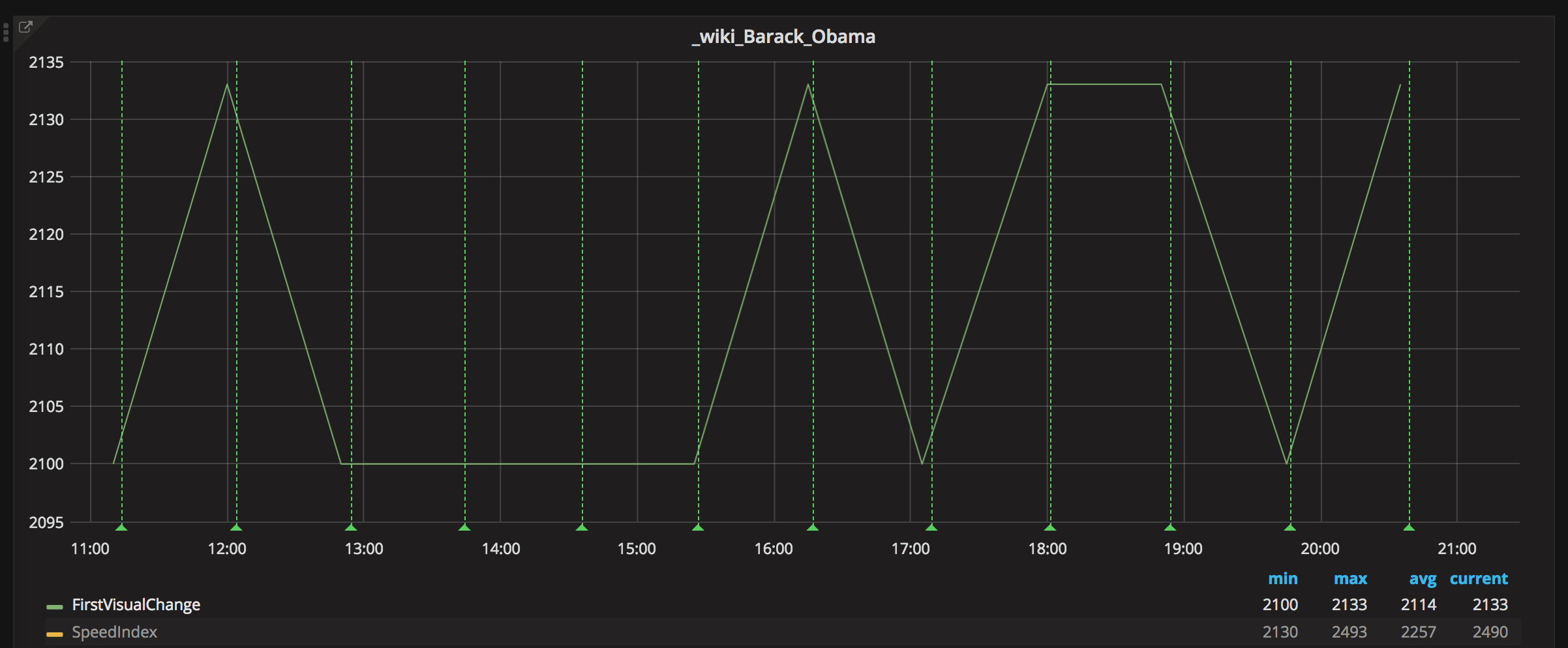
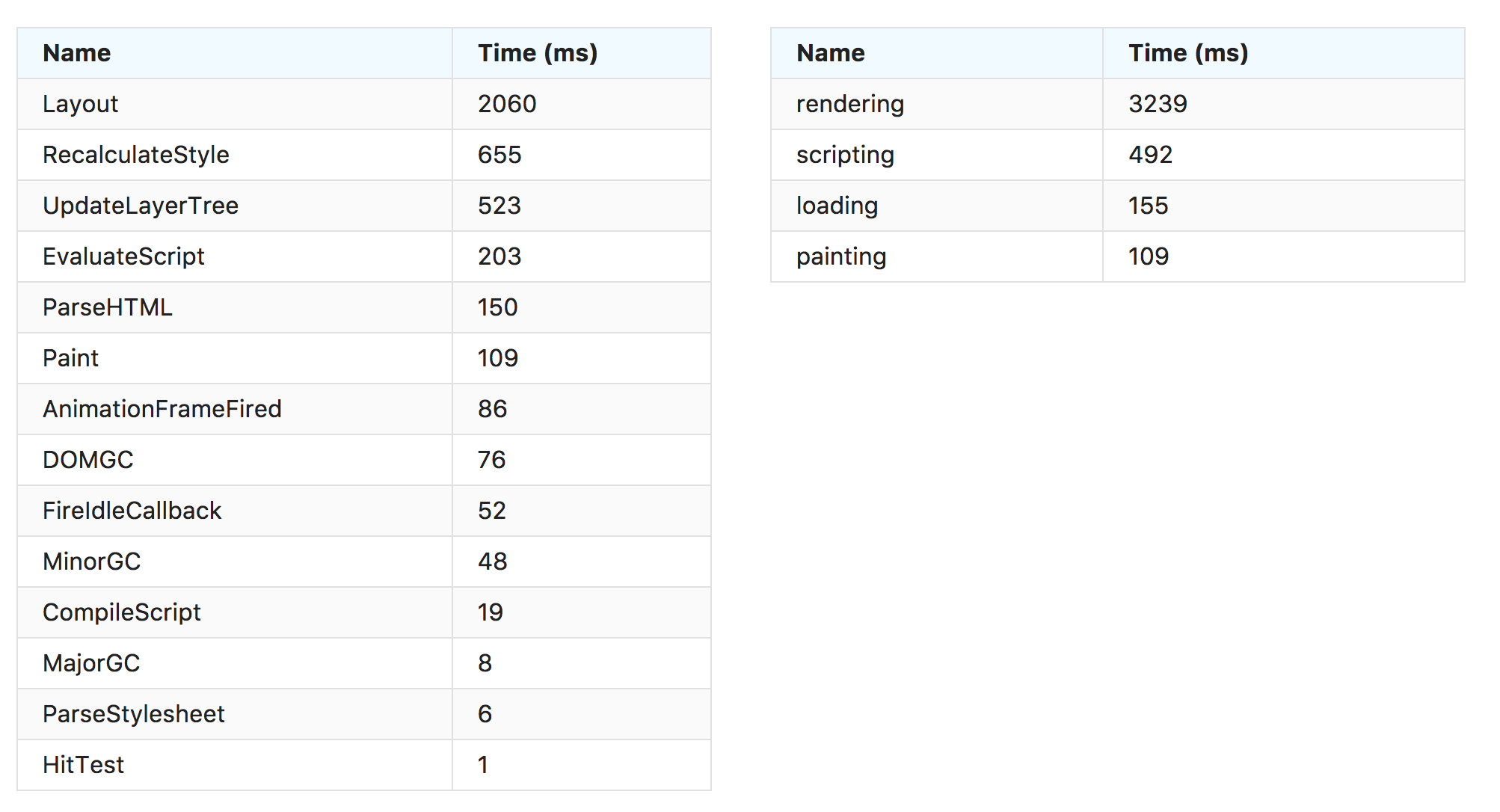
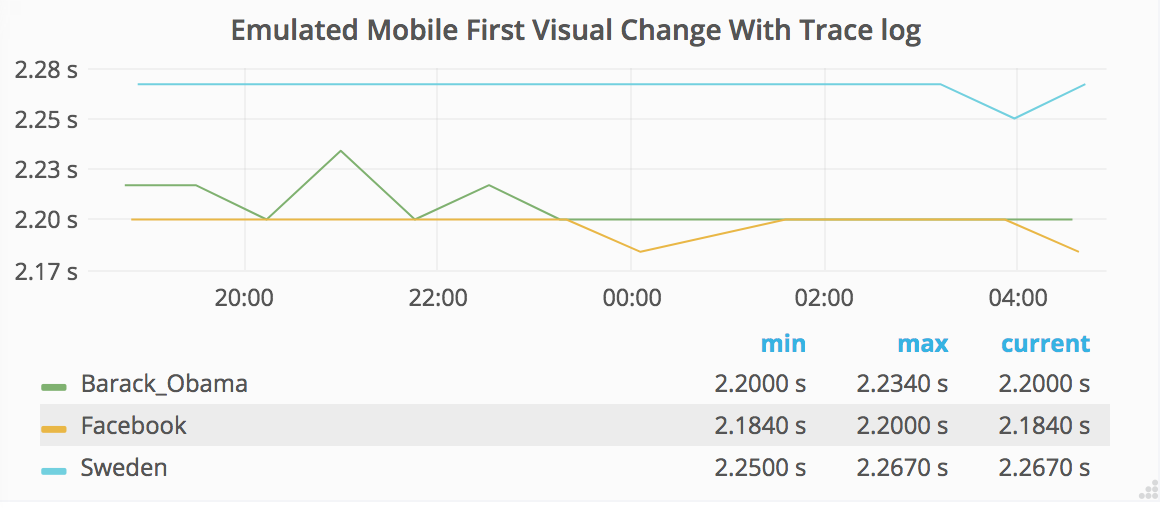
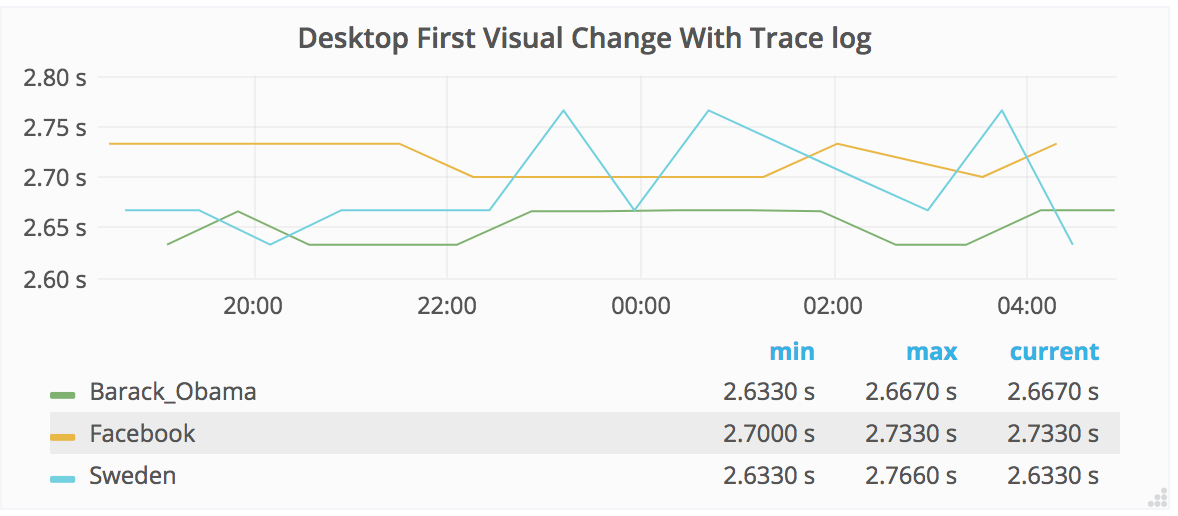
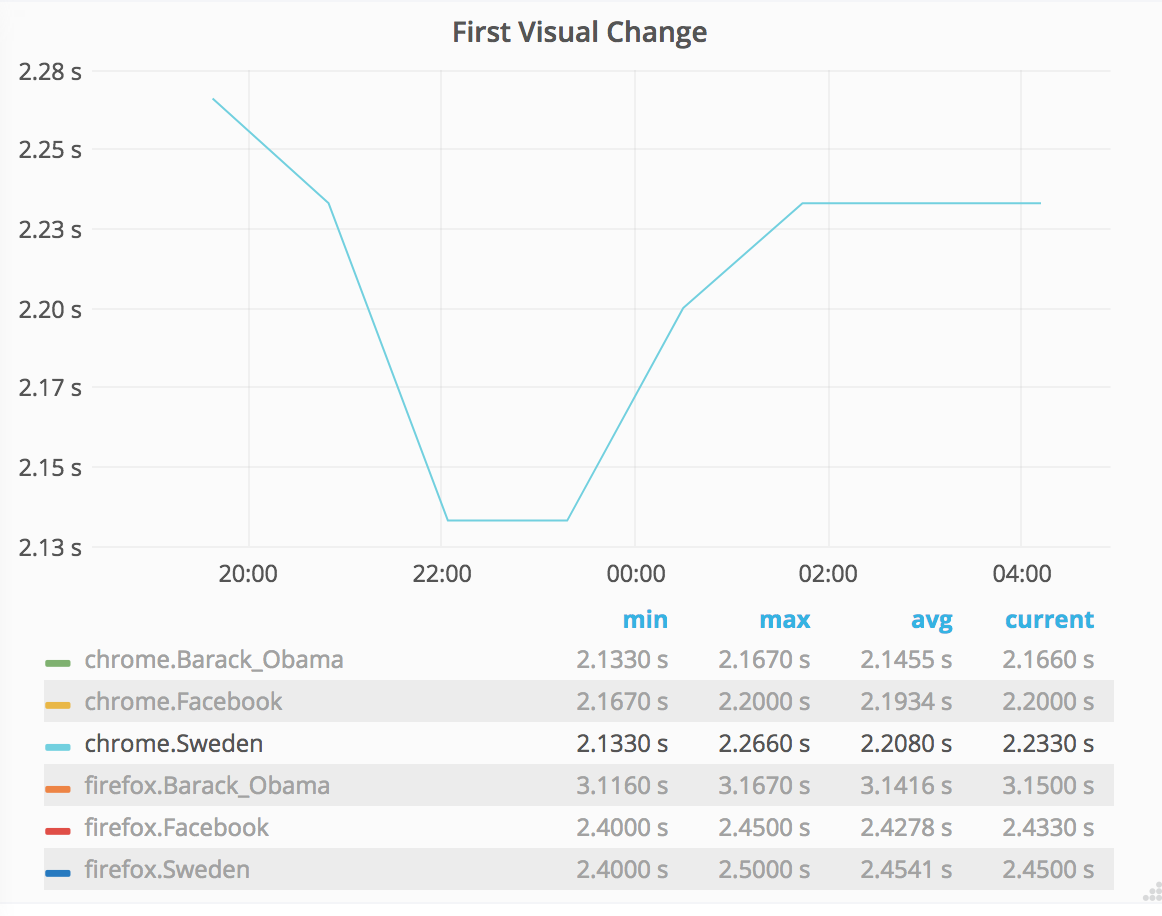
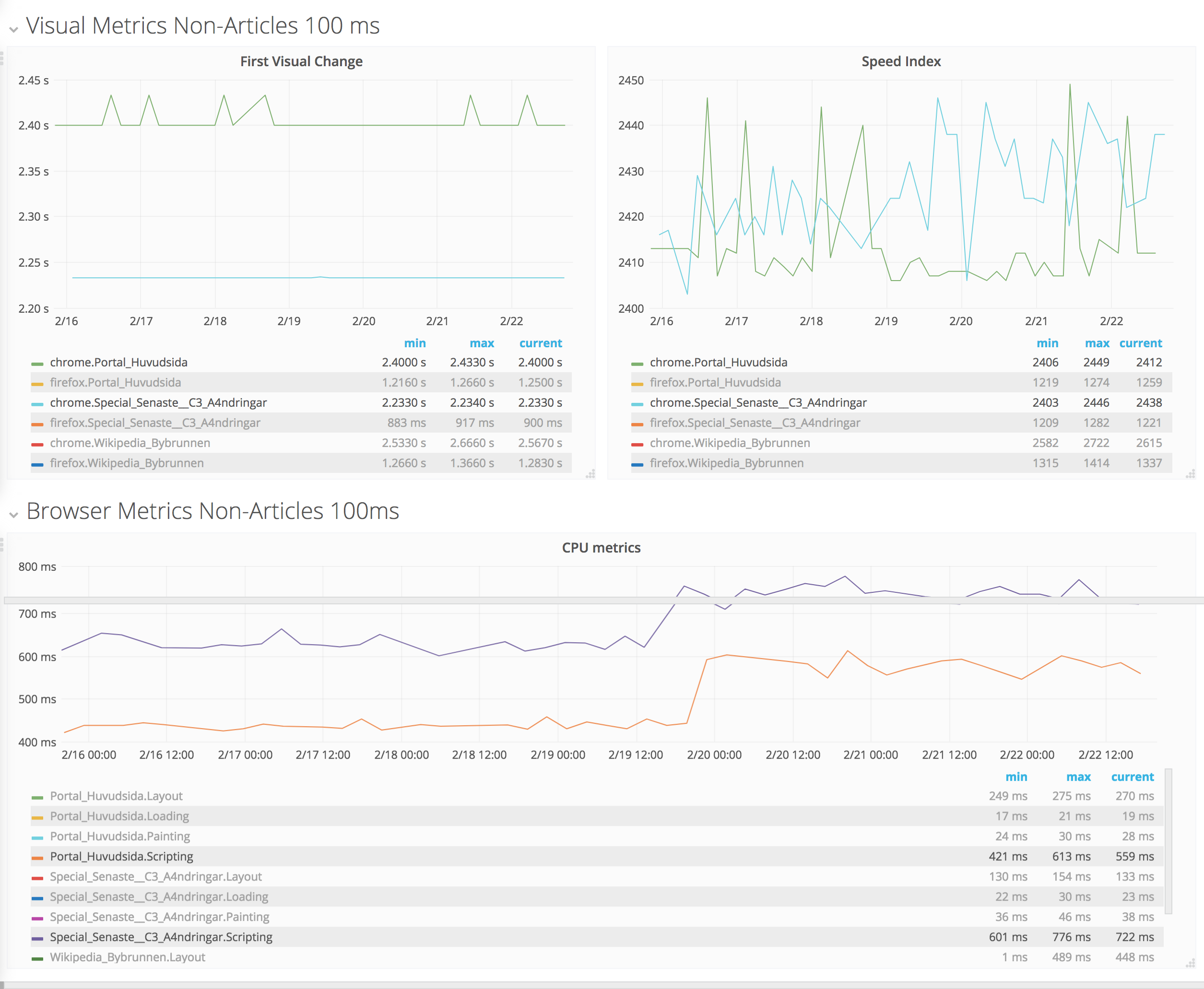
The new measurements for using WebPageReplay gives us stable first render and speed index. The next step is to use the Chrome trace log together with the devtools-timeline-model to get more insights of where the time is spent rendering the page.
This should be pretty straight forward: Enable chrome trace log in Browsertime and then parse it and send the important metrics to statsv. We can do it by doing a standalone cli built upon the devtools-timeline-model.