Apps must provide a timestamp for GET /changes/since/{timestamp} so that changes starting from that time are shown. This is currently problematic for multiple reasons:
- if the app wants to continue from the time it last did a similar request, it must rely on its own clock which might be out of sync with the server
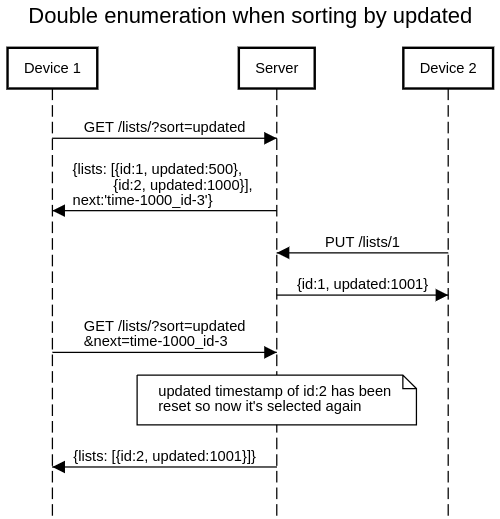
- if the app wants to use the last timestamp returned in the previous request, it cannot do that sanely because the request returns list and list entry changes in a separate queue, so it must take the older of the two timestamps, which could potentially mean resending many changes in the other queue.
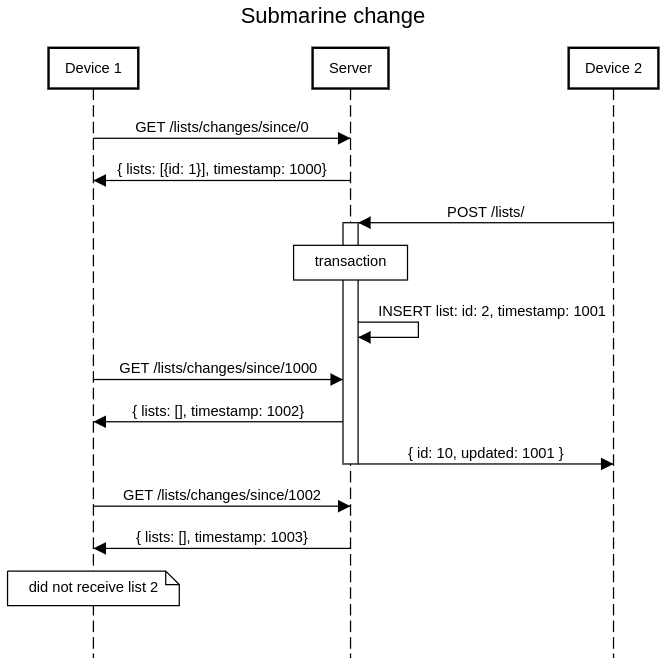
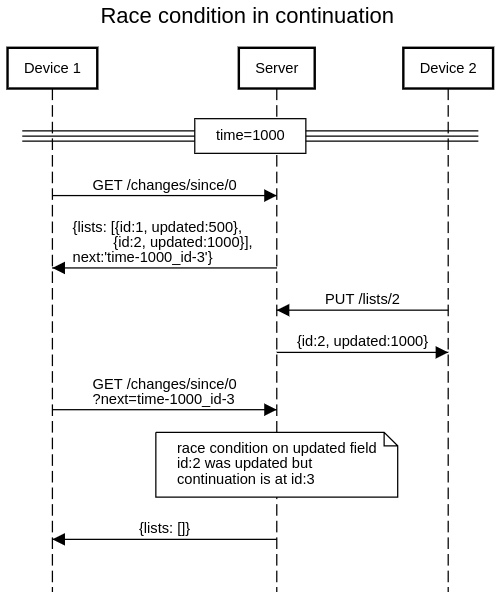
- either way, the app can miss changes which were inserted in the DB but not committed at the time the app made the previous request.
(See T182706#3933410 for more detail.)
Suggested solution:
- Add a continue-from timestamp field to every GET /changes/since/{timestamp} and GET /lists/ response, telling the last timestamp it is safe to request a sync from. This will be the time the server has received the request, minus some margin for race conditions / transactions (probably also slave lag?).
- On continuation, don't return such a timestamp (have the client retain the timestamp they got in the first step). In the future this could be improved but probably not worth it (would have to remember during the sequence of request what was the point when the timestamp in the continuation parameter was close enough to real time that there was a possibility of skipping an event; or would have to apply the same backdating logic to the timestamp inside the continuation parameter).
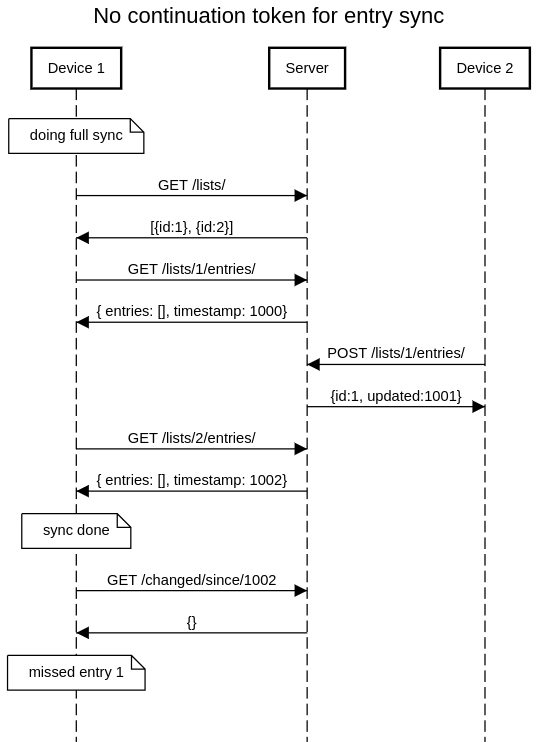
- When apps do a full sync (a GET /lists/ request followed by a GET /lists/{id}/entries/ for every list received), they should treat the timestamp returned by GET /lists/ as the last time they have synced the DB. When not receiving any timestamp (on continuation), they should preserve the previous timestamp.
- Document that clients need to be able to deal with duplicate events when syncing.
- (optional) Have sync queries use LOCK IN SHARE MODE to make sure there cannot be "submarine transactions" where a change is inserted in the database with a certain timestamp but not visible due to being in an uncommitted transaction, so both the initial request and the followup miss it. This allows reducing the amount of timestamp backdating to 1s (just needs to avoid continuation race conditions). - T187133: Prevent "submarine transactions" in ReadingLists sync