See T178942#3867158.
This caused a high spike in Logstash for type:mediawiki channel:error (and presumably in type:hhvm as well) on every MediaWiki index.php request.
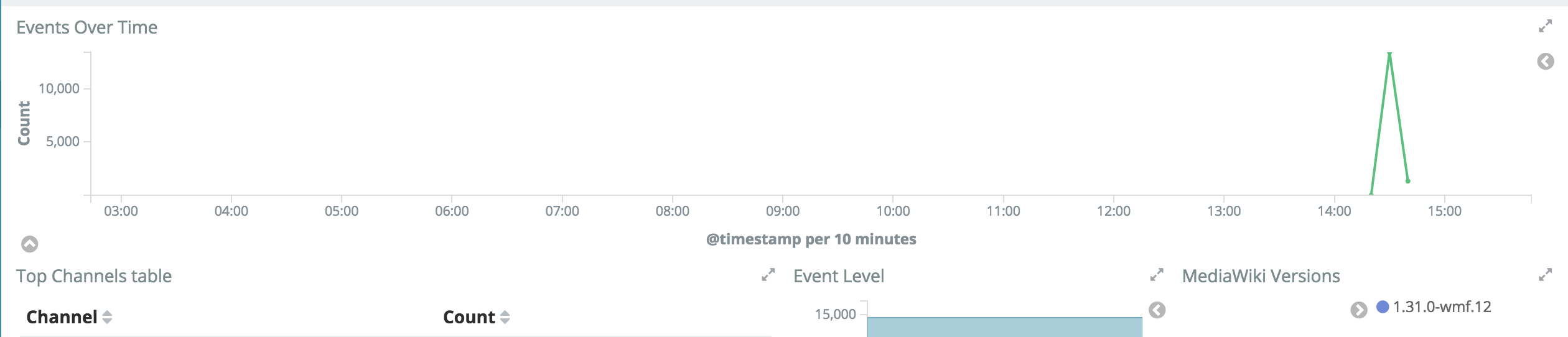 |  |
| Krinkle | |
| Jan 2 2018, 6:48 PM |
| F12210688: Screen Shot 2018-01-02 at 18.48.57.png | |
| Jan 2 2018, 6:49 PM |
| F12210690: Screen Shot 2018-01-02 at 18.49.11.png | |
| Jan 2 2018, 6:49 PM |
See T178942#3867158.
This caused a high spike in Logstash for type:mediawiki channel:error (and presumably in type:hhvm as well) on every MediaWiki index.php request.
| |
Logstash graph based on the query looks like it should have caught it: https://logstash.wikimedia.org/goto/800d886d5e05b8e1f9d11454717cf183
Couple of options:
Well.
Scap does seem to have failed along with that error spike: http://tools.wmflabs.org/sal/log/AWC3SqMzwg13V6286YVJ
scap failed: average error rate on 6/11 canaries increased by 10x (rerun with --force to override this check, see https://logstash.wikimedia.org/goto/2cc7028226a539553178454fc2f14459 for details)
I filed T183999: Scap canary has a shifting baseline to address the main problem I see here, which is that a deployment that spikes the error rate and that's canary check fails but is subsequently redeployed results in the canary check running with a new baseline.
Scap did fail during deployment. Since the commit that caused the failure was already merged, I had to revert it and deploy the revert. Is there something else I should have done?
Nope, as I'm looking at it, it looks like you did the right thing and that this deploy didn't make it any further than the canary servers: all the effected servers are in: /etc/dsh/group/mediawiki-ap{i,pserver}-canaries.
Dug a little deeper on this today and realized that this didn't actually make it out to production afaict (thanks to @zeljkofilipin), although the error rate on the canaries was high enough to climb to spike the overall error rate. The task I filed a few comments back is still a thing we need to do. I'm going to call this investigation complete though.