(High here means we-should-investigate-high, not things-are-critically-broken-high)
s2 is showing high error rate on prometheus:
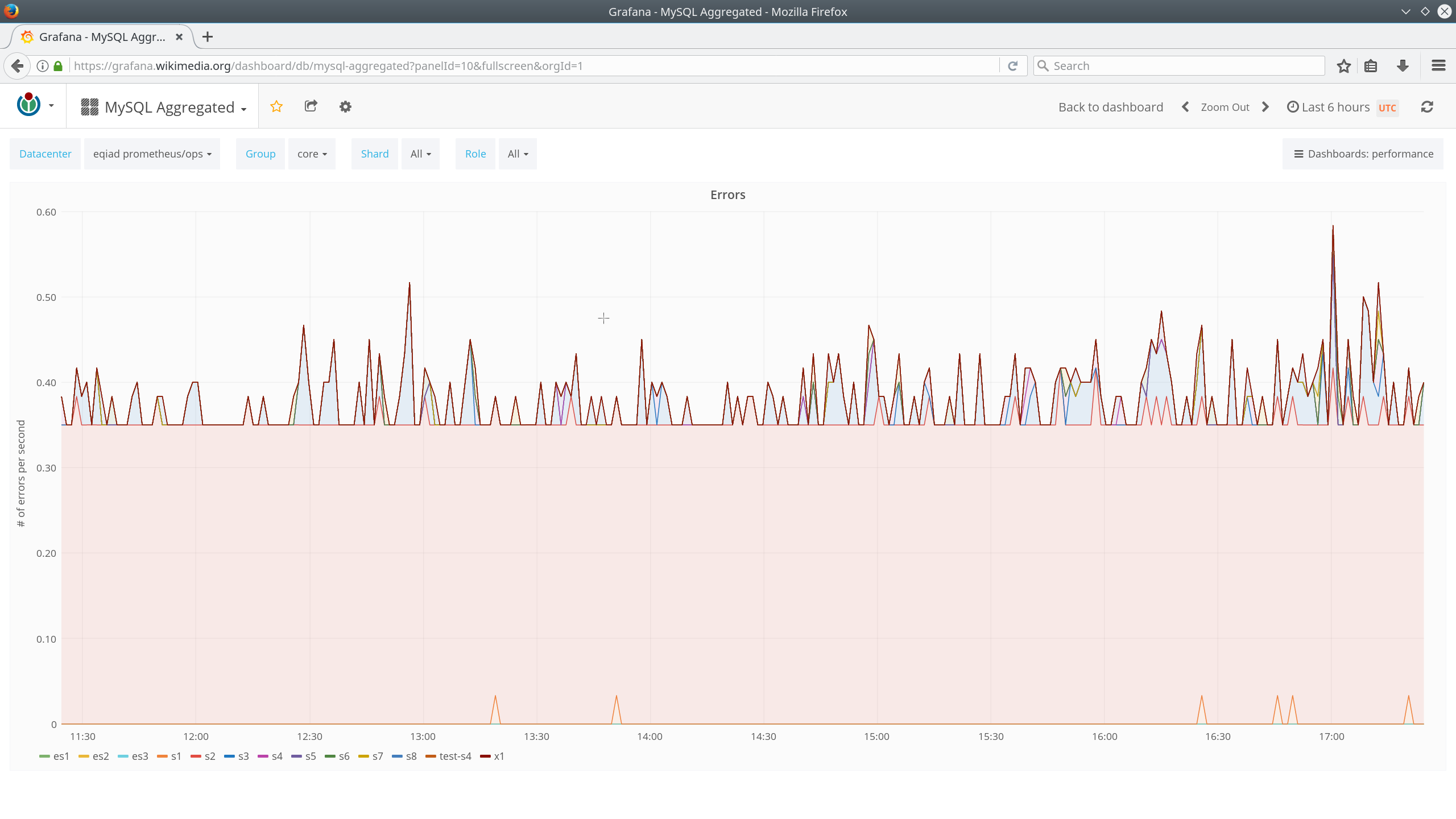
s3 is showing high error connection rate (on db1077, but specially db1078) coming mostly from the job queue:
https://logstash.wikimedia.org/goto/59e95d9d4db3bdd222658e2f08306efd
The real issue, if any, is not yet clear for both cases. It could be some bad permissions, it could be low connection time at PHP side (in which case it should probably be mitigated, and not get its timeout increased); it could be connection overload; it could be some other kind of error).