The RESTBase storage strategy has been extensively redesigned, and is now running in production on Cassandra 3.11.0. Production experience with both this new strategy, and Cassandra 3.11 are limited, and expectations are uninformed. In general, the performance of queries that are end-user facing seem quite good, and the distribution of latencies has narrowed immensely.
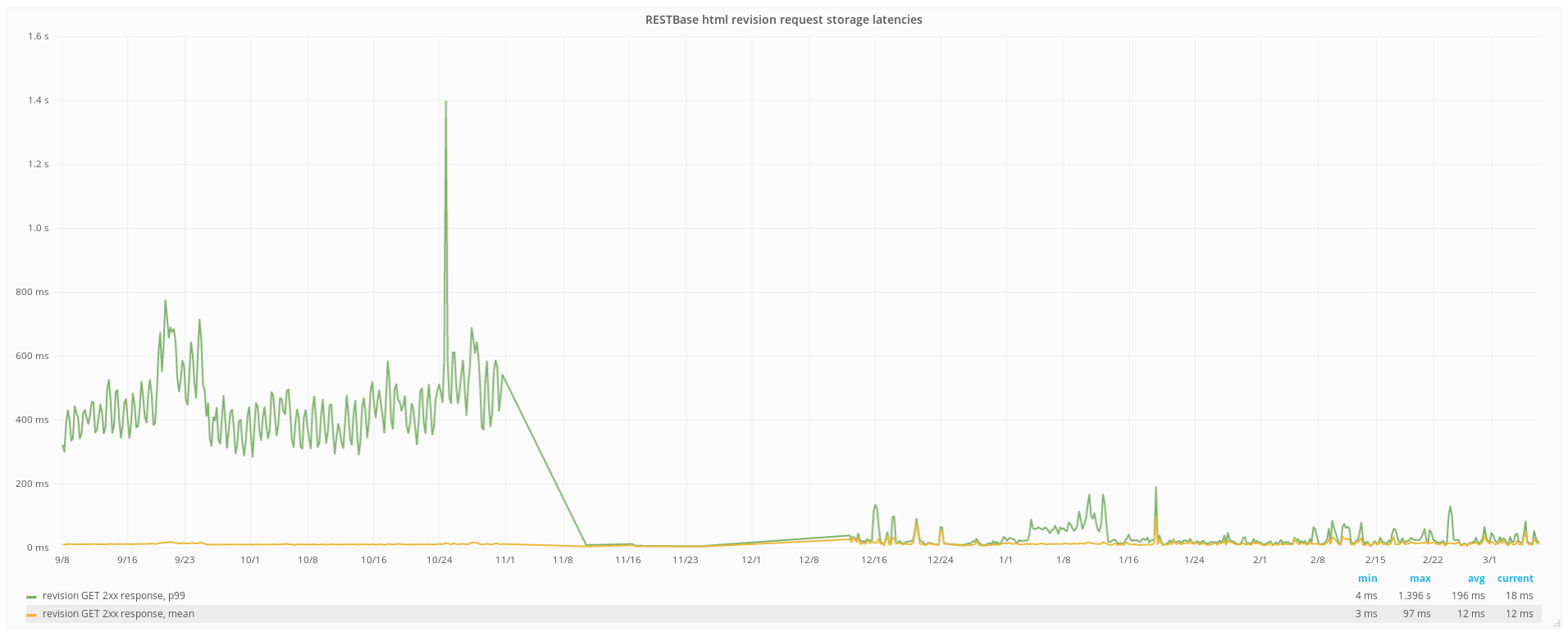
But 99p Cassandra-local latencies can be apparently quite high and erratic.
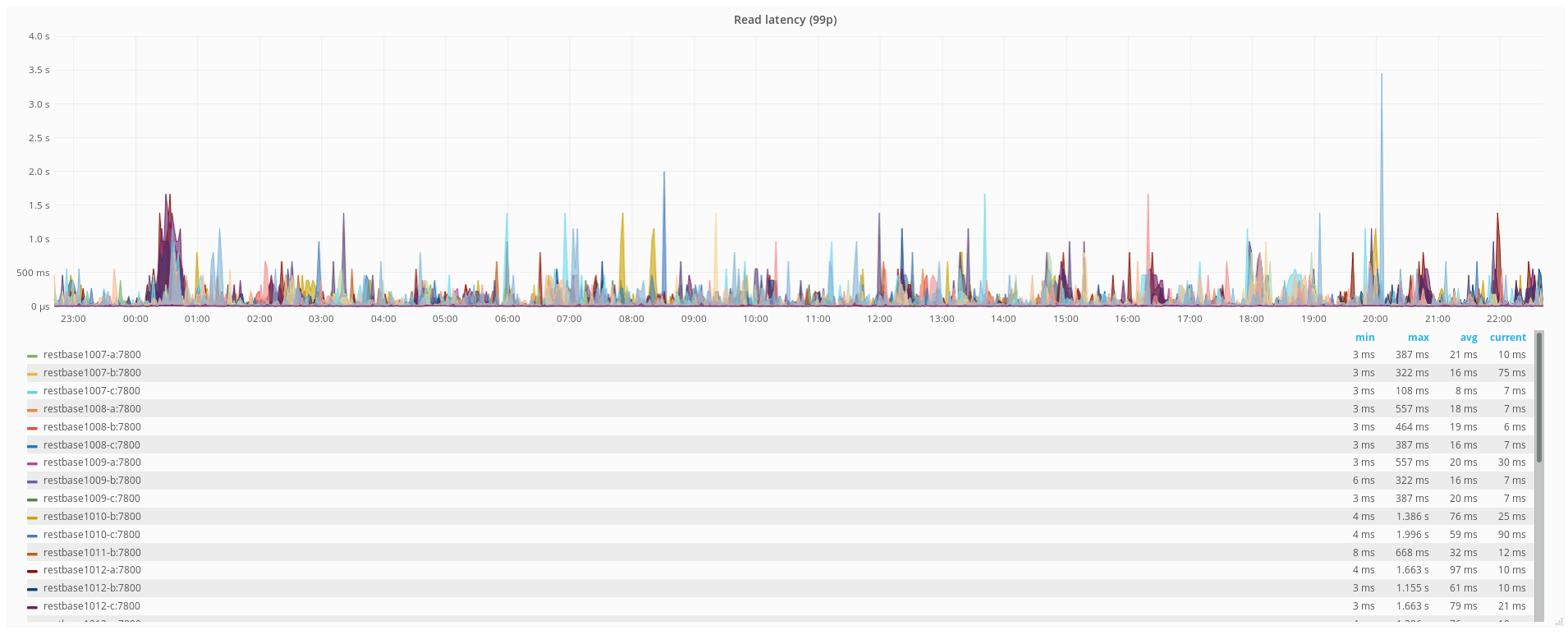
Obviously, the important metrics, the ones we're ultimately judged by, are the ones users are exposed to, but it would benefit us to understand this better, and if possible, identify optimizations to improve latency and overall capacity.
This ticket will track efforts to understand the current performance of the system, and identify and implement improvements.
Some Recommendations
- T186562: Reimage JBO-RAID0 configured RESTBase HP machines
- Consider disabling read_repair_chance
- Considering tuning (or disabling) speculative retry
- Consider decreasing compression chunk lengths
Re-visiting Hardware
As part of the work done in T178177: Investigate aberrant Cassandra columnfamily read latency of restbase101{0,2,4}, we discovered that HP machines configured as a JBOD of single-disk RAID-0s performed worse than if configured as regular HBA attached disks. There may however be more to it.
To summarize, we currently have examples of:
- Dells w/ Samsung SSD 850 devices
- Dells w/ Intel SSDSC2BX01 devices
- HPs w/ Samsung SSD 850 devices configured as single-disk RAID-0s
- HPs w/ Samsung SSD 850 devices (directly attached disks)
- Exactly 1 HP with 4 direct attached HP LK1600GEYMV devices
To complicate comparisons, the cluster is composed of two data-centers, each of which has a distinctly different workload, and not every combination listed above exists in both data-centers. However, see the following graphs:
eqiad
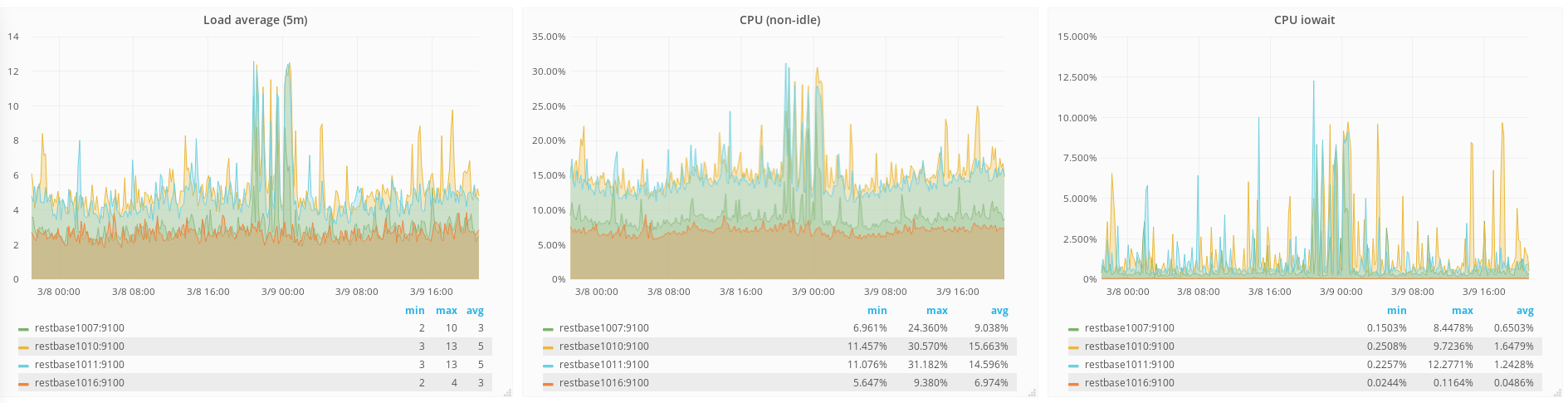
The above graph is of 1007, 1010, 1011, 1016 which represents configurations #1, 3, 4, and 2 respectively. Here you can see that the Dells (1007 and 1016) perform better than any of the HPs, but it is also clear that the Intel-equipped machine has significantly lower iowait than the Samsung equipped one.
codfw
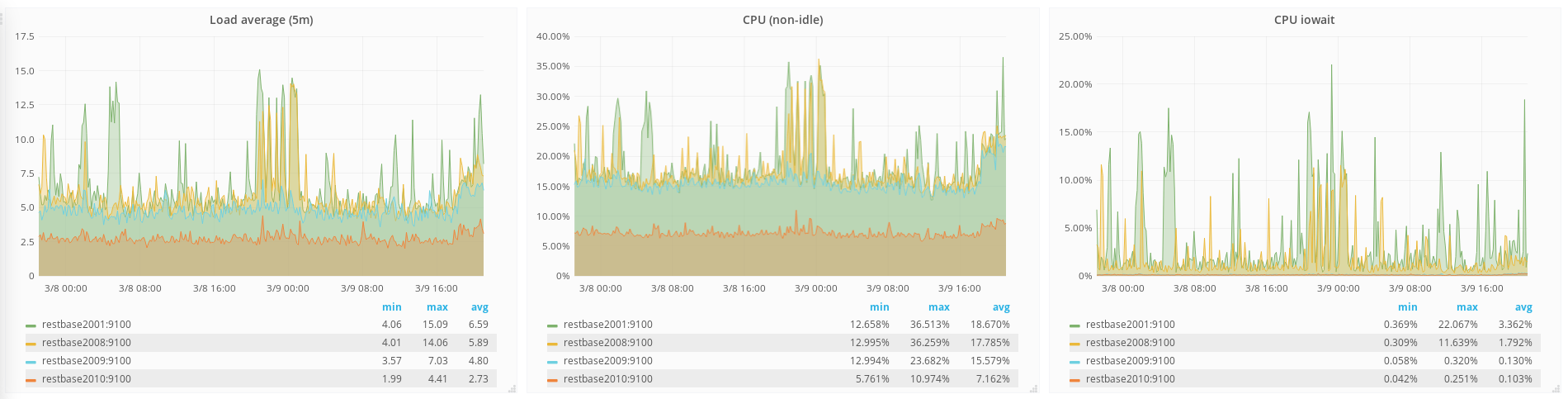
The above graph is of 2001, 2008, 2009, and 2010 which represents configurations #3, 4, 5, 2 respectively. What is interesting here is that the Samsung-equipped HPs (both single-disk RAID-0 and HBA configured) are characteristically bad, but the lone HP with the HP devices has comparable iowait to the Intel-equipped Dell.
We do not have any HPs equipped with the Intel disks, and it would be interesting to see how that combination compared; The restbase2009 configuration would seem to indicate that perhaps it's a mistake to correlate the poor(er) performance with the smartarray equipped HP machines.