Today some MediaWiki jobs that usually take ~ 10 minutes to accomplish end up reaching the 30 minutes timeout. They might be CPU starved, though I also noticed a few builds for which npm install took ~ 20 minutes by itself, so it might be a networking issue.
Example for the wmf-quibble-vendor-mysql-hhvm-docker job.
It roams among Jenkins slaves having the m4executor label.
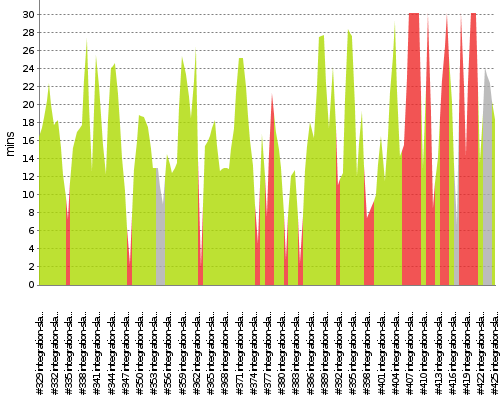
That job supposedly takes 12 minutes to run in the best case. The last few builds, some failed after the 30 minutes timeout (see below).
Update looks like the issue is npm install issuing npm ERR! registry error parsing json and idling/delaying install by 10 minutes.
$ curl https://registry.npmjs.org/cdn-cgi/trace fl=16f139 h=registry.npmjs.org ip=208.80.155.255 ts=1530197834.216 visit_scheme=https uag=curl/7.38.0 colo=IAD spdy=off http=http/1.1 loc=US
| Success | # | 425 | 18 min | integration-slave-docker-1011 |
| Aborted | # | 424 | 22 min | integration-slave-docker-1013 |
| Aborted | # | 423 | 24 min | integration-slave-docker-1006 |
| Success | # | 422 | 13 min | integration-slave-docker-1004 |
| Failed | # | 421 | 30 min | integration-slave-docker-1007 |
| Failed | # | 420 | 30 min | integration-slave-docker-1013 |
| Failed | # | 419 | 14 min | integration-slave-docker-1004 |
| Failed | # | 418 | 30 min | integration-slave-docker-1006 |
| Aborted | # | 417 | 6 min 42 sec | integration-slave-docker-1005 |
| Success | # | 416 | 20 min | integration-slave-docker-1005 |
| Failed | # | 415 | 30 min | integration-slave-docker-1005 |
| Failed | # | 414 | 22 min | integration-slave-docker-1011 |
| Success | # | 413 | 14 min | integration-slave-docker-1005 |
| Failed | # | 412 | 8 min 31 sec | integration-slave-docker-1008 |
| Failed | # | 411 | 30 min | integration-slave-docker-1001 |
| Success | # | 410 | 12 min | integration-slave-docker-1005 |
| Failed | # | 409 | 30 min | integration-slave-docker-1008 |
| Failed | # | 408 | 30 min | integration-slave-docker-1005 |
| Failed | # | 407 | 30 min | integration-slave-docker-1005 |
| Failed | # | 406 | 15 min | integration-slave-docker-1004 |
| Success | # | 405 | 14 min | integration-slave-docker-1004 |
| Success | # | 404 | 29 min | integration-slave-docker-1003 |
| Success | # | 403 | 21 min | integration-slave-docker-1010 |
| Success | # | 402 | 11 min | integration-slave-docker-1012 |
| Success | # | 401 | 16 min | integration-slave-docker-1006 |
| Success | # | 400 | 9 min 54 sec | integration-slave-docker-1015 |