Dear all,
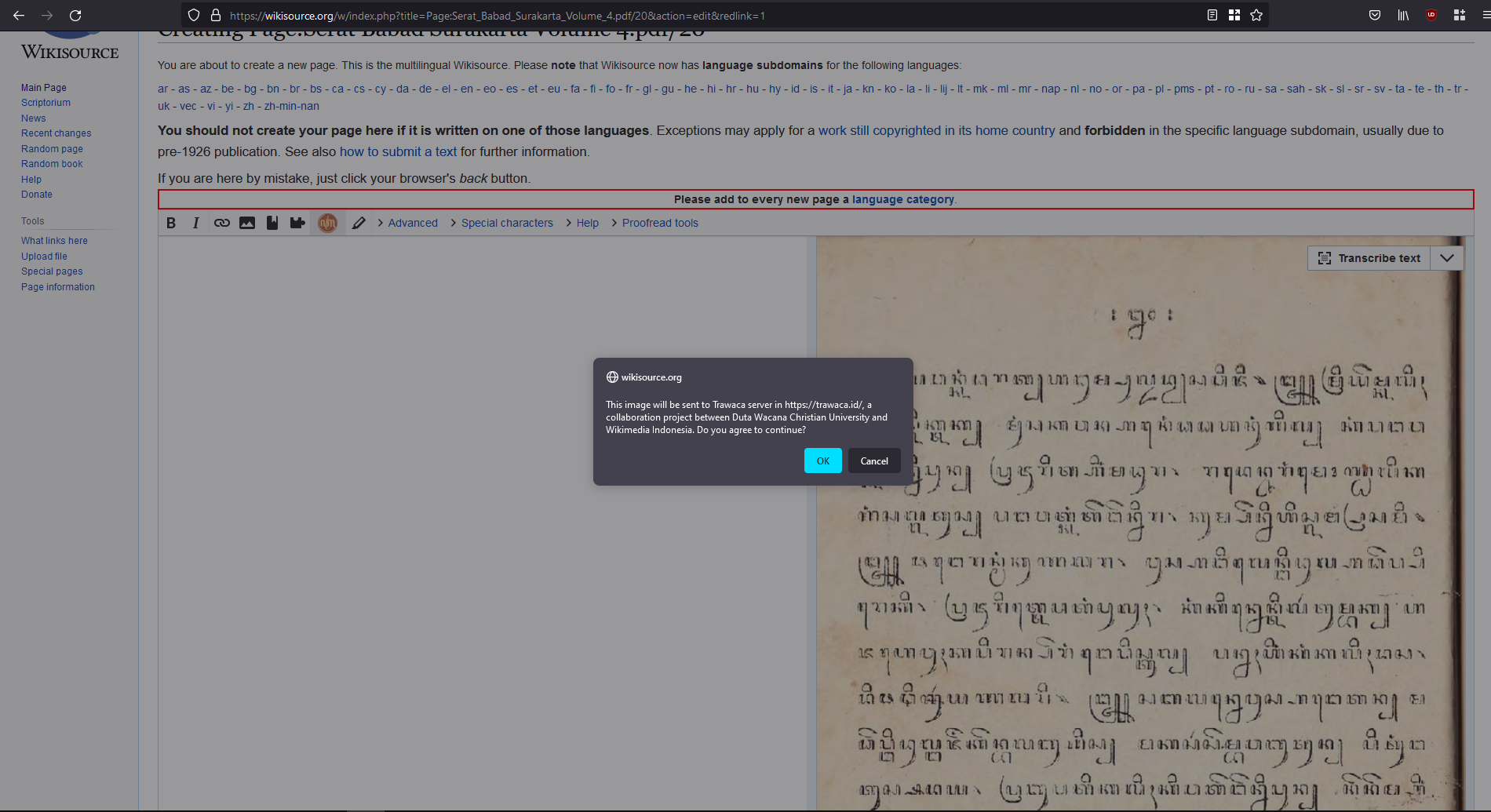
WMID and Universitas Kristen Duta Wacana in Yogyakarta, Indonesia, are in partnership to develop OCR system for Javanese characters. This will help people to transcribe text, which in Javanese characters, easily in Wikisource.
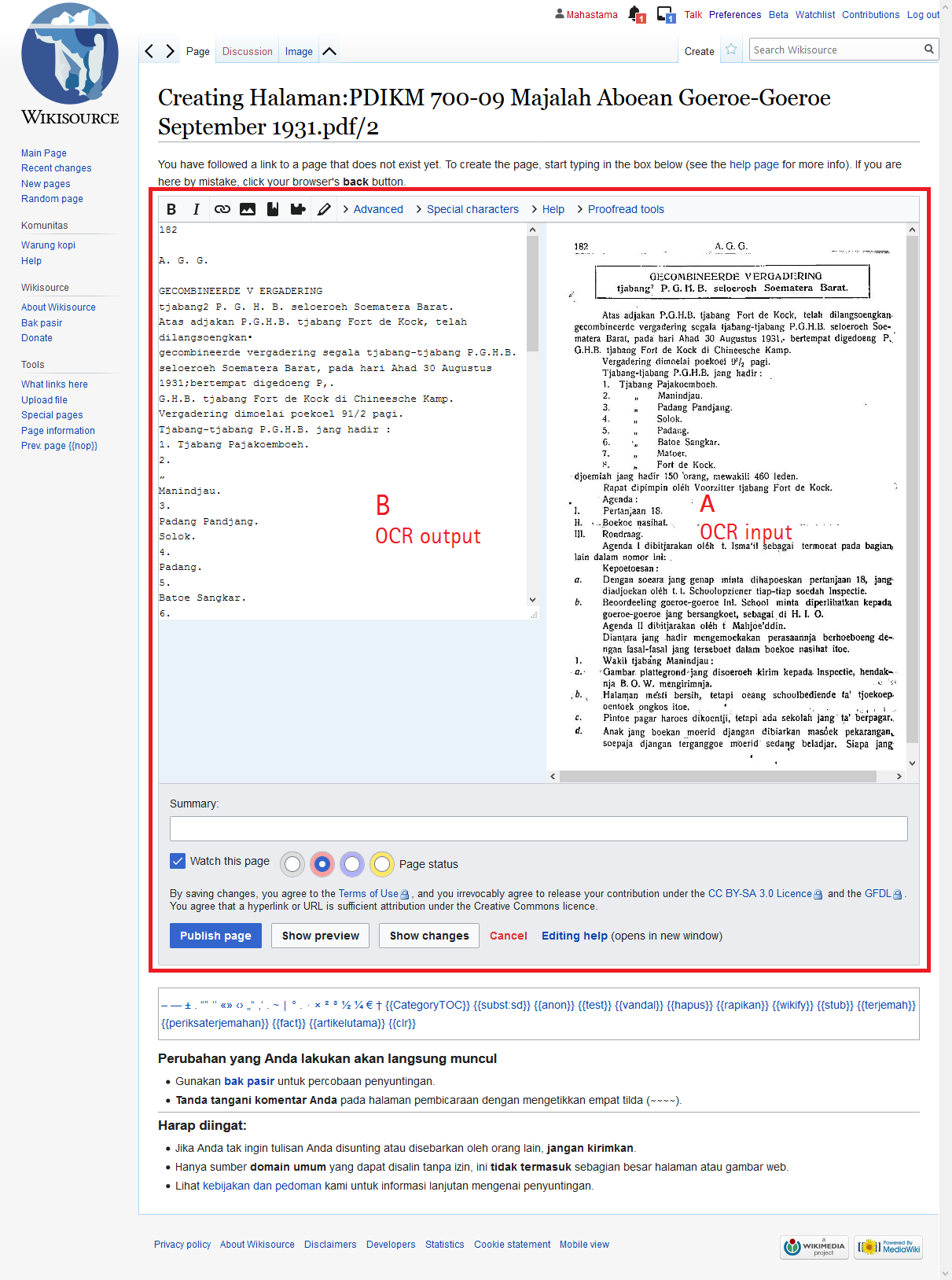
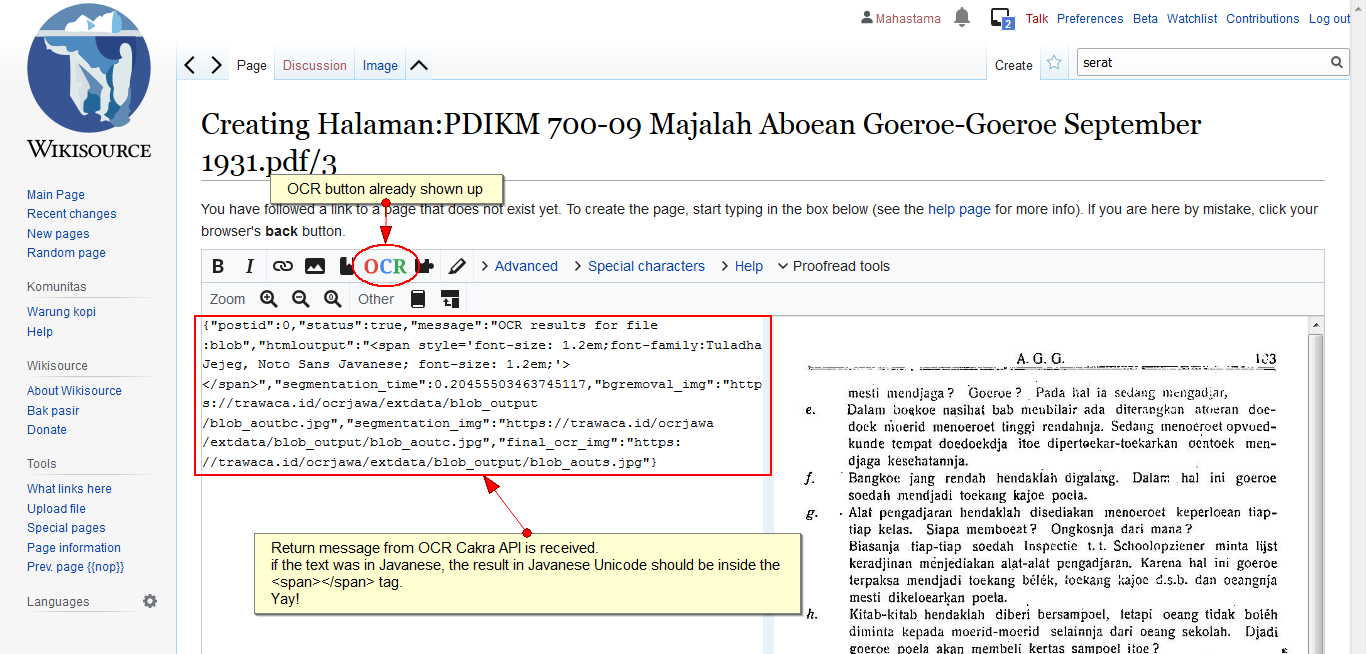
They have already developed a closed software system, to read the characters automatically and produce the results which can be copy and paste. The software is still apart from MediaWiki software. That means, people will have to upload the pages to the software, wait to be processed, and copy the OCR result to Wikisource. Until now, that is the workflow I know.
They want to open their code to Wikimedia projects under GNU GPL v2, however, we do not know how to port the code into the Wikisource platform.