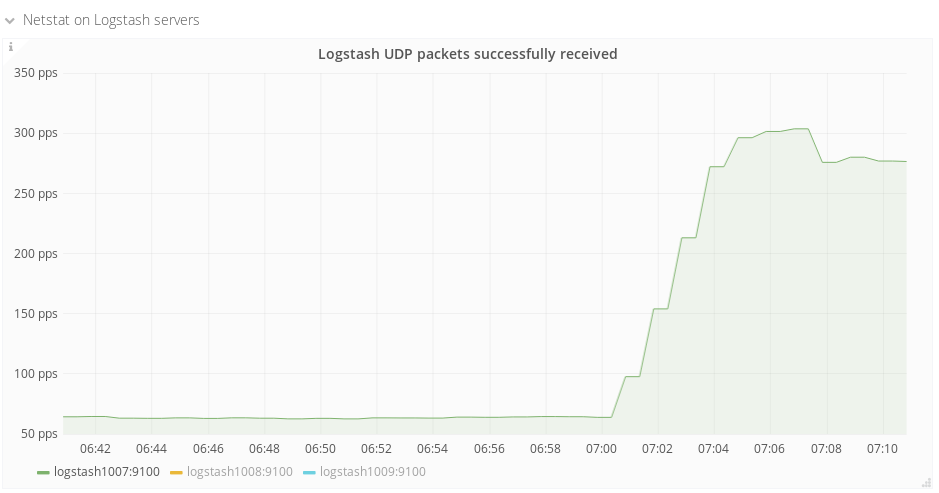
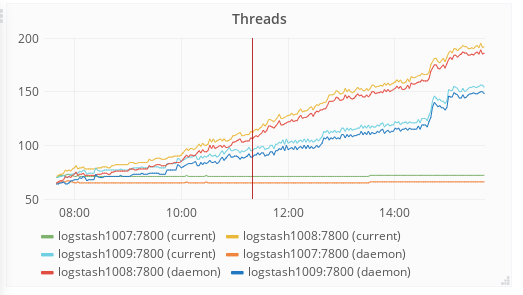
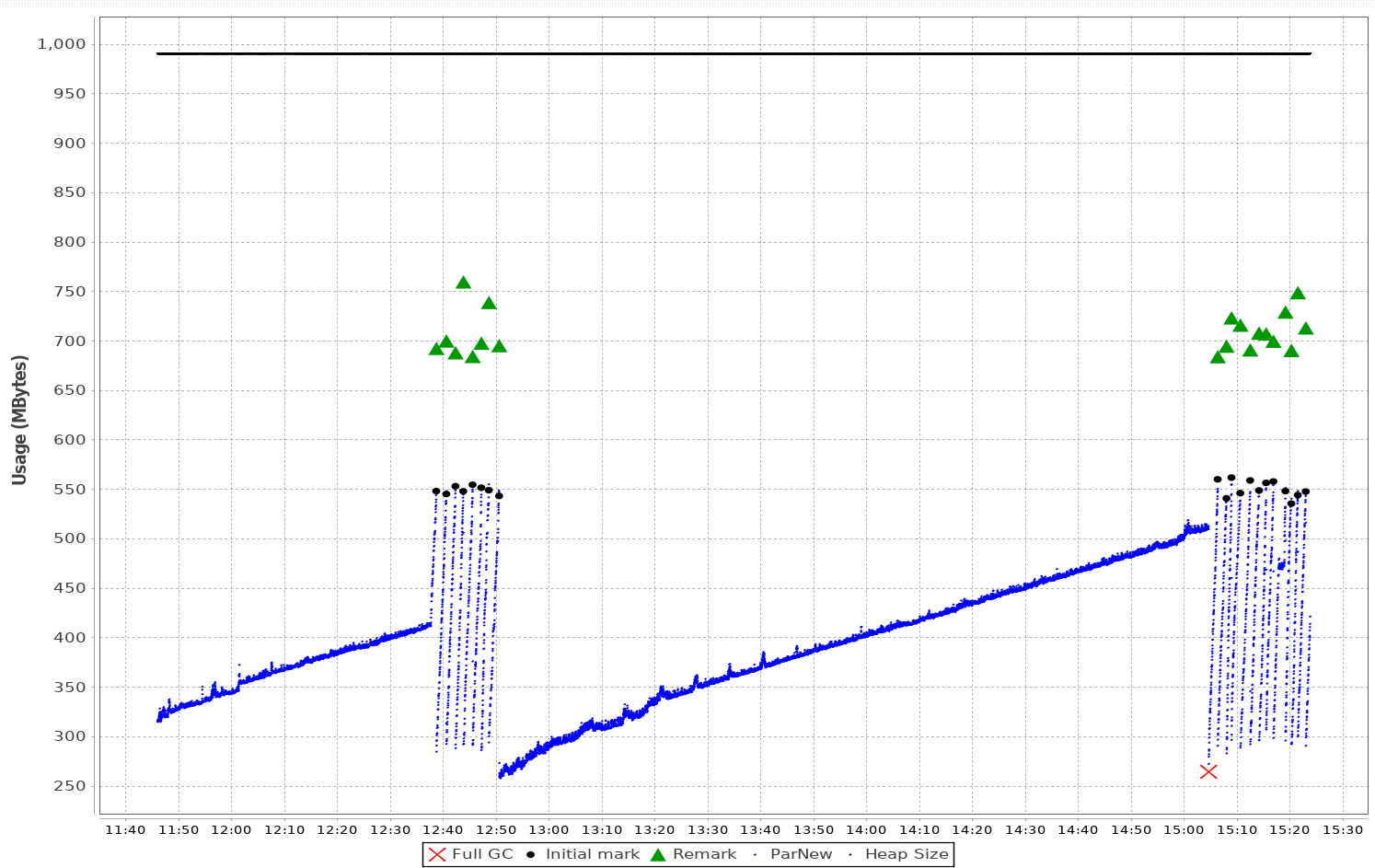
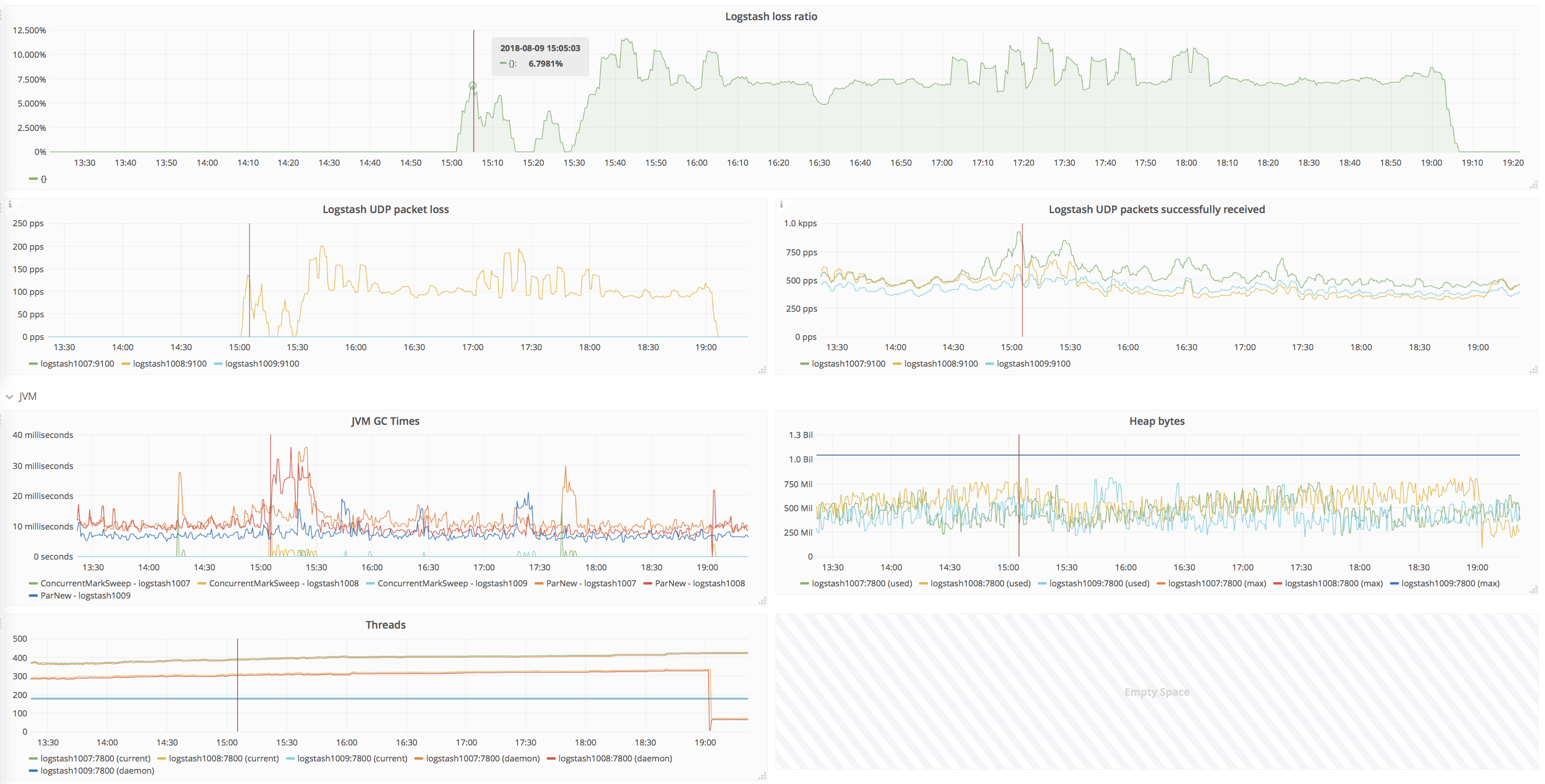
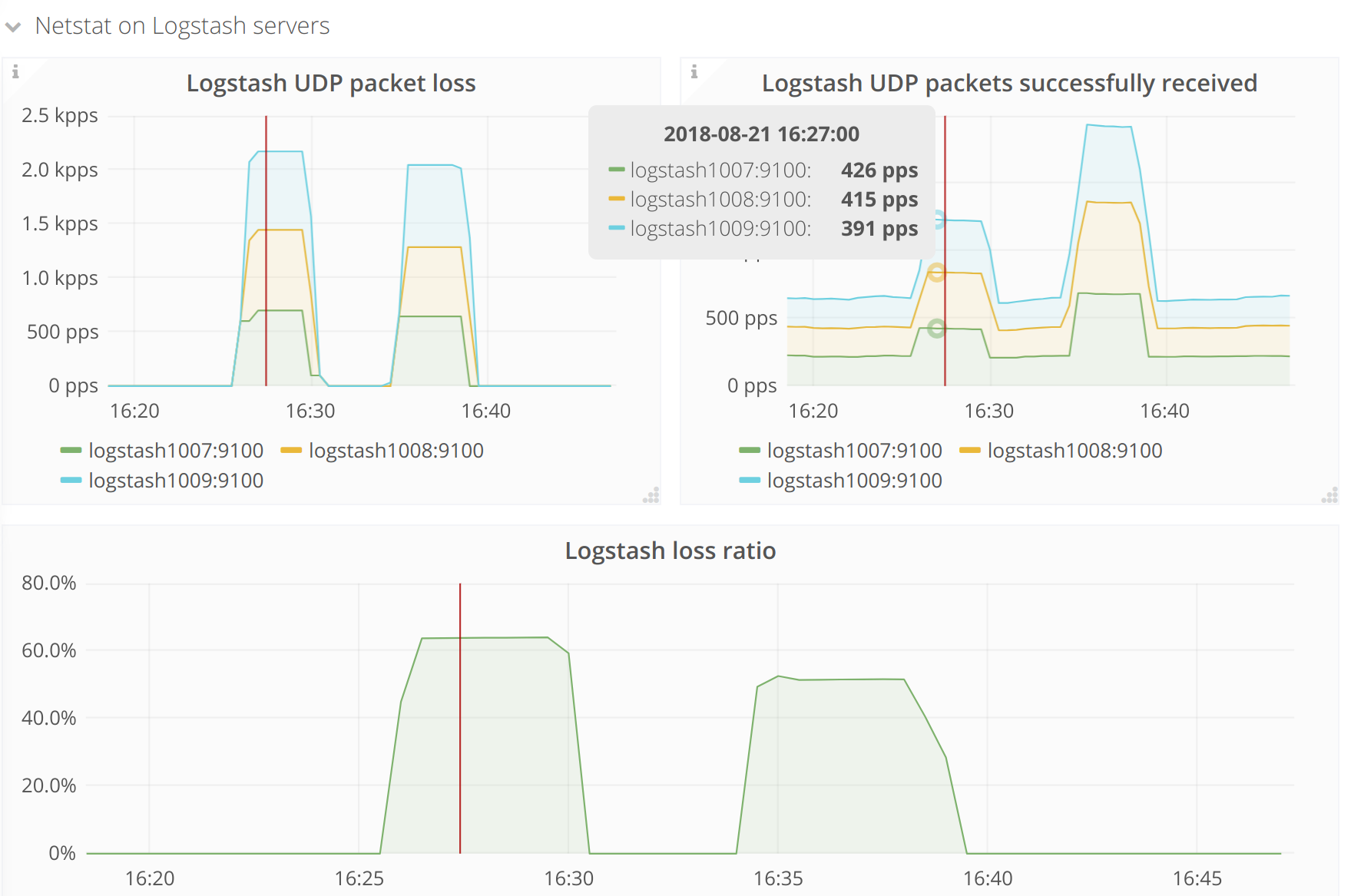
Logstash is losing about 3000-4000 UDP packets per second. The loss rate suddenly jumped up on about June 29. I made a Grafana dashboard showing the problem: https://grafana.wikimedia.org/dashboard/db/logstash?orgId=1
@Krinkle reported that many log events were missing from search results. The high loss rate would seem to explain this.
Logstash has a metrics API giving timing information for pipeline plugins. If we plotted rates from it, we might be able to figure out what the bottleneck is. For example:
[0209][root@logstash1007:~]$ curl -s 'localhost:9600/_node/stats/pipeline' | jq '.pipeline.plugins.inputs[0].events.queue_push_duration_in_millis' ; sleep 10; curl -s 'localhost:9600/_node/stats/pipeline' | jq '.pipeline.plugins.inputs[0].events.queue_push_duration_in_millis' 1619816401 1619823795
This shows the syslog input plugin (a single thread) consuming 74% of available time. Does it sleep for the other 26%?