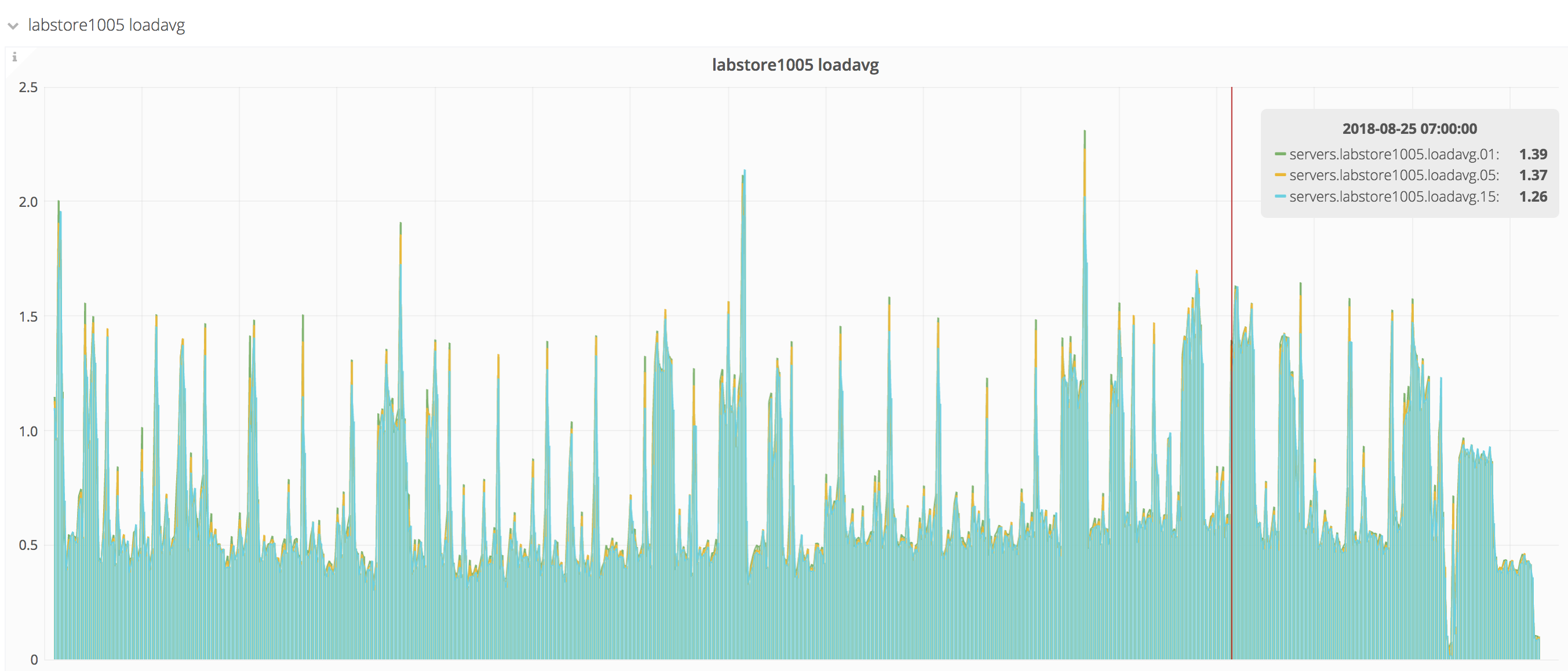
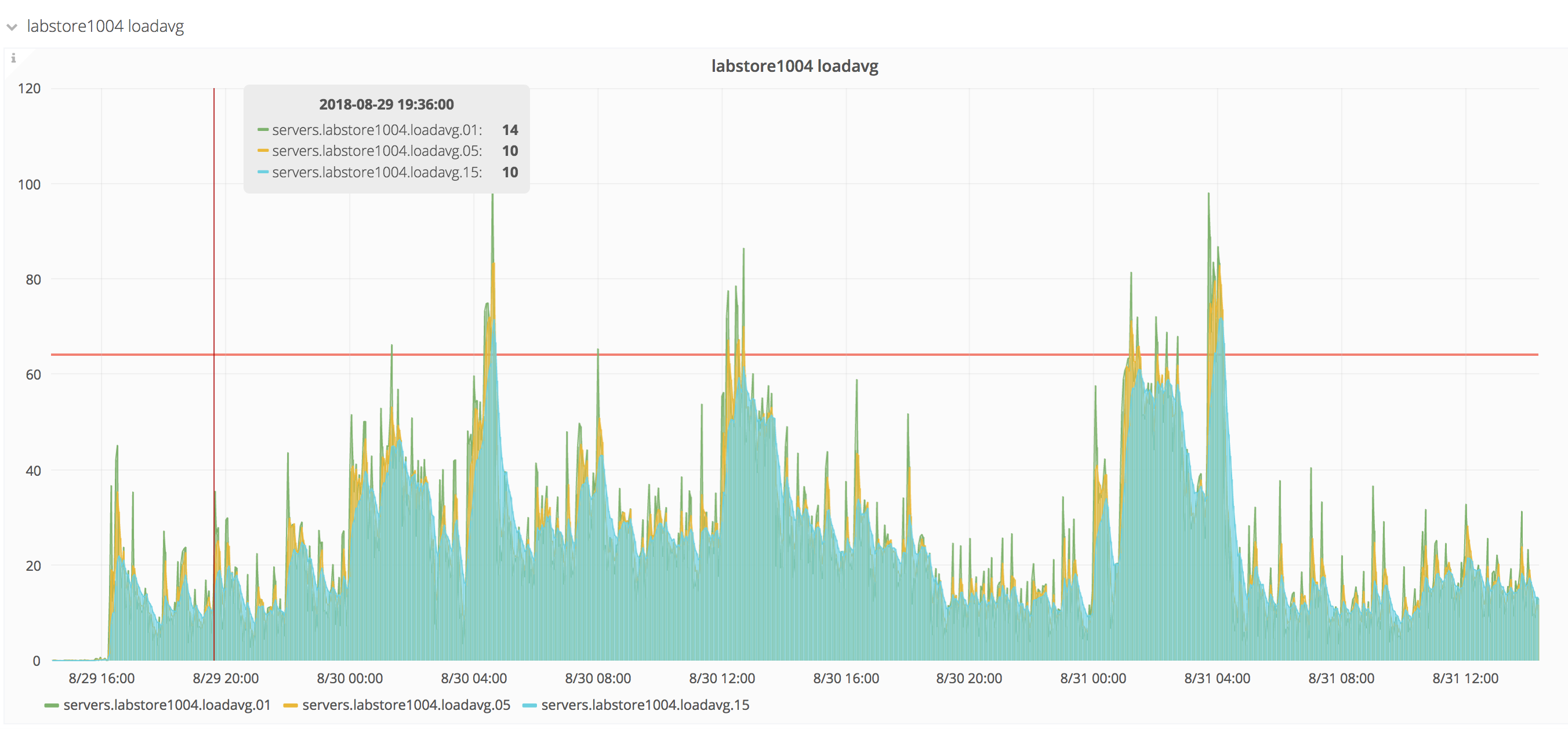
This is to track the issue and find resolution. After upgrading to the latest kernel, labstore1004 (the current primary) has changed it's load characteristics dramatically, riding at about a factor of 10 above previous levels. At this point, it doesn't seem to be causing significant problems for NFS client machines, but it is a problem for effective monitoring and heavy use scenarios.
The kernel we are currently experiencing this on is 4.9.0-0.bpo.8-amd64 #1 SMP Debian 4.9.110-3+deb9u4~deb8u1
Downgrading seems unwise due to security concerns and simply the age of the kernels we know don't do this.