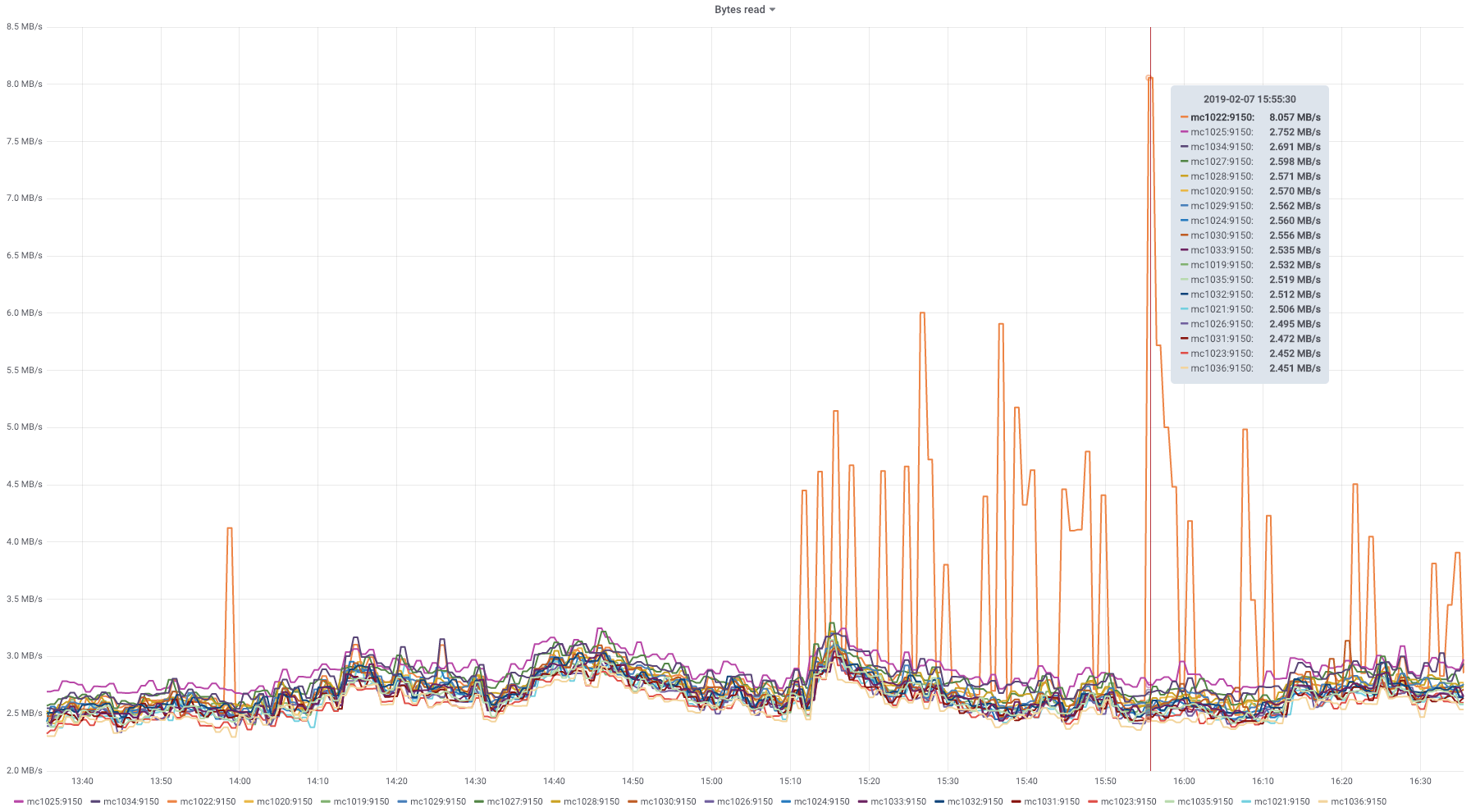
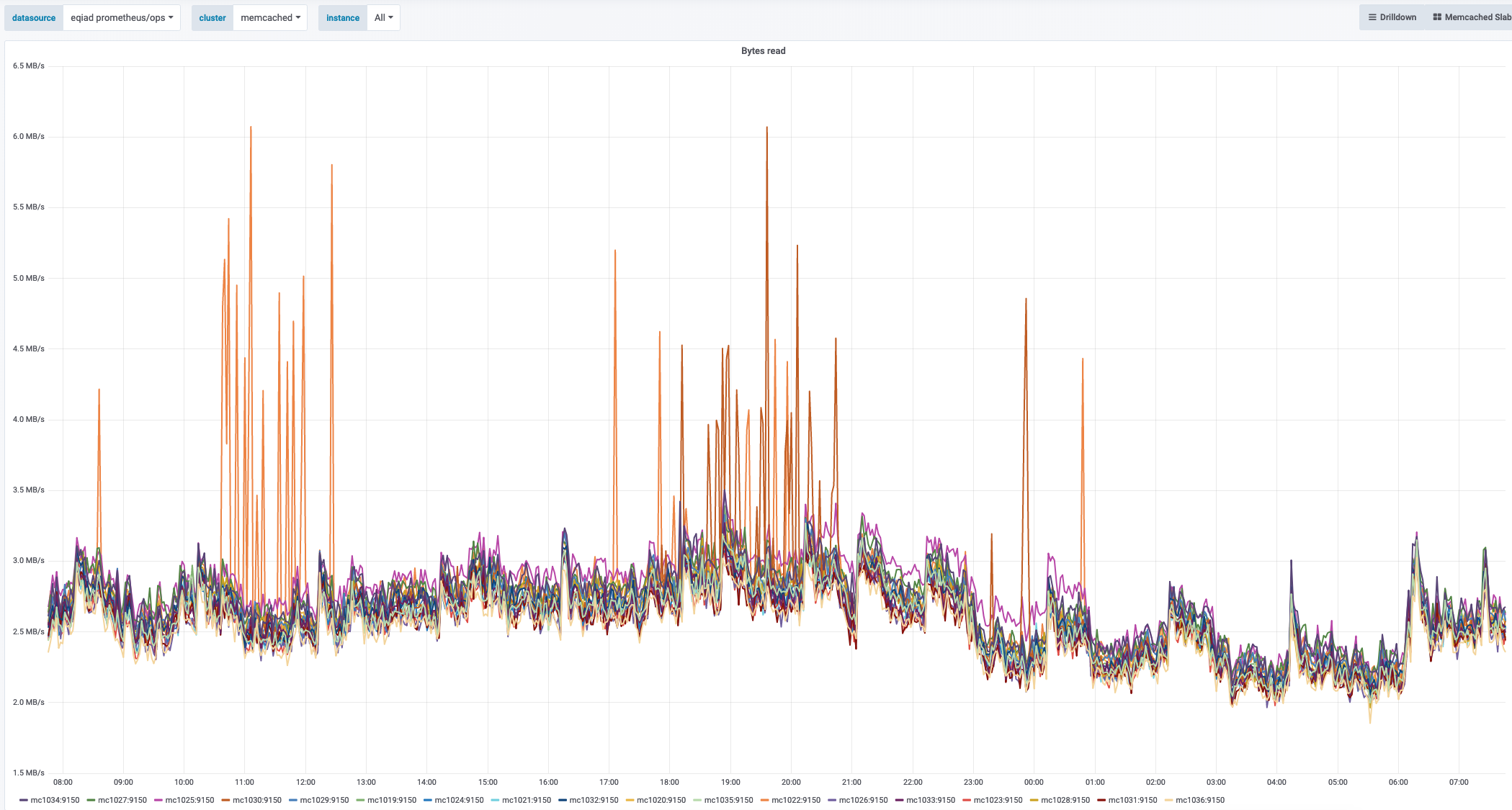
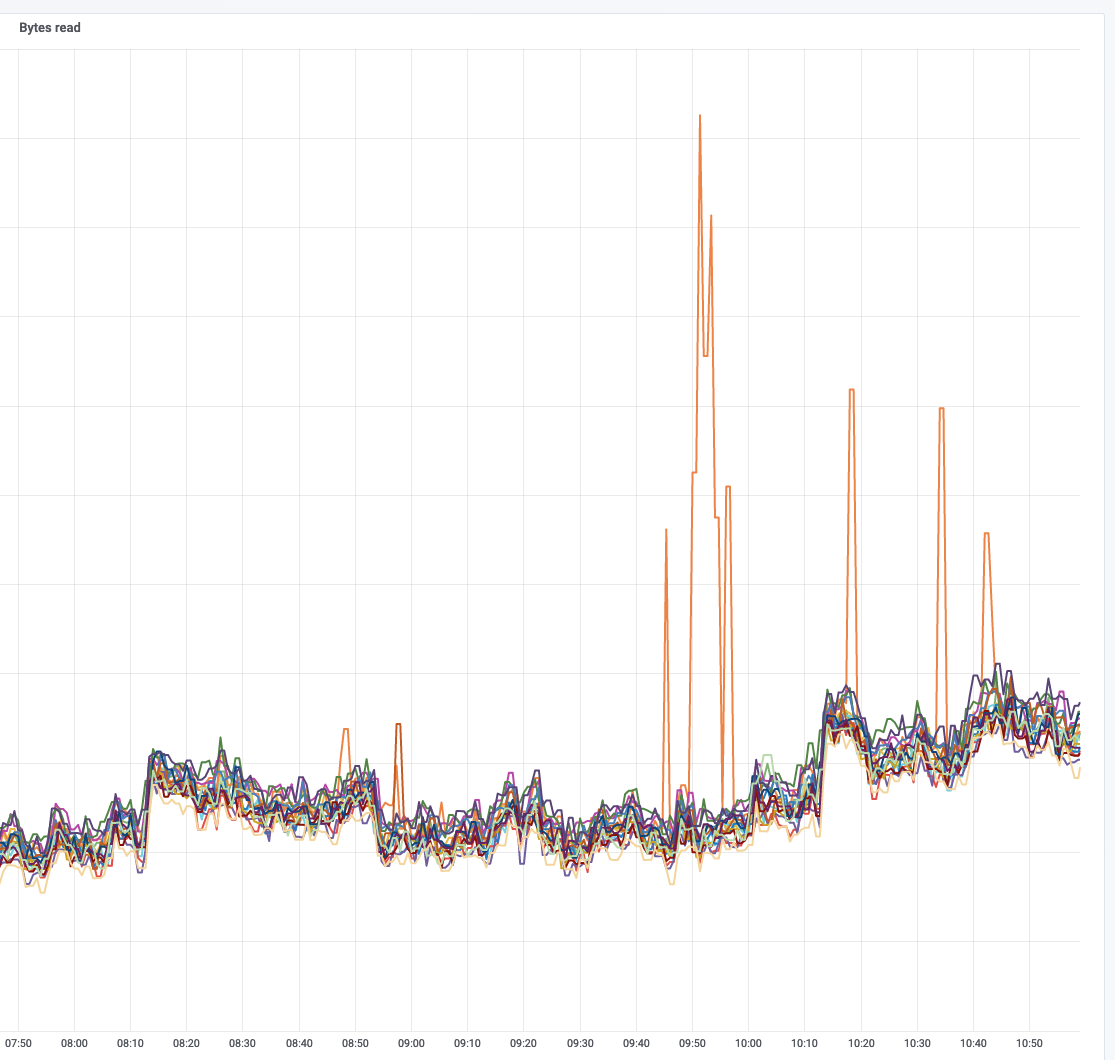
Icinga periodically reports Mediawiki Memcached exceptions that usually auto-resolve in a couple of minutes. Each time this is the workflow followed to narrow down the root cause:
- Check https://logstash.wikimedia.org/app/kibana#/dashboard/memcached
- Pick one host alarming for SERVER ERROR or TIMEOUT
- ssh to it, and check the /var/log/mcrouter.log
It usually contains something like:
Sep 7 12:04:27 mw1342 mcrouter[48145]: I0907 12:04:27.248368 48146 ProxyDestination.cpp:453] 10.64.48.157:11211 marked soft TKO. Total hard TKOs: 0; soft TKOs: 1. Reply: mc_res_timeout Sep 7 12:04:41 mw1342 mcrouter[48145]: I0907 12:04:41.204443 48146 ProxyDestination.cpp:453] 10.64.48.157:11211 unmarked TKO. Total hard TKOs: 0; soft TKOs: 0. Reply: mc_res_ok
The soft TKO is always for 10.64.48.157, that is mc1035.
What is a TKO? -> https://github.com/facebook/mcrouter/wiki/Features#health-checkauto-failover
This graph shows an unusual amount of SETs to a specific slab slot, and the key highlighted the most from memtop and logstash seems to be related to WANCache:t:commonswiki:gadgets-definition and WANCache:m:commonswiki:gadgets-definition:9:2.
There has been some discussion between @Joe and @Krinkle about this issue on IRC, I tried to report everything in this description but I am not sure if it is complete or not :)