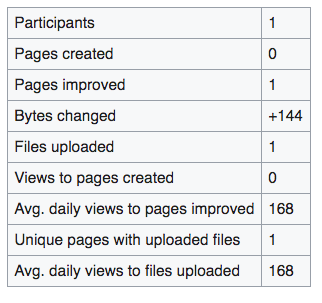
Implementation details
Create a way to fetch the number of views to articles that embed files that were uploaded during the event, and display them as 'average daily views'.
The query should:
- Fetch all files that were uploaded to Commons and to the local wikis specified in the event setting (the system currently only considers uploads to commons; this new method needs to add the ability to fetch the list of files uploaded to the local wikis too)
- There is a task to track uploads from the individual wiki (expanding the collection from Commons only) at task T206819: Create a method to fetch information about uploaded files in local wikis. That task is slightly broader (to enable using all metrics about uploads to show local wiki as well) but depending on your implementation approach, may need to be done before this current task.
- There's another related task at T215356: Create a method for counting 'Pages with uploaded files'
- For each of those uploaded files, get the articles they are used/embedded in. Article list should be unique (even if two files were uploaded to the same article, the article should be counted once)
- For each unique article, fetch daily pageviews from the present back to a maximum of 30 days and total that number. Then, to get the per-article average:
- If we have 30 days of pageviews, divide the total by 30.
- If we have fewer than 30 days of pageviews (presumably because the article was created fewer than 30 days ago), divide the total by the number of days for which we have figures.
- Next total the individual per-page averages to get the grand-total of "Avg. daily views to (all) files uploaded."
Deeper dive
Why we're doing this
Organizers, their sponsors and partners want to understand the impact of their work. One main way to do this for files uploaded is to see the number of pageviews those files get on the various article pages to which they are added. In our discussions, it has become clear that we can't get an accurate cumulative pageviews figure because we don't know the dates when specific files were added to specific articles. So instead, we will be providing a figure for "average daily pageviews".
Parameters
- All filetypes: The figure will track images, video files, audio files and other upload types.
- Uploads to Commons and local Wikipedias: We will track uploads to all wikis, so long as they are specified as wikis of interest for the event.
- Pageviews on all wikis (not just those specified): The Main space articles whose pageviews we're counting can be on any wiki; the wikis do not need to be specified as wikis of interest in setup.
- Reports this metric appears in: "Avg. daily views to files uploaded " appears in the Event Summary reports (CSV T205561, wikitext T206692 and onscreen T216447).
- 30-day average We'r using a 30-day average to smooth out daily or weekly fluctuations.