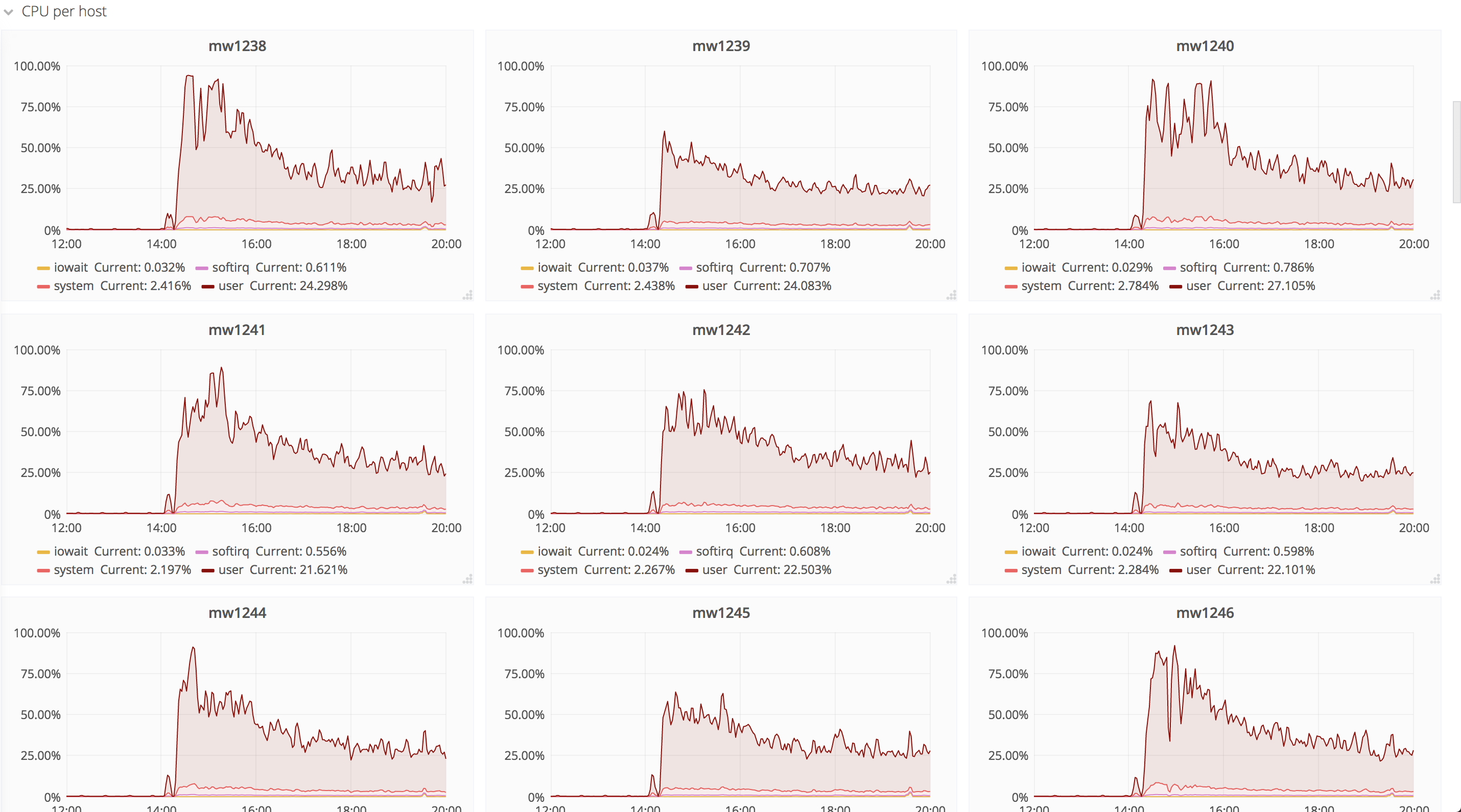
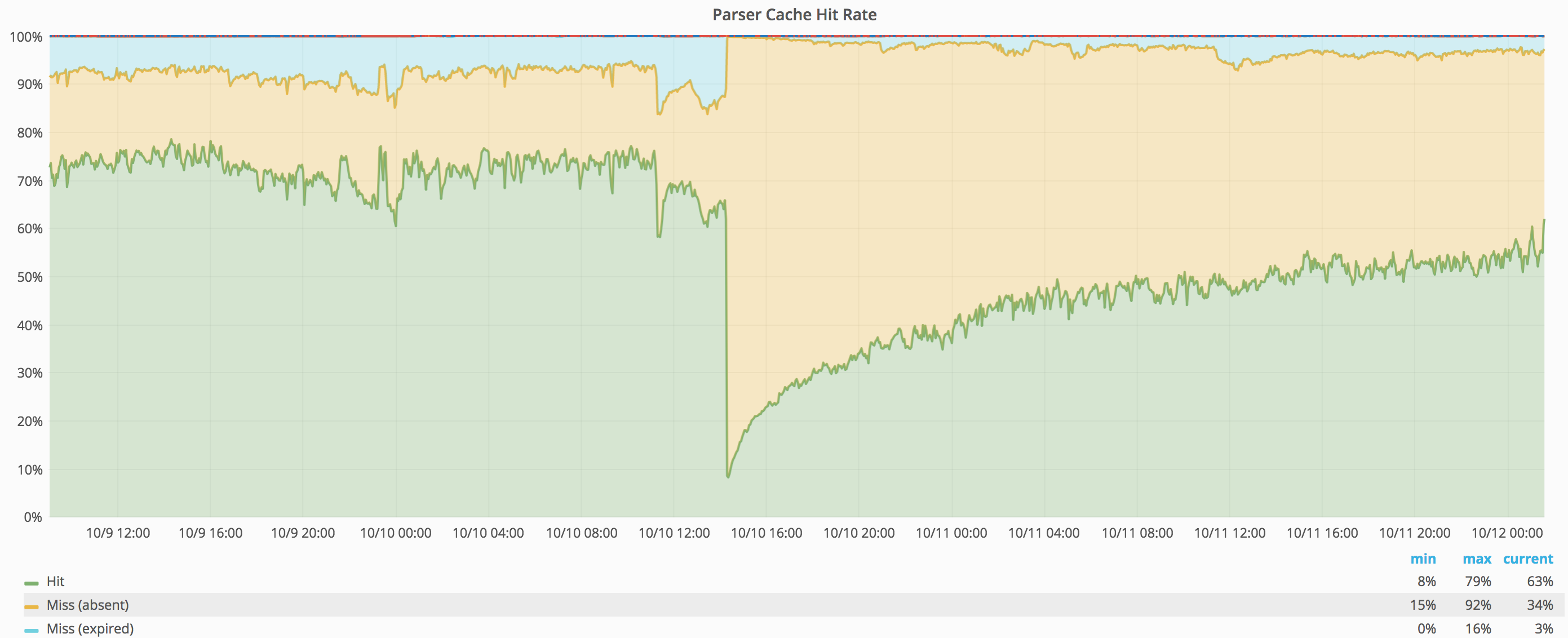
Looks like that yesterday at around 14:23 our parchercache hosts started to experience an increase on used disk space.
After we settle back to normal operation:
- The binlog purger should be stopped on pc1004**
- The binlog purger should be stopped on pc1005**
- The binlog purger should be stopped on pc1006**
- The binlog purger should be stopped on pc2004**
- The binlog purger should be stopped on pc2005**
- The binlog purger should be stopped on pc2006**
- The tables in 'parsercache' schema should be truncated on pc2004
- The tables in 'parsercache' schema should be truncated on pc2005
- The tables in 'parsercache' schema should be truncated on pc2006
- max_binlog_size should be set back to 1048576000*
* there were a lot's of data purged already, but the innodb won't free up space automatically ** they're running inside screen named 'purge' (screen -r purge) *** or chage that in config too