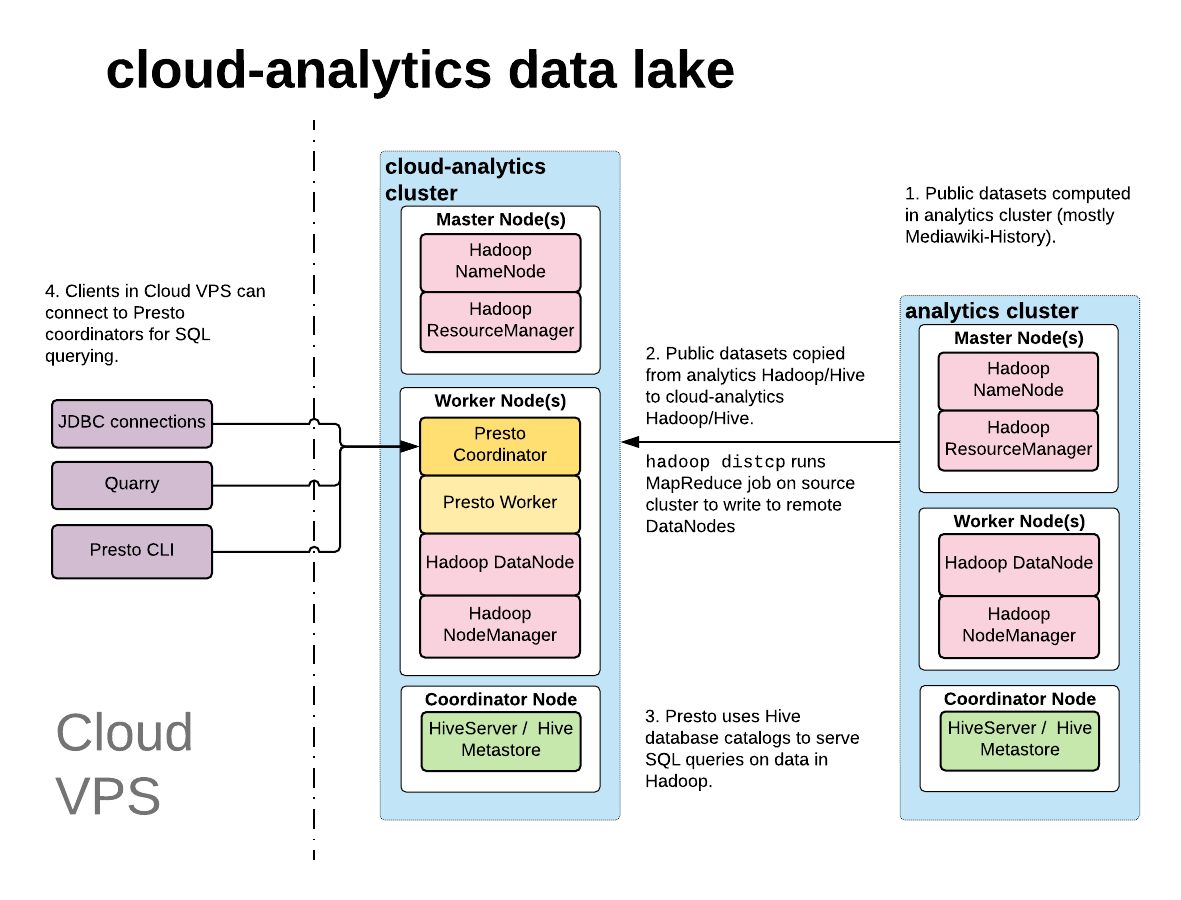
We're creating a second Hadoop cluster on which we will also install Hive and Presto. This cluster will host public datasets (no private data) like the mediawiki_history table (which itself is built from the replicated tables in labsdb). This cluster is the 'big data'/OLAP version of labsdb.
This cluster needs to be queryable (on restricted ports TBD) from Cloud VPS networks, and it also needs to be accessible by nodes in the Analytics VLAN. Datasets like mediawiki_history will be computed in the existent Analytics Hadoop cluster and pushed over to the cloud-analytics Hadoop cluster for querying from Cloud VPS.
@faidon mentioned that we need to discuss to figure out where these nodes should live, networking-wise. There are two tickets to set them up, 5 are bare metal, the other 3 are ganeti instances: T207194: rack/setup/install cloudvirtan100[1-5].eqiad.wmnet and T207205: Set up 3 Ganeti VMs for datalake cloud analytics Hadoop cluster.
Can we use the same networking model we use for labsdb hosts, or do we need to do something different/better?