The recabling should not cause any service interruption even though it caused some few seconds downtime for a similar recabling in eqiad, so the site should be depooled to be on the safe side.
All servers in row C are listed on https://netbox.wikimedia.org/dcim/devices/?tenant=0&q=&sort=name&rack_group_id=13&role=server
The rack C4 switch replacement will cause up to 30min downtime for the following servers:
https://netbox.wikimedia.org/dcim/devices/?rack_id=62&rack_group_id=13&role=server&status=1&tenant=0&q=&sort=name
One mc, 11*wtp, 27*mw
cc @Joe and @elukey to know if that's okay
Looking at doing it Wednesday 7th - 4pm UTC - 10am Dallas time
1/preparations
- Rack QFX [papaul]
- Connect console [papaul]
- Connect USB drive containing Junos 14.1X53-D43.7 (present in install2002:/home/ayounsi/jinstall-qfx-5-14.1X53-D43.7-domestic-signed.tgz) [papaul]
- Pre-populate SFP-Ts [papaul]
ge-4/0/1 ge-4/0/2 ge-4/0/3 ge-4/0/4 ge-4/0/5 ge-4/0/6 ge-4/0/7 ge-4/0/8 ge-4/0/9 ge-4/0/10 ge-4/0/11 ge-4/0/12 ge-4/0/13 ge-4/0/14 ge-4/0/15 ge-4/0/16 ge-4/0/17 ge-4/0/18 ge-4/0/19 ge-4/0/20 ge-4/0/21 ge-4/0/22 ge-4/0/23 ge-4/0/24 ge-4/0/25 ge-4/0/26 ge-4/0/27 ge-4/0/28 ge-4/0/29 ge-4/0/30 ge-4/0/31 ge-4/0/32 ge-4/0/33 ge-4/0/34 ge-4/0/35 ge-4/0/36 ge-4/0/37 ge-4/0/38 ge-4/0/39
- Upgrade and configure VCP on QFX [arzhel]
request system software add jinstall-qfx-5-14.1X53-D43.7-domestic-signed.tgz force-host... request virtual-chassis mode fabric mixed local request system zeroize
- Get QFX serial# [arzhel]
- Pre run VC links [papaul]
2/ recabling
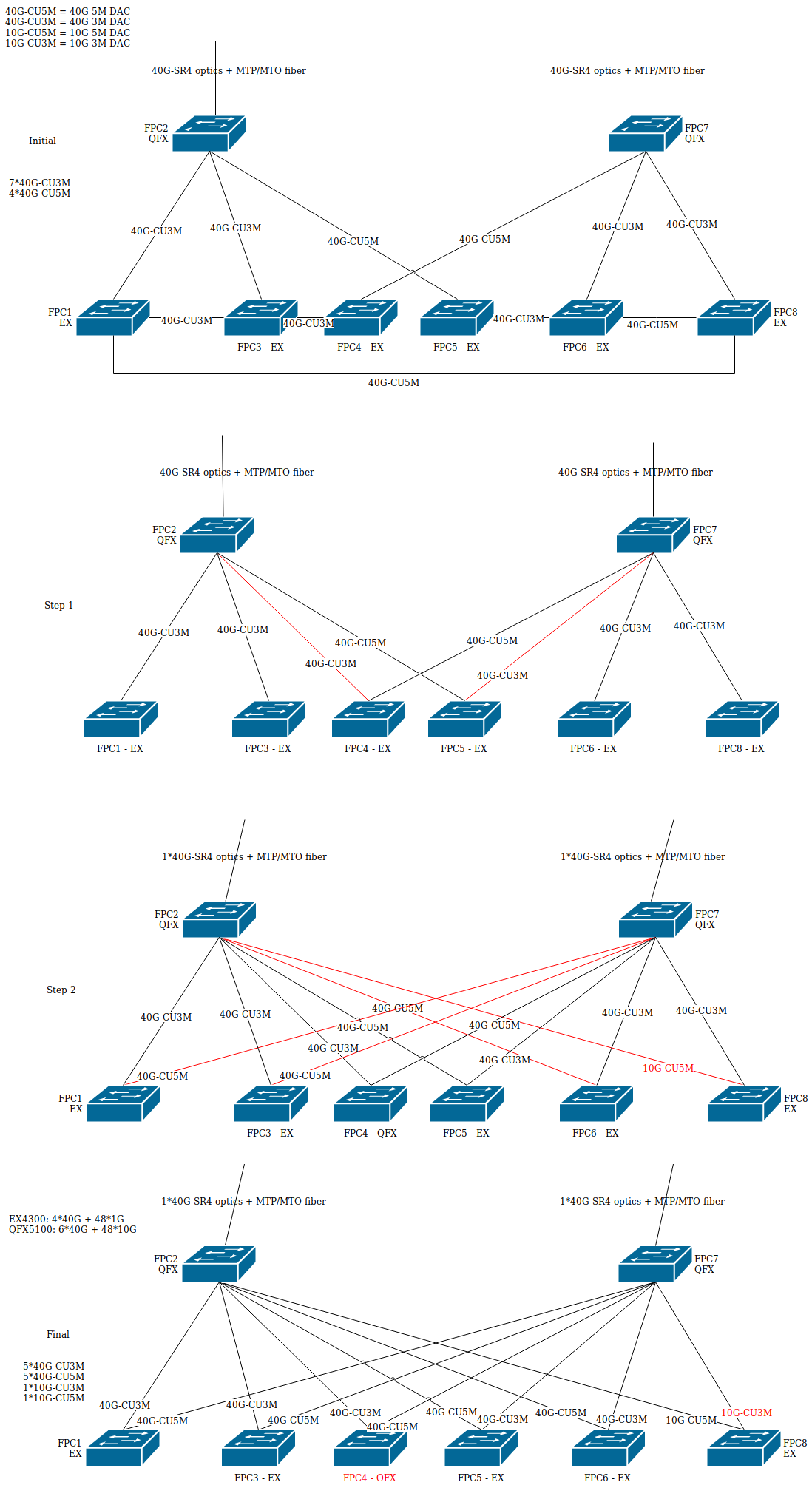
Ignore FPC8 as C8 is the frack rack
- Depool site in DNS
- Redirect eqsin/ulsfo caches to eqiad
- Enable all VC ports (except uplinks) on spines [arzhel]
- Shutdown fpc8 [arzhel]
- remove fpc8 from config [arzhel]
- remove fpc8 VC links [papaul]
- Add: [papaul]
fpc2-fpc4
fpc5-fpc7
- Confirm working [arzhel]
- Remove: [papaul]
fpc3-fpc4
fpc3-fpc1
fpc5-fpc6
- Add: [papaul]
fpc1-fpc7
fpc3-fpc7
fpc2-fpc6
- Confirm working [arzhel]
- cleanup unused VC ports [arzhel]
3/ FPC4 replacement
- Downtime hosts in Icinga [arzhel]
- Shutdown EX [arzhel]
- Reconfigure VCP with QFX serial# [arzhel]
set virtual-chassis member 4 serial-number XXXX
- Power on QFX [papaul]
- Enable VC ports on QFX
request virtual-chassis vc-port set pic-slot 0 port 52 local request virtual-chassis vc-port set pic-slot 0 port 53 local
- Move VC cables from EX to QFX [papaul]
- Move servers' uplinks from EX to QFX [papaul]
- Repool site [arzhel]
- Update Netbox [papaul]
https://www.juniper.net/documentation/en_US/junos/topics/task/configuration/vcf-removing.html
https://www.juniper.net/documentation/en_US/junos/topics/task/configuration/vcf-adding-device.html