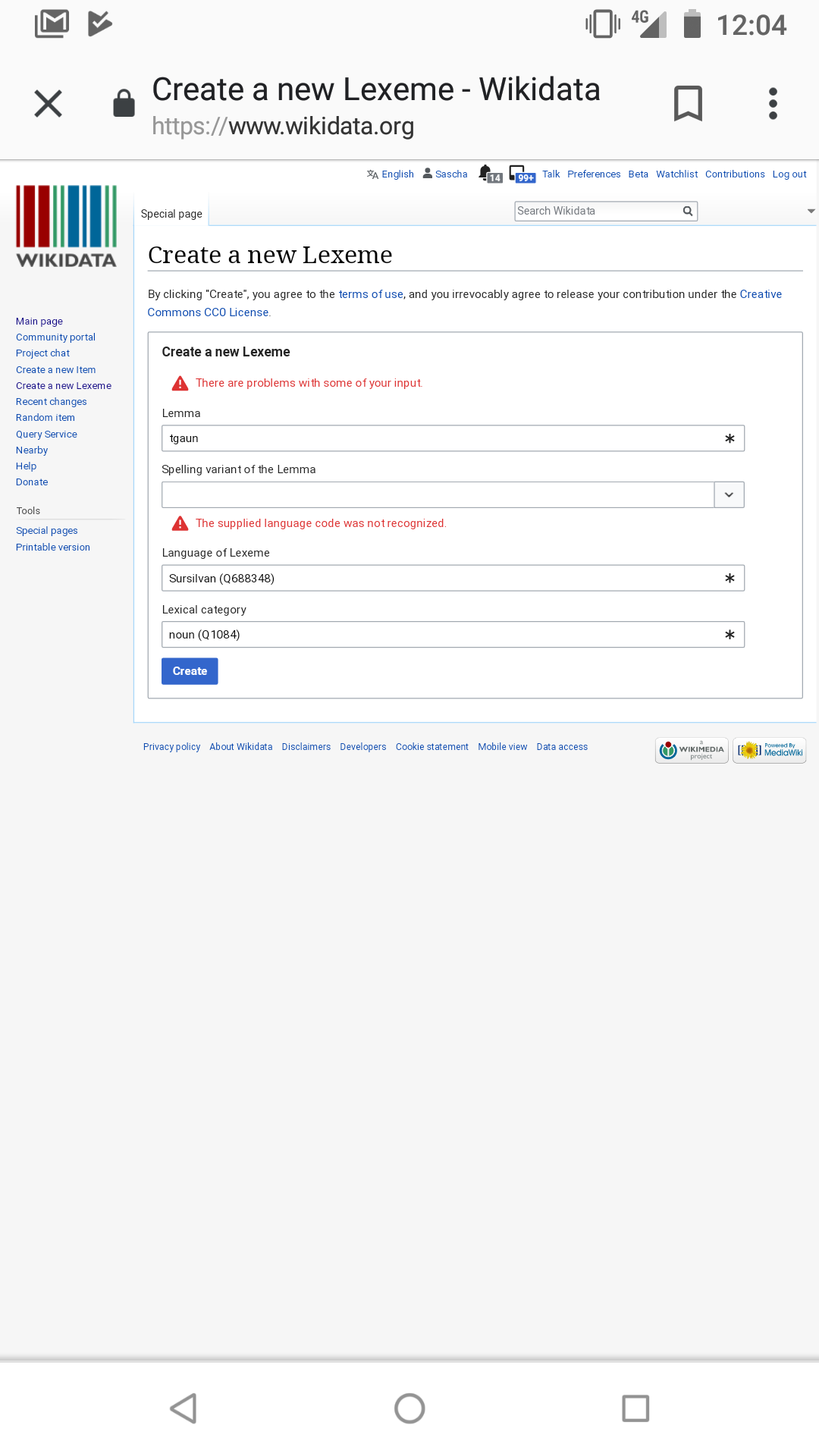
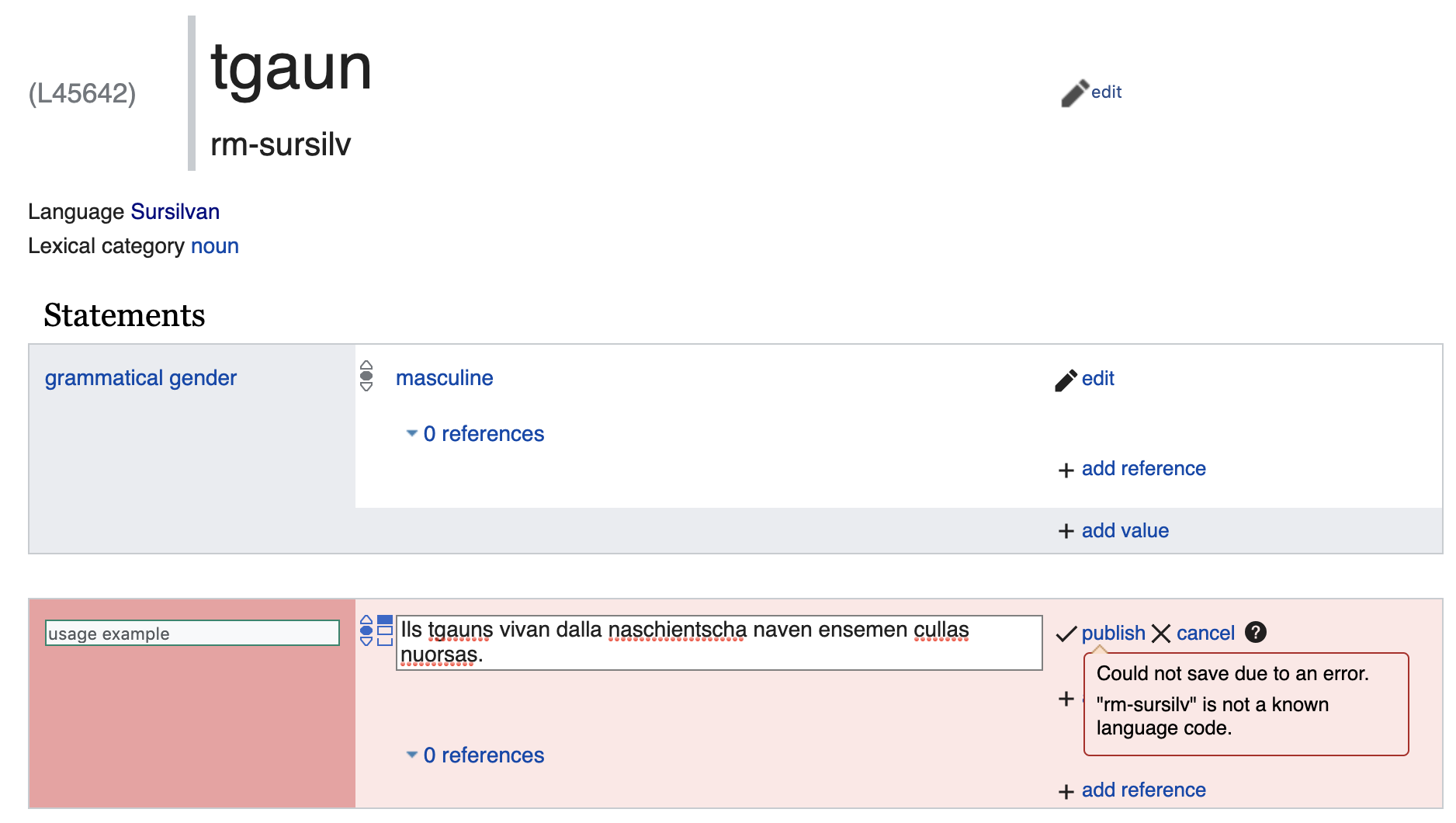
Please add the five language codes {rm-rumgr, rm-sursilv, rm-sutsilv, rm-vallader, rm-puter} to the list of language codes supported for Lexemes.
As per the IETF BCP47 language subtag registry [https://www.iana.org/assignments/language-subtag-registry/language-subtag-registry], rm-rumgr is the BCP47 language code for Rumantsch Grischun; rm-surmiran for Rumantsch Surmiran; rm-sutsilv for Rumantsch Sutsilvan; rm-sursilv for Rumantsch Sursilvan; rm-vallader for Rumantsch Vallader; rm-puter for Rumantsch Puter.
From a lexicographical perspective, these language variants are quite distinct: they have different vocabularies, different phonology, and inflection. (That’s also why they have different subtags in IETF BCP47). For reference, see http://www.pledarigrond.ch which has separate dictionaries for each variant.
In Wikidata, rm-rumgr is Q688873; rm-surmiran is Q690216; rm-sutsilv is Q688272; rm-sursilv is Q688348; rm-vallader is Q690226; rm-puter is Q688309.