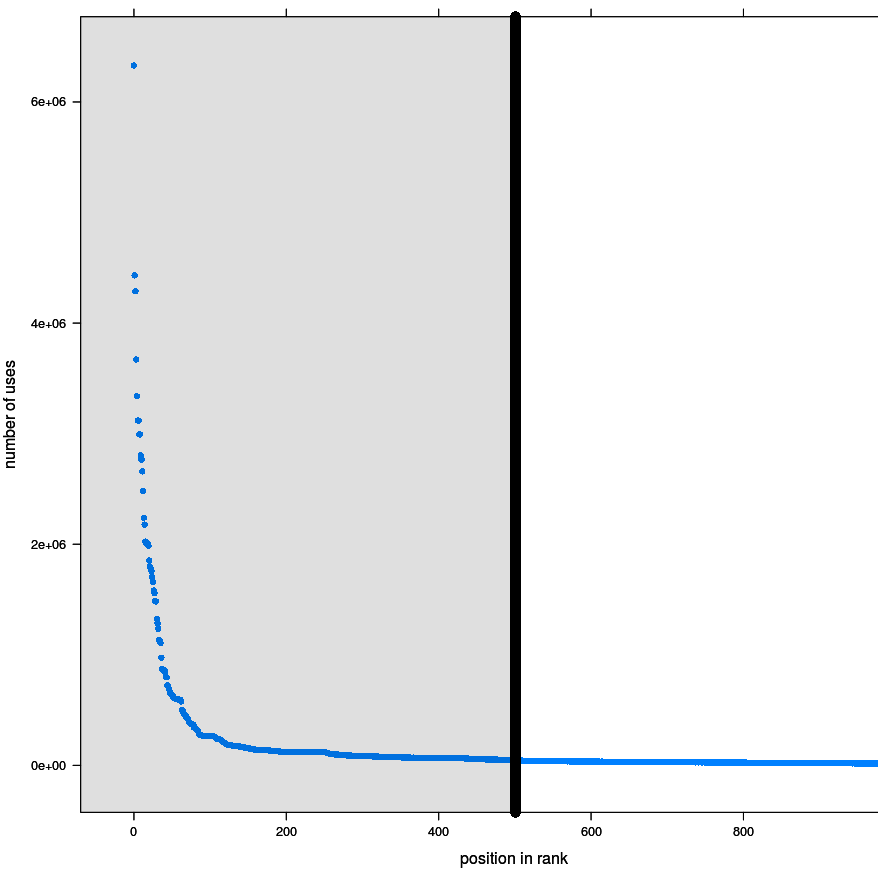
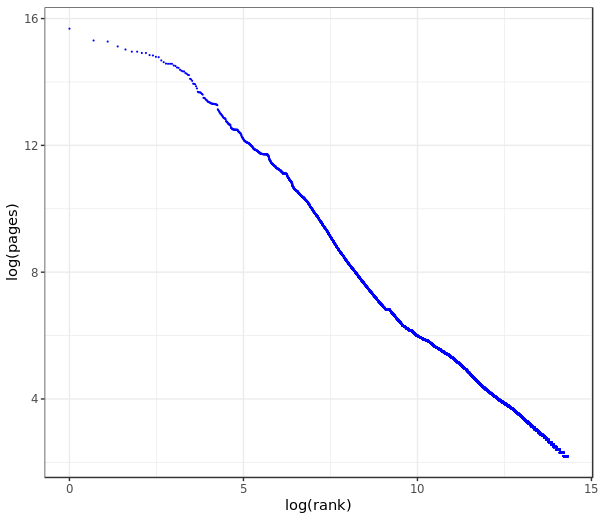
As a Wikidata editor I want to regularly check which Wikidata entities are the most used on the Wikimedia projects (as the number of Wikimedia pages containing data from them, something similar to Special:MostTranscludedPages) in order to be aware of Wikidata's weaknesses, know how much damage a vandal can cause when modifying these entities and make decisions about them (watching, protecting, etc.).
Problem: Vandalism on a single Item can cause thousands of pages in several projects to appear vandalized.
Example:
Screenshots/mockups:
BDD
GIVEN
AND
WHEN
AND
THEN
AND
Acceptance criteria:
- I would expect to get a list of entities ordered by the number of Wikimedia pages on which these entities are used (first the most used one) with at least the following information about each of them:
- identifier (QX, LY, etc.),
- label in my language,
- current protection status, and
- number of uses (Wikimedia pages).
- The list should be as long as technically reasonable.
Open questions:
- Should only administrators be able to access the list?
See also
- T144923, about Special:EntityUsage.