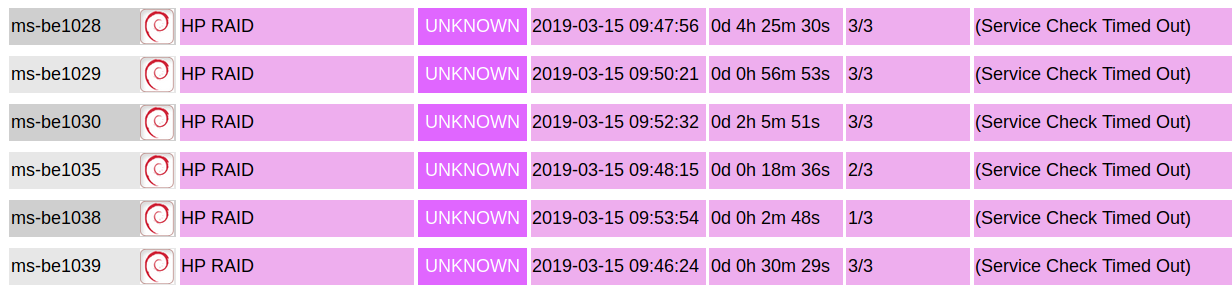
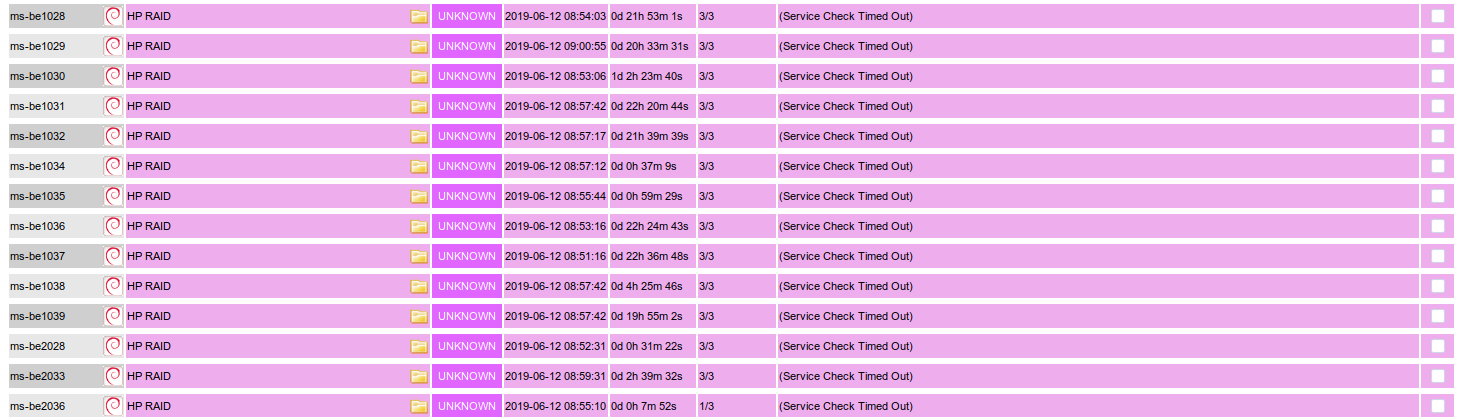
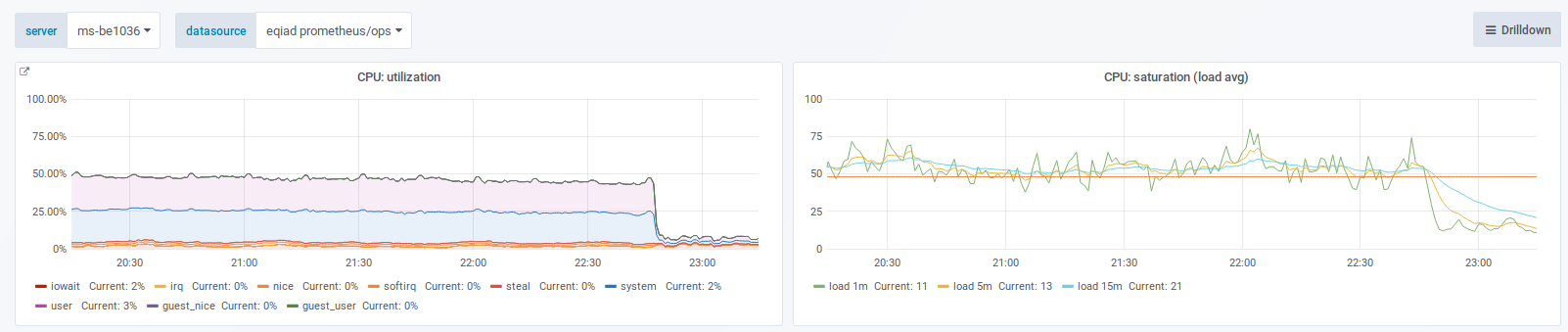
The "HP RAID" check (check_hpssacli) is known to timeout on busy ms-be hosts. The timeout has been recurring now for a while on icinga and doesn't provide a whole lot of value in this state.
Potential solutions in no particular order:
- Increase nrpe server timeout
- Increase check retries
- Move to an asynchronous check model, where the generating results and checking for alert states are decoupled