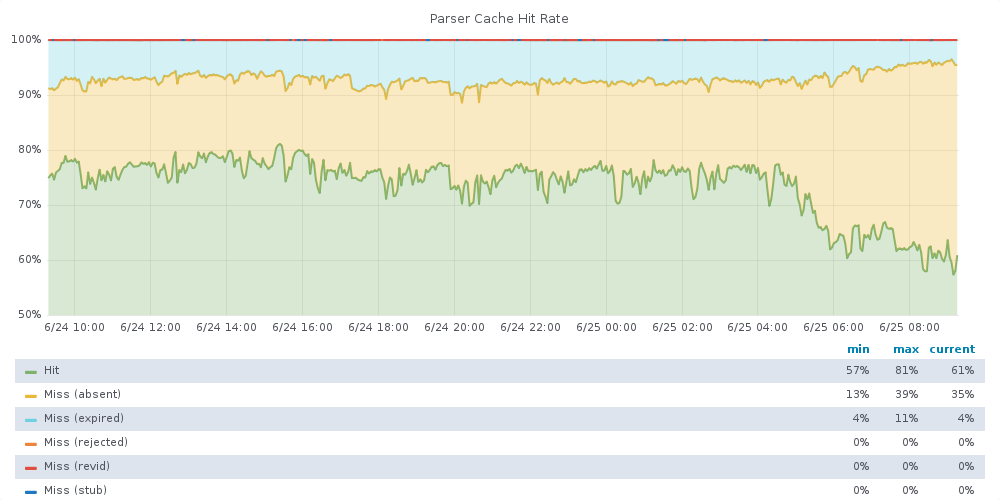
Right now the parsercache structure on db-eqiad.php and db-codfw.php looks like:
$wmgParserCacheDBs = [
'10.64.0.12' => '10.192.0.104', # pc2007, A1 4.4TB 256GB
'10.64.32.72' => '10.192.16.35', # pc2008, B3 4.4TB 256GB
'10.64.48.128' => '10.192.32.10', # pc2009, C1 4.4TB 256GB
# 'spare' => '10.192.48.14', # pc2010, D3 4.4TB 256GB # spare host. Use it to replace any of the above if neededThose first column of IPs (10.64.0.12, 10.64.32.72, 10.64.48.128) are not really IPs but sharding keys.
Those are very confusing specially while doing maintenance (pooling/depooling) and it is very prone to cause human error.
ie: "oh that IP isn't in use, should be fine to delete"
Ideally we would like to replace them by something like:
$wmgParserCacheDBs = [
'pc1' => '10.192.0.104', # pc2007, A1 4.4TB 256GB
'pc2' => '10.192.16.35', # pc2008, B3 4.4TB 256GB
'pc3' => '10.192.32.10', # pc2009, C1 4.4TB 256GB
# 'spare' => '10.192.48.14', # pc2010, D3 4.4TB 256GB # spare host. Use it to replace any of the above if neededWe are not sure though about what cause:
- Will that generate a miss as soon as they get changed in config?
- Will that break something else mediawiki-wise?
- The old keys would need to be purged manually after $retention_period probably?