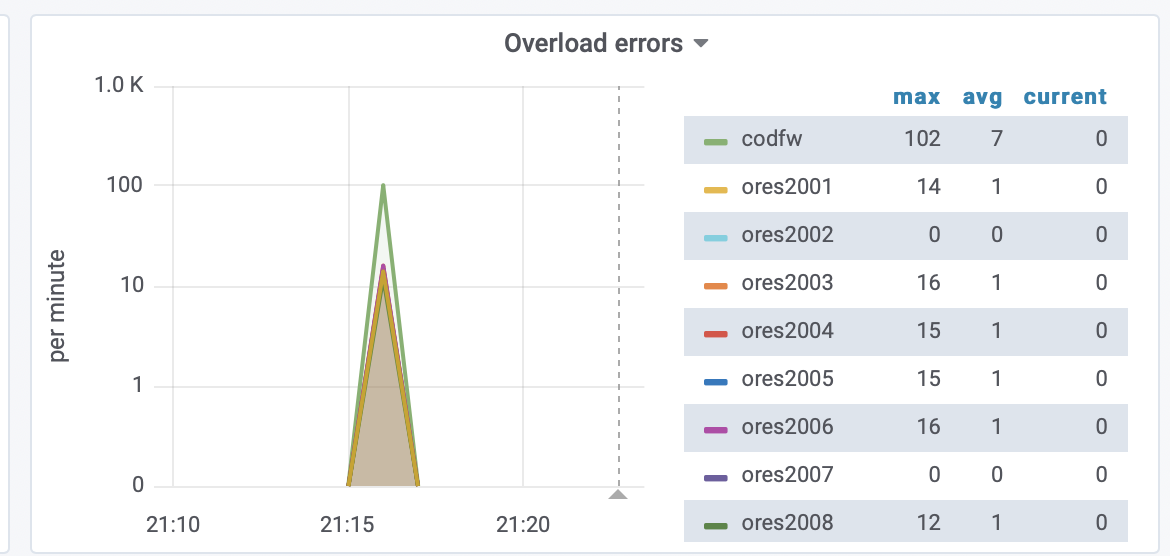
Since the services are promoted one machine at a time, it doesn't make sense that we would see overload errors. Nonetheless:
| awight | |
| Jan 7 2019, 9:24 PM |
| F27816066: Screen Shot 2019-01-07 at 1.24.36 PM.png | |
| Jan 7 2019, 9:24 PM |
Since the services are promoted one machine at a time, it doesn't make sense that we would see overload errors. Nonetheless:
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Resolved | • Pchelolo | T214982 Investigate precaching blip (ChangeProp?) during Jan 30th ORES deployment | |||
| Open | None | T213116 Document delay between canary and continued deployment to minimize overload during restarts |
Maybe this is because scap is restarting the services in serial, but not accounting for the long warm-up period for each box. We could add a hard-coded delay between boxes.
There's another issue to consider, that scap can only be configured to check one of our two services, I think it's currently checking the uwsgi service rather than the celery worker. Ideally, we could have scap wait until warm-up is complete before moving on to the next box.
Several notes:
@akosiaris I'd like your input here. We're running into a lot of "After moving to kubernetes, none of this would matter" for some maintenance tasks. For a problem like this one, do you think it is worthwhile to invest time into our current deployment process or if it is reasonable to wait for k8s?
FWIW, I like the blue/green deployment strategy. I don't know if we could handle the routing component of that, but I would be very interested in at least parallel deployments to half the cluster at a time.
That is a good question. Note that whatever work in poured directly into scap (like updates to checks.sh) is going to be tossed. Work that enables scap to do things (like the HTTP readiness endpoint I suggest below) will be useful in the kubernetes environment as well, so it would be worthwhile.
Note that the blue/green deployment strategy requires to start an entire new deployment and then cut over the traffic from old to new. It's not really currently doable in the current infrastructure.
Kubernetes will allow that, however it also allows (and defaults) a different strategy, which is rolling update. It's like blue/green but per instance. It rolls out new instances of the app in increments of 25% while checking the health of the instances (pausing if it meets an error). 25% is the default and we probably won't need to change it but here's a link to the specific API entity.
[1] https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.11/#deploymentstrategy-v1-apps
Also note that we will also support canary deployment, mostly because which of the 3 (rolling update vs canary vs blue/green) is chosen depends heavily on the software and the degree of confidence in it. This creates a lot of confusion surrounding the terms. The distinguishing factor is whether end-user traffic will make it to the new release before it's promoted. If the answer is yes, then it's canary. If no, then it's blue/green. If it happens in automated increments, then it's rolling update. There is a nice writeup in http://blog.itaysk.com/2017/11/20/deployment-strategies-defined
Or add an HTTP endpoint (say /healthz or /ready) to the component that exhibits the long warm-up (that is probably the celery worker, right?) that returns the equivalent of "No/False" if the component is not yet ready and wait until it becomes "Yes/True" before proceeding to the next one. Having such a mechanism is going to be useful in any infrastructure/deployment environment and allows orchestrating roll outs in batches.
Thanks for the blogpost @akosiaris I had a complete misunderstanding of what blue/green deployment means. What I wanted to suggest for now was to have half/one third of the nodes as canary, Basically having a rather big canary. Do you think it would work?
I am trying to understand what this would solve in the context of this task. Deploying to a larger set of nodes before proceeding? Is that the intent? Cause scap already allows for that. It's the group_size parameter. Setting to something like 3 will allow to do the upgrade in batches of 3.
I think the goal is to make sure that we don't end up restarting the cluster all at once. We want to retain some amount of capacity during the whole deployment process.
If we switch to batch sizes of 3 *and* we can ensure that the batches are fully warmed up before moving on, that should address our concerns.
We are getting overload errors because the celery workers stop consuming tasks for a moment and it takes celery about 2 minutes to go from one worker up to 90 workers so capacity slowly comes back up. The trick is to let the canary sit for 30 seconds or so before continuing. Next step here is to say this in the runbook: https://wikitech.wikimedia.org/wiki/ORES/Deployment