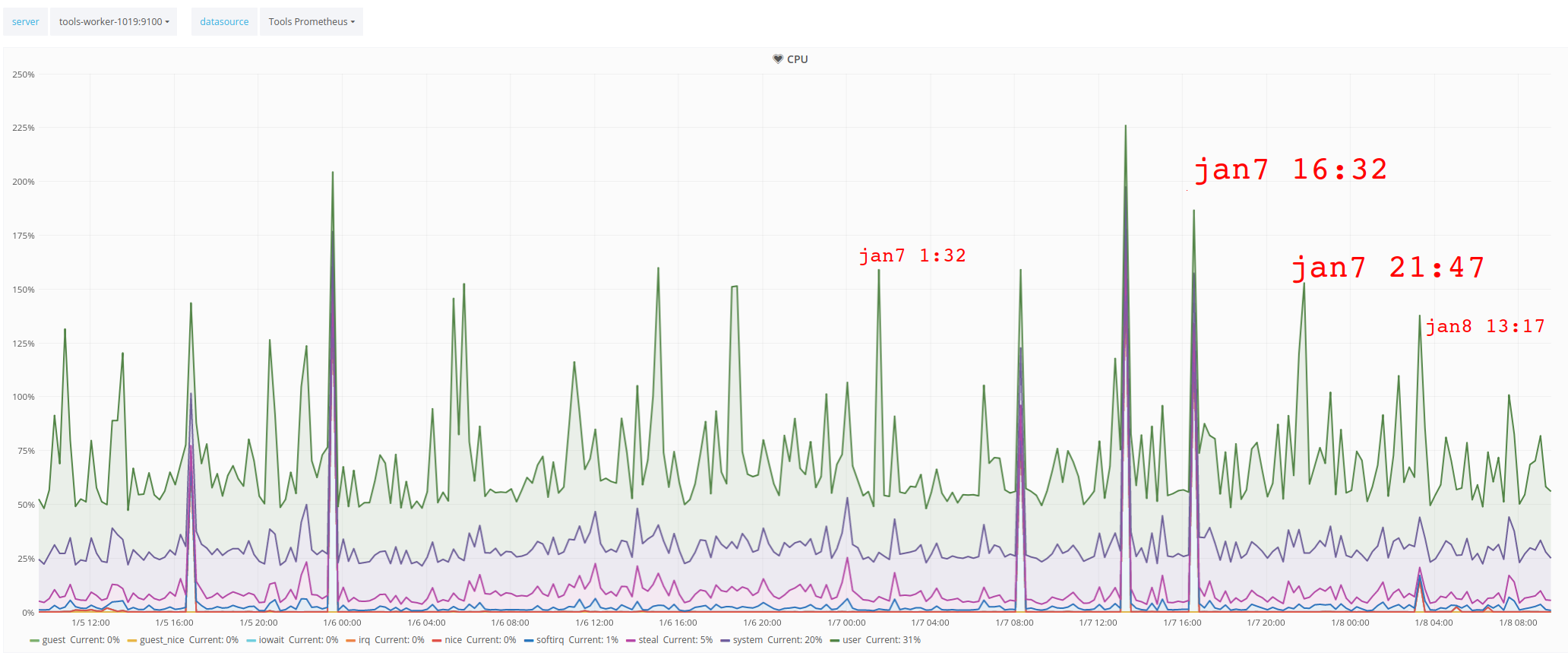
These alerts started to show up a few days ago:
2019-01-06 11:14:27,819 [1546773267] SERVICE ALERT: toolforge;Toolforge Home Page;CRITICAL;SOFT;1;CRITICAL - Socket timeout after 10 seconds 2019-01-06 11:15:17,479 [1546773317] SERVICE ALERT: toolforge;Toolforge Home Page;OK;SOFT;2;HTTP OK: HTTP/1.1 200 OK - 9896 bytes in 0.130 second response time 2019-01-06 15:05:29,587 [1546787129] SERVICE ALERT: toolforge;Toolforge Home Page;CRITICAL;SOFT;1;CRITICAL - Socket timeout after 10 seconds 2019-01-06 15:06:19,136 [1546787179] SERVICE ALERT: toolforge;Toolforge Home Page;OK;SOFT;2;HTTP OK: HTTP/1.1 200 OK - 9896 bytes in 0.085 second response time 2019-01-06 18:51:29,603 [1546800689] SERVICE ALERT: toolforge;Toolforge Home Page;CRITICAL;SOFT;1;CRITICAL - Socket timeout after 10 seconds 2019-01-06 18:52:29,697 [1546800749] SERVICE ALERT: toolforge;Toolforge Home Page;CRITICAL;HARD;2;CRITICAL - Socket timeout after 10 seconds 2019-01-06 18:57:18,754 [1546801038] SERVICE ALERT: toolforge;Toolforge Home Page;OK;HARD;2;HTTP OK: HTTP/1.1 200 OK - 9896 bytes in 0.042 second response time 2019-01-07 01:37:30,673 [1546825050] SERVICE ALERT: toolforge;Toolforge Home Page;CRITICAL;SOFT;1;CRITICAL - Socket timeout after 10 seconds 2019-01-07 01:38:17,139 [1546825097] SERVICE ALERT: toolforge;Toolforge Home Page;OK;SOFT;2;HTTP OK: HTTP/1.1 200 OK - 9896 bytes in 0.024 second response time 2019-01-07 03:03:30,824 [1546830210] SERVICE ALERT: toolforge;Toolforge Home Page;CRITICAL;SOFT;1;CRITICAL - Socket timeout after 10 seconds 2019-01-07 03:04:19,412 [1546830259] SERVICE ALERT: toolforge;Toolforge Home Page;OK;SOFT;2;HTTP OK: HTTP/1.1 200 OK - 9896 bytes in 0.050 second response time 2019-01-07 08:14:29,096 [1546848869] SERVICE ALERT: toolforge;Toolforge Home Page;CRITICAL;SOFT;1;CRITICAL - Socket timeout after 10 seconds 2019-01-07 08:15:29,258 [1546848929] SERVICE ALERT: toolforge;Toolforge Home Page;CRITICAL;HARD;2;CRITICAL - Socket timeout after 10 seconds 2019-01-07 08:20:18,846 [1546849218] SERVICE ALERT: toolforge;Toolforge Home Page;OK;HARD;2;HTTP OK: HTTP/1.1 200 OK - 9896 bytes in 0.050 second response time 2019-01-07 16:30:28,834 [1546878628] SERVICE ALERT: toolforge;Toolforge Home Page;CRITICAL;SOFT;1;CRITICAL - Socket timeout after 10 seconds 2019-01-07 16:31:27,865 [1546878687] SERVICE ALERT: toolforge;Toolforge Home Page;CRITICAL;HARD;2;CRITICAL - Socket timeout after 10 seconds 2019-01-07 16:36:19,097 [1546878979] SERVICE ALERT: toolforge;Toolforge Home Page;OK;HARD;2;HTTP OK: HTTP/1.1 200 OK - 9896 bytes in 0.125 second response time 2019-01-07 21:51:29,366 [1546897889] SERVICE ALERT: toolforge;Toolforge Home Page;CRITICAL;SOFT;1;CRITICAL - Socket timeout after 10 seconds 2019-01-07 21:52:30,450 [1546897950] SERVICE ALERT: toolforge;Toolforge Home Page;CRITICAL;HARD;2;(Service Check Timed Out) 2019-01-07 21:57:19,734 [1546898239] SERVICE ALERT: toolforge;Toolforge Home Page;OK;HARD;2;HTTP OK: HTTP/1.1 200 OK - 9896 bytes in 0.093 second response time 2019-01-08 03:17:29,251 [1546917449] SERVICE ALERT: toolforge;Toolforge Home Page;CRITICAL;SOFT;1;CRITICAL - Socket timeout after 10 seconds 2019-01-08 03:18:29,638 [1546917509] SERVICE ALERT: toolforge;Toolforge Home Page;CRITICAL;HARD;2;CRITICAL - Socket timeout after 10 seconds 2019-01-08 03:23:20,035 [1546917800] SERVICE ALERT: toolforge;Toolforge Home Page;OK;HARD;2;HTTP OK: HTTP/1.1 200 OK - 9896 bytes in 0.102 second response time