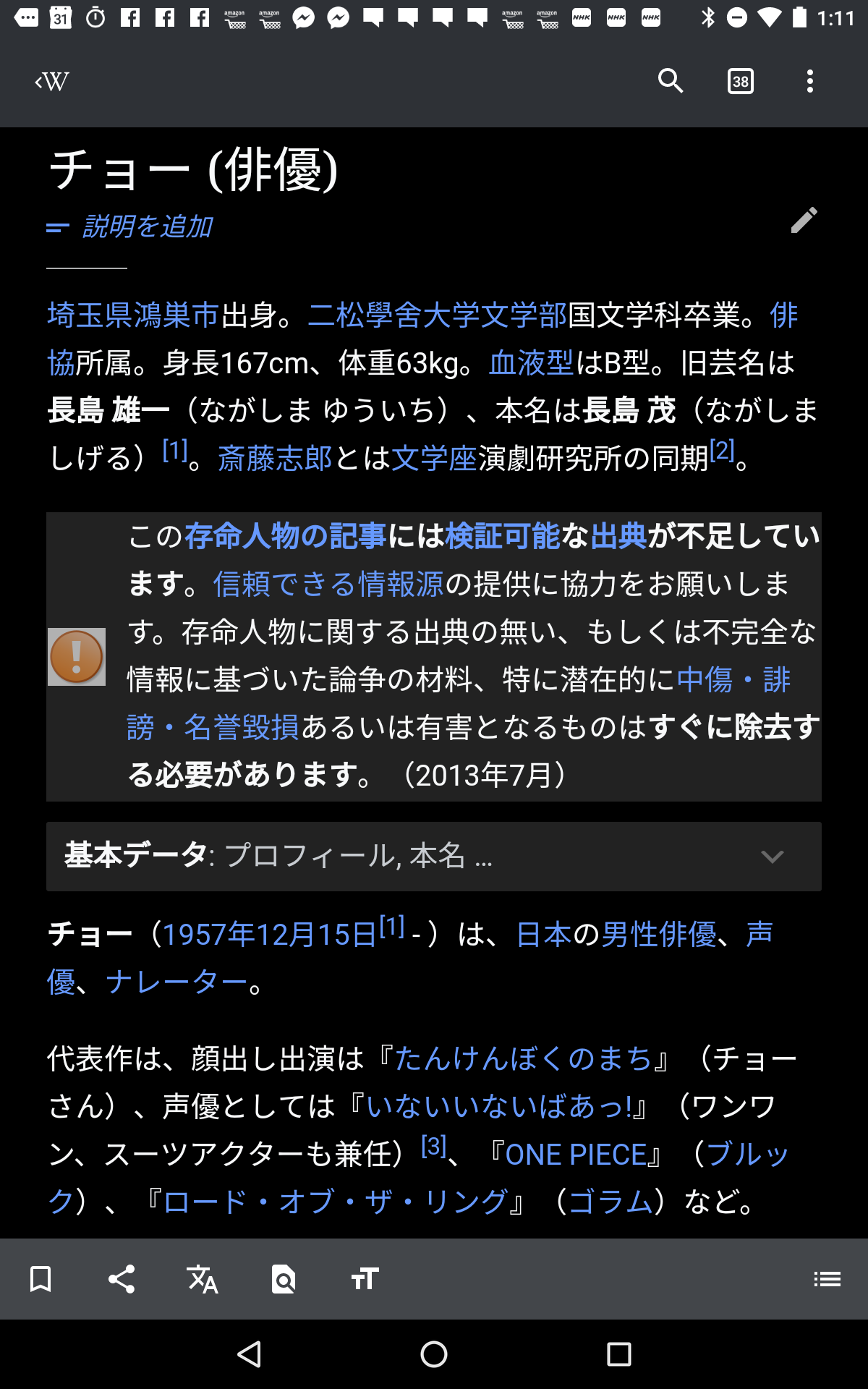
First paragraphs of some specific (ja.wp) articles come second, when viewing with iOS/Android app.
Not all articles, but for some articles (not sure what is the trigger of this phenomenon).
Occurs on:
Android app: 2.7.269-beta-2018-12-11
iOS app: 6.1.4 (1537)
Examples:
チョー (俳優)
https://ja.wikipedia.org/wiki/%E3%83%81%E3%83%A7%E3%83%BC_(%E4%BF%B3%E5%84%AA)
大阪王将
https://ja.wikipedia.org/wiki/%E5%A4%A7%E9%98%AA%E7%8E%8B%E5%B0%86
真藤順丈
https://ja.wikipedia.org/wiki/%E7%9C%9F%E8%97%A4%E9%A0%86%E4%B8%88
iOS bug example:

Android bug example: